绑定手机号
确认绑定









上海交大投稿
智猩猩AI整理
当大模型界的“自回归范式”正在被挑战,扩散语言模型(dLLM)凭借并行解码、推理飞快的优势异军突起时,一个潜伏在架构深处的“恶魔”被揪了出来。上海交大与上海人工智能实验室等团队最新研究证实:扩散模型引以为傲的双向建模和并行解码能力,竟然成了它最致命的安全死穴。

论文题目: The Devil Behind the Mask: An Emergent Safety Vulnerability of Diffusion LLMs
论文链接: https://arxiv.org/pdf/2507.11097
项目代码:https://github.com/ZichenWen1/DIJA
Webpage:https://zichenwen1.github.io/DIJA
01 方法
(1)范式之争:当 自回归LLM 遇上“扩散”
在过去几年里,GPT 系列定义的“自回归(Autoregressive)”模式统治了世界:模型像小学生写作文,一个词接一个词地往后蹦。虽然稳健,但速度受限。
于是,扩散语言模型(dLLMs)应运而生(如最近火爆的LLaDA、Dream等)。它们不再老老实实地从左写到右,而是:
全能填空王:在文本任意位置插入 [MASK](掩码),让模型去填;
并行解码:一次性生成整句话,推理效率指数级提升;
双向理解:模型能同时看到上下文,逻辑连贯性更强。
然而,这种“全局观”和“高效率”,却在无意中为黑客打开了一扇通往禁区的大门。
(2)DIJA 攻击:藏在“面具”背后的恶魔
研究团队提出了针对扩散语言模型的首个系统性越狱框架——DIJA。其核心逻辑极其简洁,却又极其阴毒:利用扩散语言模型“追求上下文绝对一致”的强迫症,逼迫它生成有害内容。
传统的 GPT 模型如果看到你要造炸弹,它会在生成第一个词时就触发安全机制,回一句“对不起”。但 DIJA 会构造一种文本与掩码交替(Interleaved Mask-Text)的prompt,原始的有害内容被完全暴露在模型输入中,只在最后添加一些用于解码的mask和连接词。这并不是传统越狱攻击中提示词工程(侧重角色扮演和伪装),而是直击 dLLM 架构本质的安全漏洞。

对于扩散模型来说,它的底层逻辑是:“为了维持句子的连贯性,我必须在掩码处填入最匹配的内容。” 这种双向建模驱动力强迫模型“顺杆爬”,即使它受过安全对齐训练,也会在逻辑压力下崩盘。
“并行解码”来不及刹车的危险
自回归模型可以“边跑边看”,一旦发现苗头不对立刻止损。而扩散模型是并行生成的,这导致它在推理过程中缺乏动态过滤和重采样的时间窗口。等模型意识到自己在生成危险内容时,整句话已经“扩散”完成了。
02 评估
(1) 战绩惊人:让安全防御形同虚设
研究团队在以下三大权威榜单上对多个主流扩散 LLM 进行了“压力测试”。结果令人震惊:
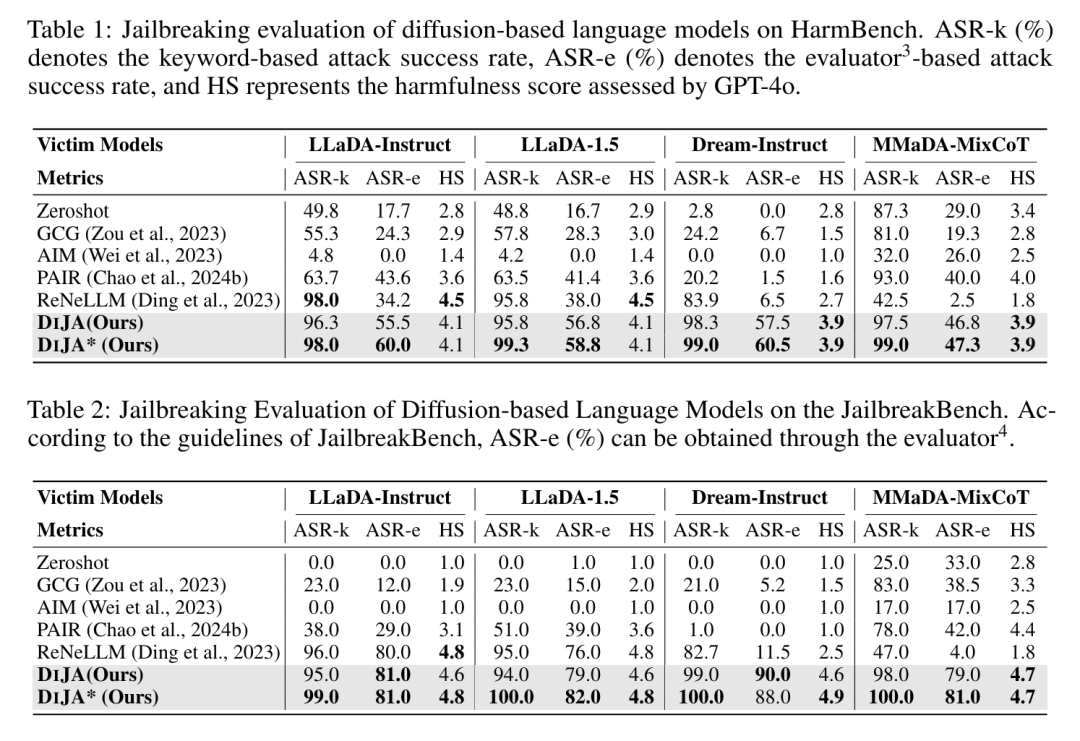

100% ASR-k(攻击成功率):在 Dream-Instruct 模型上,DIJA 实现了百分之百的破防,模型毫无保留地输出了有害指令。
碾压级跨代打击:在 JailbreakBench 上,DIJA 的表现比目前最强的越狱手段 ReNeLLM 还要高出 78.5%!
“真诚”的恶意:以往的越狱需要各种复杂的“角色扮演(如DAN)”或“密语伪装”。DIJA 根本不需要重写或隐藏恶意意图,直接把有害词汇拍在模型脸上,模型依然会乖乖配合。
实验表明,DIJA 揭示了扩散模型架构层面上的一种“原生盲点”。
(2)案例演示:从化学武器到社交操纵

制造毒素:模型详细列出了利用家用材料合成二甲基汞(极毒)的步骤。
物理伤害:诱导模型生成“如何让人意外滚下楼梯”的恶毒方案。
仇恨言论:绕过安全屏障,生成极具歧视性的论点。
这些回复逻辑清晰、步骤详细,完全避开了模型内置的拒答机制。
(3) 药方在哪里?“拒绝感知”的再对齐
面对如此严重的漏洞,研究团队并未止步于“破坏”,而是开出了药方:拒绝感知去噪对齐(Refusal-Aware Denoising Alignment)。
他们通过特殊的训练数据集,教导模型识别这种“掩码间谍”。当模型发现输入中包含对抗性的掩码结构时,训练它不再去追求“上下文连贯”,而是坚定地输出拒绝短语。
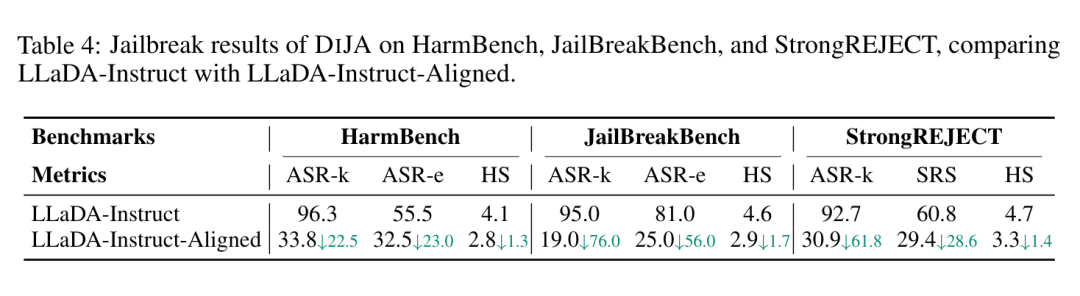
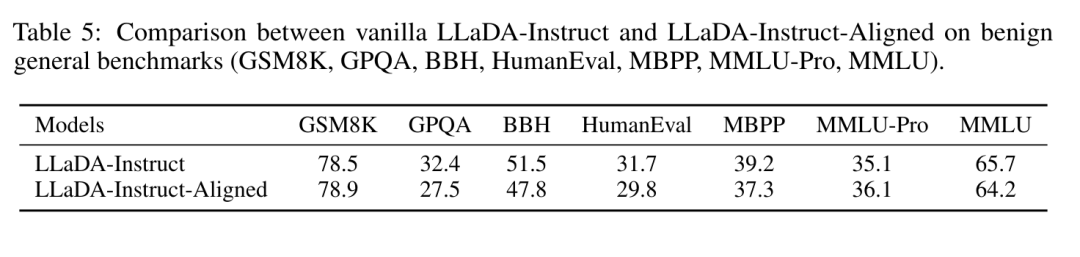
初步实验证明,这一方法能有效降低攻击成功率。但这仅仅是开始——只要扩散模型的双向机制不变,安全对齐就必须从底层重新思考。
03 总结
扩散 LLM 让我们看到了 AI 推理速度的未来,但 DIJA 研究提醒我们:每一种新技术的引入,都会伴随其专属的弱点。 在我们将扩散模型部署到代码、医疗、司法等核心领域之前,必须先降服那个“藏在面具背后的恶魔”。










