绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
如果 AI 能像人一样,看一遍做菜视频就能学会烹饪,看一次组装家具就能掌握技巧——这听起来是不是很科幻?此前 VideoWorld 通过让AI观看“合成视频”,教会了它规则与规划能力,就像一个在模拟器里练成的高手。
但问题来了:当 AI 从“游戏世界”走进“现实世界”,一切都变了。
真实视频画面千变万化,一个几分钟的任务包含无数细节。面对如此复杂的视频,VideoWorld 就像个迷路的孩子——信息太多,抓不住重点,更别说把技能用在新场景上了。
针对这个难题,字节跳动 Seed 与北京交通大学研究团队联合提出视频世界模型 VideoWorld 2,在 VideoWorld 基础上首次实现了从真实世界原始视频中直接学习可迁移知识,让 AI 真正看懂复杂、长周期任务 。
在真实手工任务中,VideoWorld 2 将长序列折纸任务成功率从 0% 大幅提升至 68.8%,生成连贯长视频,成为首个完整完成该任务的模型;在机器人领域,它从 Open-X 数据集获取可迁移操作知识,显著提升 CALVIN 任务性能,展现强大跨领域泛化能力。研究论文已被 CVPR 2026 接收,相关成果代码、数据与模型已开源。

论文标题:VideoWorld 2: Learning Transferable Knowledge from Real-world Videos
论文链接:https://arxiv.org/pdf/2602.10102v1
项目主页:https://maverickren.github.io/VideoWorld2.github.io/
Github:https://github.com/ByteDance-Seed/VideoWorld/tree/main/VideoWorld2
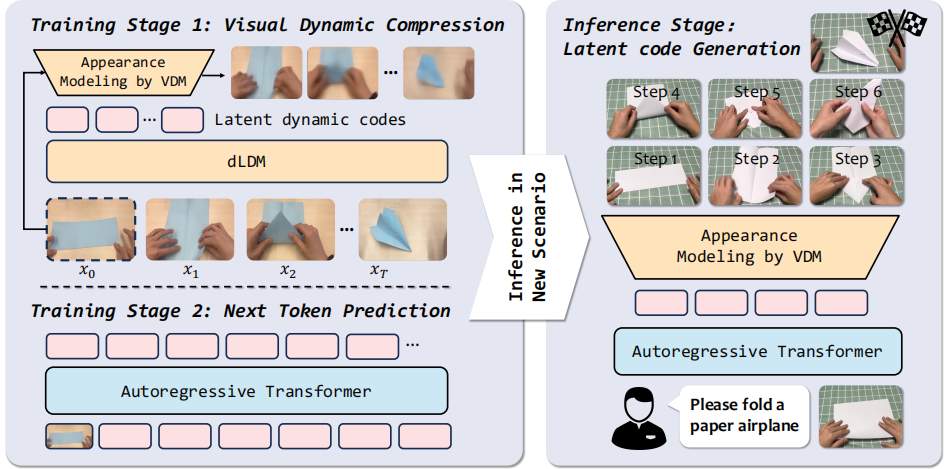
图 1 VideoWorld 2 框架
1. 从无标签视频中学习知识
生成式知识学习。视频可视为展示世界状态转移与隐含动作策略的演示轨迹。采用生成模型直接从视频中捕获这些潜在策略与动作动态,无需依赖语言标注。
形式上,该任务定义为:基于历史观测预测下一帧,从而通过视频生成过程获取任务知识,并进一步将视觉状态变化映射为具体动作,以执行下游任务。
潜在动态模型。VideoWorld 引入潜在动态模型(LDM),如图 2 左所示,将未来视觉变化压缩为紧凑潜码,以捕获多步动作的运动模式。LDM采用因果编解码结构:编码器提取视频特征,可学习查询经交叉注意力捕获变化信息并生成量化潜码;解码器基于初始帧与量化潜码因果重建后续帧,通过最小化重建误差优化。
2. 动态增强型潜在动态模型
VideoWorld 直接迁移至真实世界时泛化能力不足,面对新场景常出现场景漂移与错误动作。其根源在于动作动态与视觉外观解耦不彻底。
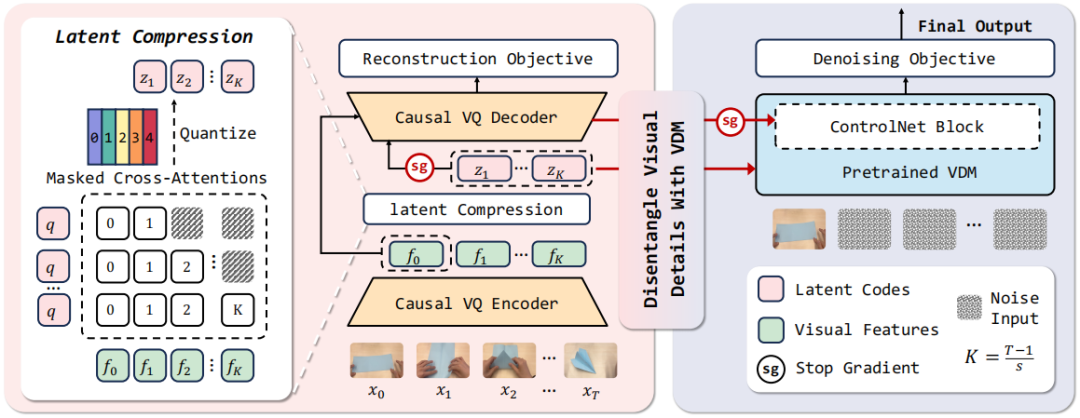
图 2 动态增强型潜在动态模型(dLDM)。(左)VideoWorld 中的潜在动态模型。(右)VideoWorld 2 提出的 dLDM。
为此研究团队提出动态增强型潜在动态模型(dLDM),如图 2 所示。其核心是将原 LDM 的解码器替换为预训练视频扩散模型(VDM),利用 VDM 的高保真重建能力处理外观建模,使LDM编码器与可学习查询专注于捕获任务相关的视觉变化。
如图 2 右所示,dLDM 采用因果 VQ-VAE 编码视觉变化为离散潜码,由预训练VDM重建高保真帧。潜码通过交叉注意力注入 VDM,使其专注外观建模,潜码则聚焦任务动力学。VDM 采用因果注意力确保时间一致性。
为规避直接生成带来的运动误差,复用 VQ-VAE 解码器将潜码转为低保真运动线索(如手部位移),引导 VDM 生成。
自回归建模。 提取潜码后,使用自回归 Transformer 以初始帧和任务指令为条件建模其序列,使模型掌握复杂任务的长期模式。
为评估模型从真实世界视频中学习长时任务知识的能力,构建了 Video-CraftBench 。数据集包含第一人称视角的手工制作视频,涵盖折纸(飞机、船)与积木搭建(塔、马、人)五项任务。
数据集共约 7 小时(9.5k 片段),折纸任务时长 40-80 秒,积木任务 20-30 秒。测试集含 150 个独立视频,背景、纹理、布局均不同于训练集,用于评估泛化性。
评估工作从动作准确性与视觉质量两个维度展开:
序列任务成功率:将折纸任务分解为 7 步,以 DINOv2 分类器检测步骤完成(忽略外观),基于首帧生成 3 条视频,前置步骤完成方计成功;积木任务仅验证最终状态。
视觉质量:采用 LPIPS 与 SSIM 指标评估生成帧的逼真度及与输入帧的一致性。
在两个基准上评估 VideoWorld 2:Video-CraftBench 衡量真实长程任务学习能力;在机器人任务中,于 OpenX 数据集训练潜表示,并测试向 CALVIN 的迁移。CALVIN 含 34 项任务,采用 5 步序列依赖评估。
1. Video-CraftBench 上的结果
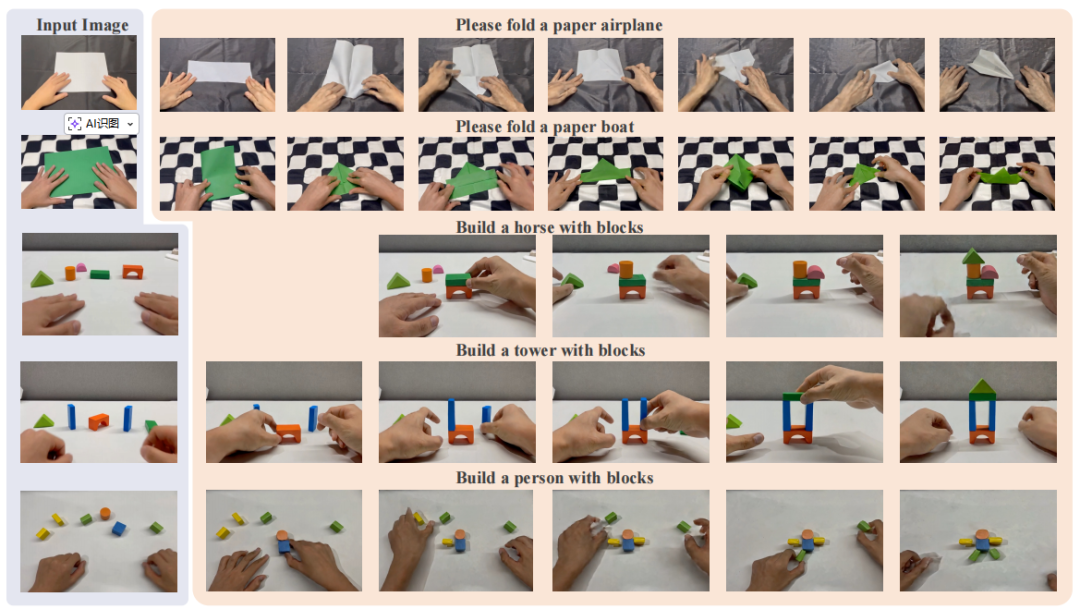
图 3 定性结果。VideoWorld 2 能够学习可迁移知识,并在未知环境中生成长时视频。该图展示了在长时手工任务上的生成结果。
仅使用 Video-CraftBench 训练:如表 1 所示,VideoWorld 2 在测试环境中生成了完整连贯的任务序列。仅基于 Video-CraftBench 训练,无需大规模潜码预训练,即可在折纸与积木堆叠任务上分别达到 68.8% 和 81.5% 的成功率。
这表明 dLDM 能有效提取核心动作信息并过滤无关视觉变化,从而泛化至未见环境。同时,得益于 VDM 的外观先验,VideoWorld 2 生成的视频在 SSIM 与 LPIPS 指标上亦更优(如图 3 所示)。
表 1 Video-CraftBench 上的对比结果。其中,“Craft-text”表示使用了逐步文本描述。
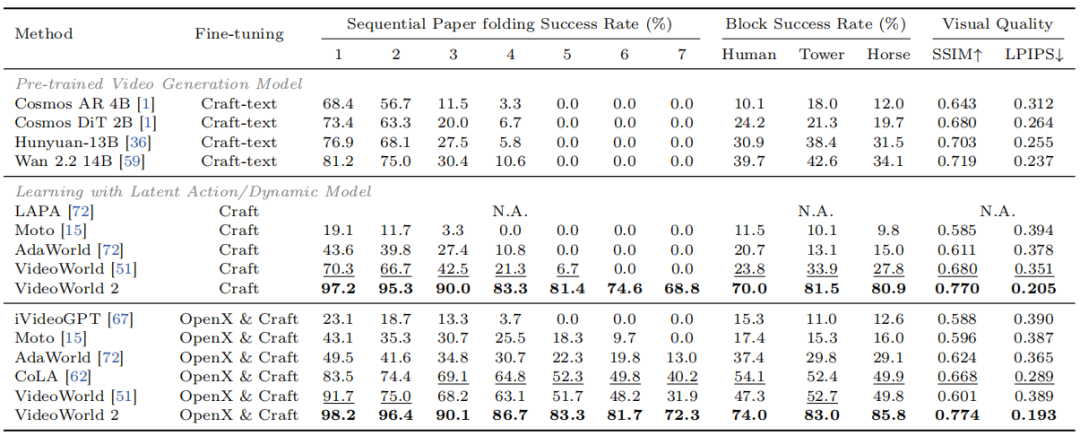
使用 OpenX 进行数据扩展:进一步评估潜码能否从大规模数据中获益。引入包含多样化机器人智能体与环境外观的 OpenX 数据集,检验 VideoWorld 2 在扩展动作提取能力的同时过滤无关因素的能力。
如表 1 所示,VideoWorld 2 在强基线基础上进一步提升:折纸任务最终步骤成功率达 72.3%,积木堆叠达 85.8%。如图 4 右图所示,OpenX 与 Video-CraftBench 中相似的潜码对应相似运动模式的视频,验证了其跨智能体与场景的迁移能力。

图 4 具有相似潜在动态特征的视频片段。下方文本表示动态类型。
2. CALVIN 上的结果
域内潜码预训练。 为验证潜码对操作技能学习的有效性,参照 LAPA 进行潜码预训练实验:先在 22k 条 CALVIN 轨迹的潜码上预训练自回归 Transformer,再仅用 2k 条真实动作标签微调。如表 2 所示,该策略显著提升了 VideoWorld 2(Idx 4)在长时任务上的性能,且已接近使用全部 22k 标签训练的模型(Idx 1),展现出较高数据效率。LAPA(Idx 3)虽也从中获益,但表现仍不及 VideoWorld 2,凸显了所提潜码的优势。
表 2 在 CALVIN 基准上的对比结果。其中,“10% 数据”表示从 ABCD→D 训练集中随机采样的 2k 条轨迹。“Oracle”表示使用真实动作标签作为监督直接训练 Transformer。
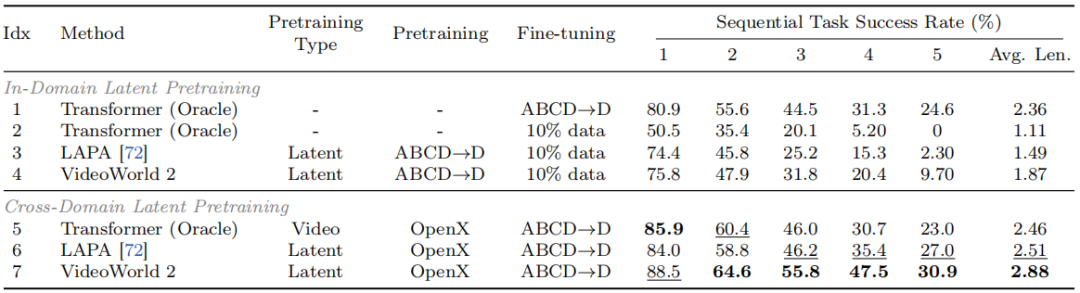
跨域潜码预训练。 进一步在 130 万条 OpenX 数据集上预训练,并在 22k 条 CALVIN 轨迹上微调以评估迁移能力。结果如表 2 所示,相较于仅用有标签 CALVIN 数据训练(Idx 1),该预训练显著提升了 LAPA(Idx 6)与 VideoWorld 2(Idx 7)的成功率,且 VideoWorld 2 在长时任务上获益更多。对比在 OpenX 上预训练的视频下一 token 预测基线(Idx 5),所提潜码预训练效果更优,验证了其作为一种比直接视频预训练更高效的知识迁移范式。










