绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
中国人民大学高瓴人工智能学院联合字节跳动开源了高质量软件工程(SWE)数据集——Scale-SWE。该项目独创了沙盒多智能体(Sandboxed Multi-Agent)协同机制,成功从 GitHub 浩如烟海的开源仓库中,挖掘并构建了高达十万级(100k)的真实 SWE 任务数据。
基于Scale-SWE 产出的蒸馏数据,团队对 Qwen3-30A3B-Instruct 模型进行了微调,并在极其严苛的 SWE-bench-Verified 评测集中斩获了 64% 的优异表现。这一结果有力地证明:同等参数量级的学术开源模型,完全有实力与 GLM-4.7-Flash 等前沿工业级大模型一较高下。

论文标题:Immersion in the GitHub Universe: Scaling Coding Agents to Mastery
论文链接:https://arxiv.org/abs/2602.09892
代码仓库:https://github.com/AweAI-Team/ScaleSWE
开源数据:https://huggingface.co/collections/AweAI-Team/scale-swe
scaffold地址:https://github.com/AweAI-Team/AweAgent/tree/main/recipes/scale_swe
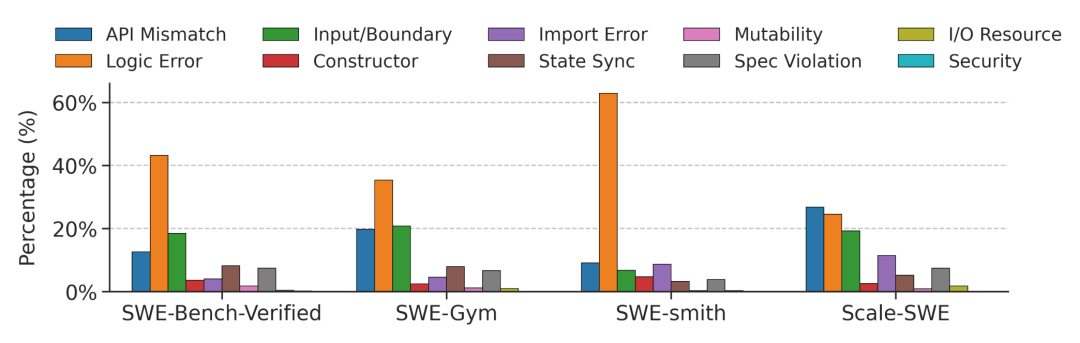
当前,为了追求SWE 数据的规模化(Scaling),业内常常倾向于利用自动化管线来生成合成数据(例如 SWE-smith、SWE-Mirror)。这种手段虽然能利用少量代码仓库迅速“膨胀”出几万条数据,但研究揭示了一个致命缺陷:合成数据的类别分布极其失衡。
正如下图所示,相比真实场景,合成数据集(如SWE-smith)的任务大都局限在简单的逻辑错误(Logic Error)层面。反观 Scale-SWE 这类真实数据集,其类别分布更加均衡且丰富,能够更贴切地还原真实世界中软件工程所面临的复杂挑战。
一直以来,构建真实的SWE 数据集存在三大“拦路虎”:复杂的环境配置、极度缺乏的单元测试、以及极易导致数据泄露的问题描述(Problem Statement)。
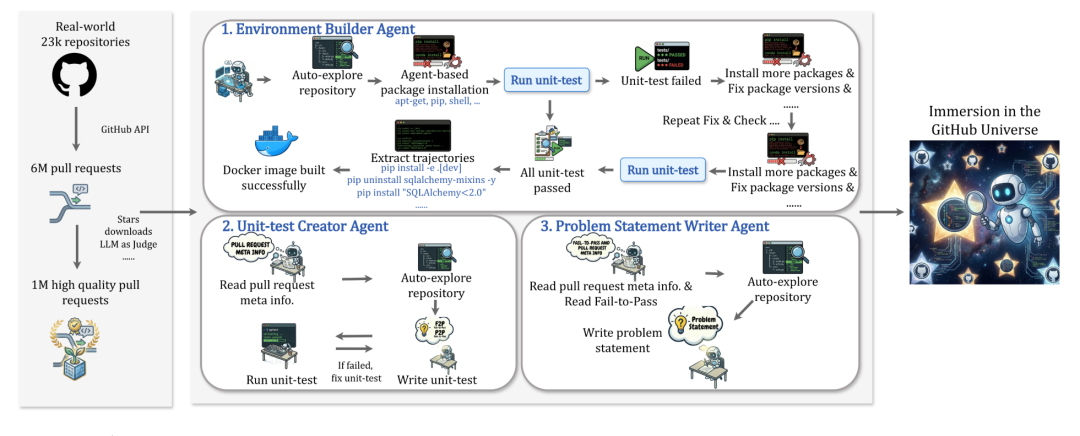
为扫清这些障碍,Scale-SWE 创新性地提出了一套基于沙盒运行的多智能体协作框架:
(1)动态环境构建智能体 (Environment Builder Agent, EBA)
以往的环境配置大多死板地依赖静态规则(比如直接跑pip install -e .),这根本无法适应 GitHub 上五花八门的真实仓库。EBA 则能在沙盒环境里自主“摸索”仓库结构,主动阅读 README.md 和 pyproject.toml 等关键文件。在进行初步配置后,EBA 还会自动触发测试脚本,并根据真实的报错信息不断试错调整,真正实现了复杂环境的自动化部署。
(2)单元测试生成智能体 (Unit-test Creator Agent, UCA)
现实中,海量高质量的Pull Request (PR) 往往并没有附带开发者编写的单元测试,导致这部分极具价值的数据在过去的研究中惨遭废弃。UCA 的出现改变了这一现状,它能根据 PR 的代码差异(Diff),全自动编写出包含 Fail-to-Pass (F2P) 和 Pass-to-Pass (P2P) 的测试代码,还能通过在不同 commit 之间切换运行,来严格检验 F2P 测试的有效性。
(3)防泄露问题描述智能体 (Problem Statement Writer Agent, PSWA)
很多PR 本身没有绑定 Issue,如果直接让大模型根据 PR 反向生成问题描述,非常容易把“Bug 位置”或“解题思路”给提前“剧透”出来。初步的消融实验证实,问题描述的质量对 SFT 后的模型表现有着近 10% 的惊人影响。
为了让描述既完整又不泄题,系统调用了指令遵循能力顶级的Gemini 3 Pro 作为驱动模型,并辅以极其严格的 Prompt 设计,确保生成的问题描述在语义上完美契合 F2P,同时杜绝任何作弊线索的混入。
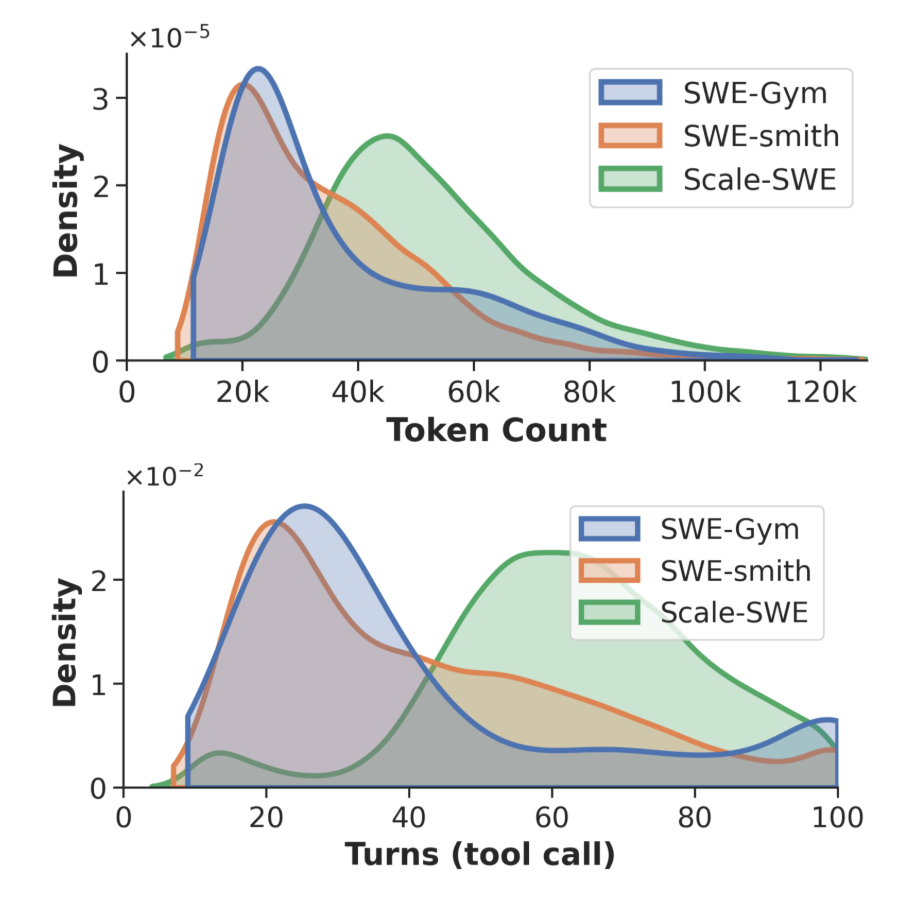
(注:蒸馏数据统计显示,在处理基于 Scale-SWE 的数据时,DeepSeek v3.2 需要消耗更多的对话轮次和 Token 数才能完成任务。这从侧面印证了Scale-SWE的问题描述并未发生答案泄露,保留了绝对的挑战性。)
03 性能评测:数据规模与质量的硬核兑现
为了检验Scale-SWE 的实战成色,研究团队借助 DeepSeek v3.2 对该数据集执行了蒸馏操作,最终收获了 71k 条成功的交互轨迹,并以此对 Qwen3-30A3B-Instruct 开展了监督微调(SFT)。实验数据证明了以下几点:
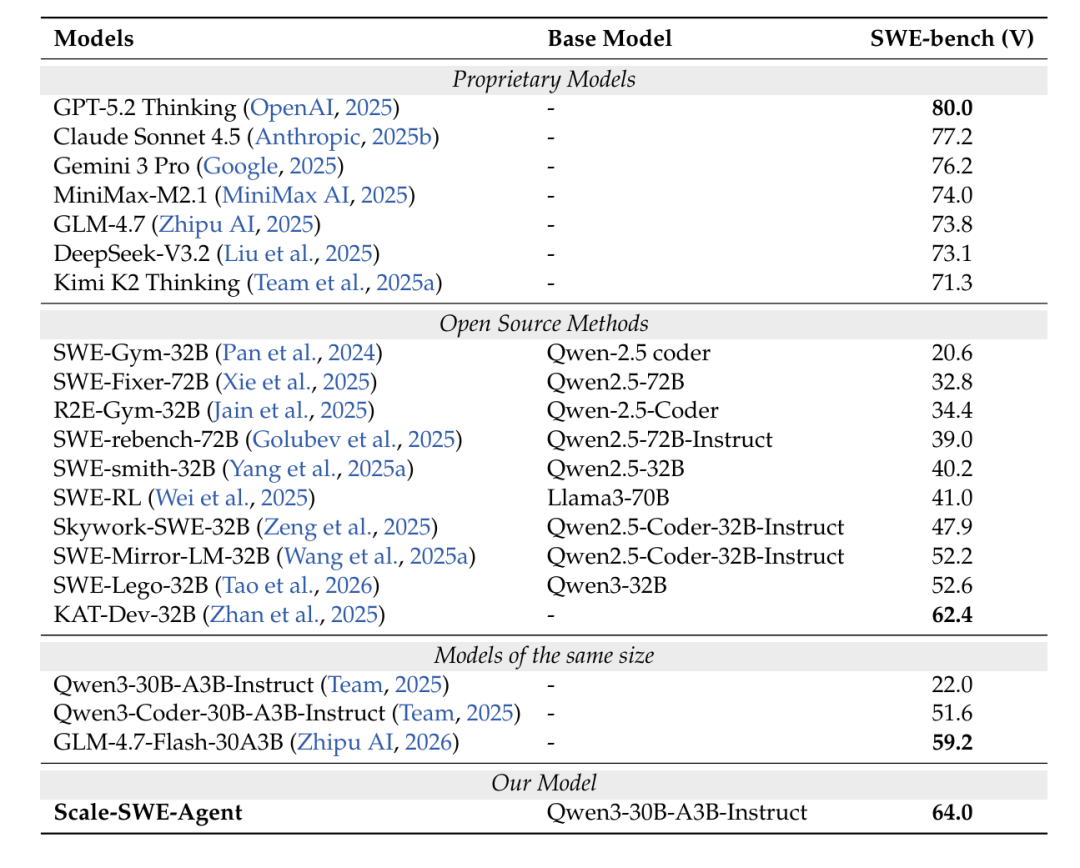
与同等体量的基座模型(Qwen3-Coder-30A3B)以及工业级代表(GLM-4.7-Flash-30A3B)相比,基于 Scale-SWE 训练的模型在性能上迎来了质的飞跃。
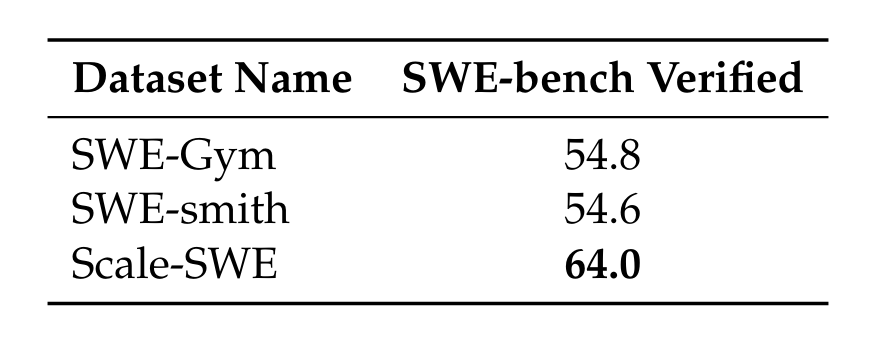
Scale-SWE Agent 相较于其基座模型 Qwen3-30B-A3B-Instruct 取得了惊人的 42.0% 的绝对提升,将通过率从 22.0% 大幅推高至 64.0%。
它的综合表现甚至压倒了 KAT-Dev-32B 以及基于 SWE-Lego-32B 等数据集微调的同类模型。
不仅如此,在相同的蒸馏流水线下横向对比:尽管SWE-smith(合成数据)的数据规模远大于 SWE-Gym,两者的表现却相差无几;而 Scale-SWE 则凭借庞大且高质量的真实数据护城河,实现了断层式的碾压领先。
Scale-SWE 的全面开源,初心是为软件工程(SWE)方向的 AI 研究夯实高质量的底层基础设施。
研究团队希望通过这批海量、即插即用的真实开源数据与高质量的蒸馏轨迹,能够实质性地降低该领域的研发门槛。