绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
当前大语言模型(LLMs)在代码生成任务上的评估依赖静态基准(如 HumanEval、SWE-Bench),仅验证输出是否通过预设单元测试,忽略了完整的持续集成(Continuous Integration,CI)流程及其自动化保障机制在专业开发中的关键作用。在持续集成中,开发人员将会频繁地向主干提交代码,这些新提交的代码在最终合并到主干前,需要经过编译和自动化测试流进行验证。当前简化的评估难以反映LLM在复杂、动态的真实开发环境中的综合能力,导致评估结果与实际表现脱节。
为此,香港大学联合加州大学洛杉矶分校、清华大学等提出了一个面向LLM的竞技评估框架 SwingArena ,高度还原了真实世界的软件开发工作流。与传统的静态基准测试不同,在 SwingArena 中 LLM 分别扮演成提交者(生成代码补丁)与评审者(编写测试用例并通过 CI 流程验证补丁)的角色,模拟了软件迭代的协作过程。为支持此类交互式评估,研究团队引入检索增强代码生成(RACG)模块。该模块从大型代码库中提取语法与语义相关的代码片段,有效应对长上下文挑战,并支持多种编程语言(C++、Python、Rust 和 Go)。研究团队从 2300 个 GitHub Issue 中精心筛选出的 400 多个高质量真实问题用于评估。结果表明,GPT-4o 在激进补丁生成(aggressive patch generation)上表现突出,而 DeepSeek 和 Gemini 则更注重 CI 验证的正确性。该成果成功入选 ICLR 2026 Oral。

论文标题:SWINGARENA: Competitive Programming Arena for Long-context GitHub Issue Solving
论文链接: https://arxiv.org/pdf/2505.23932
GitHub: https://github.com/menik1126/Swing-Bench
数据集: https://huggingface.co/SwingBench/datasets
01 方法
持续集成(CI)是在源代码变更后自动检测、拉取、构建和(在大多数情况下)进行单元测试的过程。持续集成的目标是快速确保开发人员新提交的变更是好的,并且适合在代码库中进一步使用。CI的流程执行和理论实践让我们可以确定新代码和原有代码能否正确地集成在一起。
正因CI系统在现代软件工程中扮演着“质量守门人”的关键角色,SwingArena将其完整流程转化为一个竞技评估环境,从而对LLM的代码修复能力进行更真实、更严格的检验。
SwingArena的方法体系由三部分构成:高质量数据构建、对抗性竞技场设计,以及检索增强代码生成(RACG)模块。
(1)高质量数据构建
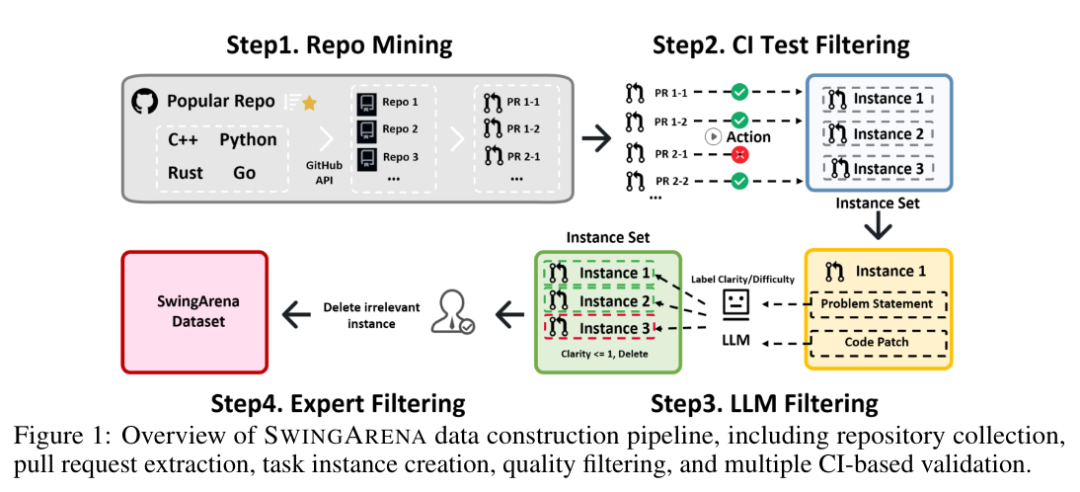
如图1所示,SwingArena 的数据构建流程包含多个阶段:
代码仓库挖掘(Repository Mining)
通过GitHub API筛选高质量代码库,优先选择具有较高人气(例如星标数量)的仓库,以此作为代码质量和社区认可度的代理指标,被合并到此类仓库中的补丁和单元测试通常经过了大量专家审查,因此更有可能是正确的。
针对每个入选仓库,收集元数据(如许可证、分支数、活跃度)并克隆符合预设标准的项目。从中提取与对应问题(Issue )关联的真实拉取请求(PR),包括代码差异(diffs)、补丁内容及相关元数据。接着,将原始 PR 数据转换为结构化的基准任务实例:从PR描述和相关问题中提取任务说明,同时收集关联补丁和可用测试用例。
每个任务均补充了上下文元数据(如仓库ID、基础提交 SHA、补丁内容、时间戳及CI配置列表),从而能够支持对LLM的性能进行贴近现实且细粒度的评估。
研究团队收集了Rust、Go、C++ 和 Python 四种编程语言的数据,因为这些语言在开源生态中广泛使用且具备成熟的CI工具。
CI测试过滤(CI Test Filtering)
完成代码仓库挖掘后,为每个拉取请求集成对应的CI配置(包括GitHub Actions、Travis CI 等),以完整复现真实世界中端到端的软件开发流程,包括各仓库特定的测试与构建要求。仅保留通过全部CI检查的实例,确保其满足项目特定质量标准,并优先选择具有已验证测试覆盖的实例。
大语言模型过滤(LLM Filtering)
为提升数据集质量并平衡任务难度,采用LLM-as-a-Judge对每个拉取请求的问题描述清晰度及其整体难度进行评估。所使用的模型(Grok-3-beta)需为其清晰度与难度评分提供依据,确保每项评估均有可追溯的依据,便于后续专家验证。
专家过滤(Expert Filtering)
在 LLM-as-a-Judge 评估之后,人类专家对模型生成的评分进行最终审核与校准。标注人员会审阅清晰度和难度分数以及模型提供的评估依据,对结果予以确认或修正。若模型的评估理由模糊不清或与实际问题不符,专家将介入干预以确保标签的一致性与准确性。此步骤有效缓解了LLM可能出现的幻觉问题,并过滤掉低质量的问题描述、逻辑不连贯的实例,以及包含已失效或无法访问的多模态附件的任务。
(2)对抗性竞技场设计(Arena)
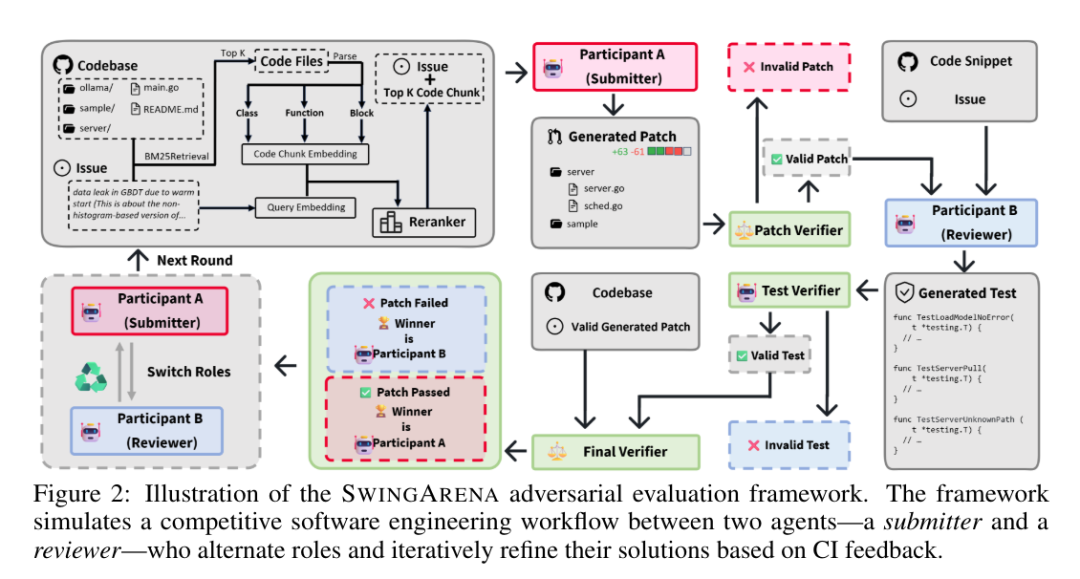
SwingArena支持模型在一系列编程任务中进行直接竞争。与专注于静态代码片段补全或单一单元测试的传统基准不同,SwingArena构建了一个动态交互式的环境,以模拟真实世界的软件开发工作流。
SwingArena框架复现了代码变更的提交与评审过程:一个模型扮演提交者(submitter),提出候选解决方案;另一个模型则担任评审者(reviewer),对提交内容进行评判,并生成额外的测试用例,以暴露潜在缺陷或边缘情况。这种交互式设置精准还原了人类在软件开发中的协作模式,从而支持从多个维度对模型进行更丰富的评估,包括推理深度、代码鲁棒性以及协作能力。
(3)检索增强代码生成(RACG)
真实世界的编程任务通常需要在多文件的代码库中进行推理,而相关上下文往往分散在数千行代码。尽管先前的研究尝试通过基于抽象语法树(AST)的解析方法来应对 Python 中的长上下文挑战,但这些方法缺乏对多编程语言检索的支持,也未引入重排序机制以精确控制 token 预算。
为解决上述局限,SwingArena 引入了一种支持多语言的RACG框架,该框架结合了静态代码分析与稠密检索技术,高效地提取、排序并向模型提供相关的代码片段。
文件检索器(File Retriever)
在文件检索阶段,SwingArena 采用一种由粗到细的过滤策略,通过轻量级的 FileRetriever 组件实现。该组件使用经典的稀疏检索方法 BM25,将问题描述视为查询(query),将每个源文件视为文档(document),并基于词汇相似度对文件进行排序。此步骤可提前剔除无关文件,缩小搜索范围,从而提升后续稠密检索的效率。BM25 排名前 k 的相关文件会被传递至 CodeChunker。
代码分块器(CodeChunker)
SwingArena 通过 CodeChunker 采用一种分层且语法感知的分块策略,将代码库分解为函数、类、代码块等语义单元,在保留代码结构完整性的同时提升检索精度。它通过语言特定的解析规则,支持多种编程语言,包括 Rust、Python、C++ 和 Go。当解析不可用时,系统会回退到针对该语言定制的正则表达式启发式规则,确保在多样化代码库中的鲁棒性。
代码重排序器(CodeReranker)
真实代码库中有大量的候选分块。为此,SwingArena 采用 CodeReranker,在模型上下文窗口受限的情况下优先处理最相关内容。该模块利用 CodeBERT 将问题描述和代码块分别编码为稠密向量,并通过余弦相似度进行排序,以识别最相关的代码片段。为适应有限的上下文长度,仅选取排名最高的若干代码块纳入最终输入。
面向 Token 预算的上下文管理
为在严格的 token 限制下优化资源使用,SwingArena 采用一种动态 token 预算机制:逐步选择并打包代码块,直至达到预设的 token 阈值。关键在于,它可根据可用上下文窗口大小调整分块粒度 —— 空间充足时优先使用粗粒度分块,预算紧张时切换为细粒度分块。每个被选中的代码块均附带丰富的元数据,包括文件路径、代码类型、函数名和行范围,为模型提供结构清晰、高质量的上下文,同时确保 token 的高效利用。
02 评估
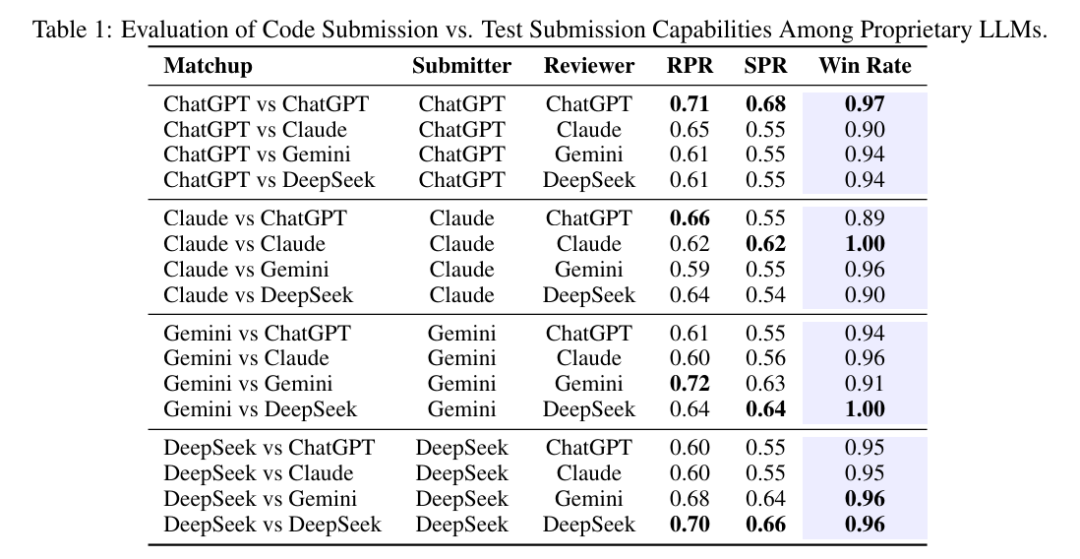 注:表格中的ChatGPT是GPT-4o
注:表格中的ChatGPT是GPT-4o
表 1 展示了在 SwingArena 竞技框架下,对专有大语言模型进行的 RPR与 SPR对比分析。每个模型均在自对战(如 GPT-4o 对战 GPT-4o)与跨对战(如 Claude 对战 Gemini)两种场景下进行测试,交替扮演提交者与评审者角色。评估结果呈现以下趋势:
i) 强自一致性:所有模型在评审自身提交内容时均展现出极高胜率 ——Claude(1.00)、GPT-4o(0.97)、Gemini(0.91)、DeepSeek(0.96),表明其在补丁生成与测试用例生成环节具备高度的内部一致性。
ii) GPT-4o的激进补丁优势:无论面对何种评审者,GPT-4o作为提交者时胜率均≥0.90,凸显其在生成具备竞争力的补丁方面的主导地位。然而,其相对较低的 RPR/SPR 分数(例如,相较于 Claude 的 0.65/0.55)表明其整体正确性存在一定波动。
iii) DeepSeek 与 Gemini 的可靠性:尽管作为提交者时胜率略低,但 DeepSeek 与 Gemini 实现了最高的 CI 通过率(分别高达 0.66 与 0.64),反映出二者在生成可稳定通过测试的代码方面的优势。
iv) 对战不对称性:两两对战结果显示出轻微的不对称性(例如,GPT-4o对战 Claude 为 0.90,而 Claude 对战 GPT-4o为 0.89),表明评审模型会对结果产生细微影响,这很可能源于不同模型评审严格度的差异。
总体而言,GPT-4o在生成果断有效的补丁方面表现卓越,而 DeepSeek 与 Gemini 则更注重代码正确性与CI的稳定性。
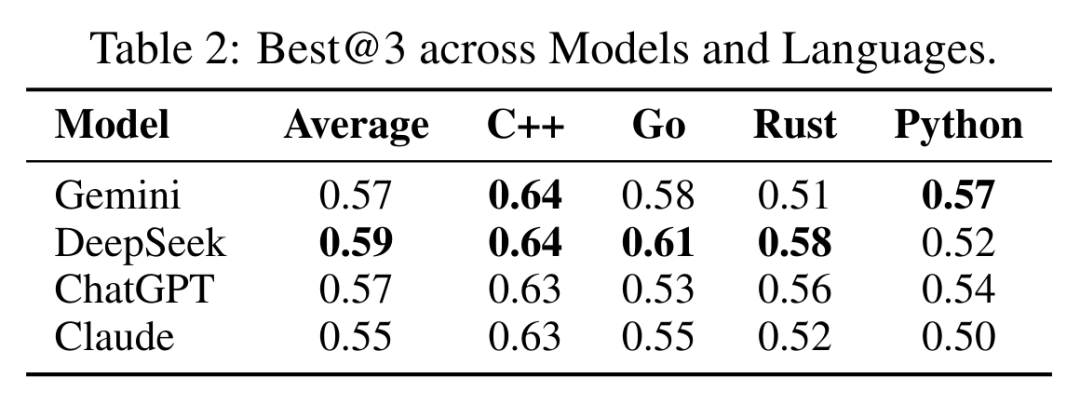
注:表格中的ChatGPT是GPT-4o
除整体性能对比外,研究团队还进一步分析了各模型在不同编程语言上的表现。如表 2 所示,DeepSeek 取得了最高的平均 Best@3 分数(0.59),紧随其后的是 Gemini 与 GPT-4o(均为 0.57),以及 Claude(0.55)。
按语言细分来看,所有模型在 C++ 上表现最佳,而在 Rust 与 Python 上表现相对较差,这表明模型在处理不同语言的特定问题时,其能力存在差异。值得注意的是,DeepSeek 在所有语言上均展现出稳定且强劲的结果,尤其在 Rust(0.58)与 Go(0.61)上表现突出,体现了更强的泛化能力。
这些结果支持了一个核心结论:在所有评估模型中,DeepSeek 展现出最为均衡且高效的多编程语言代码推理能力。
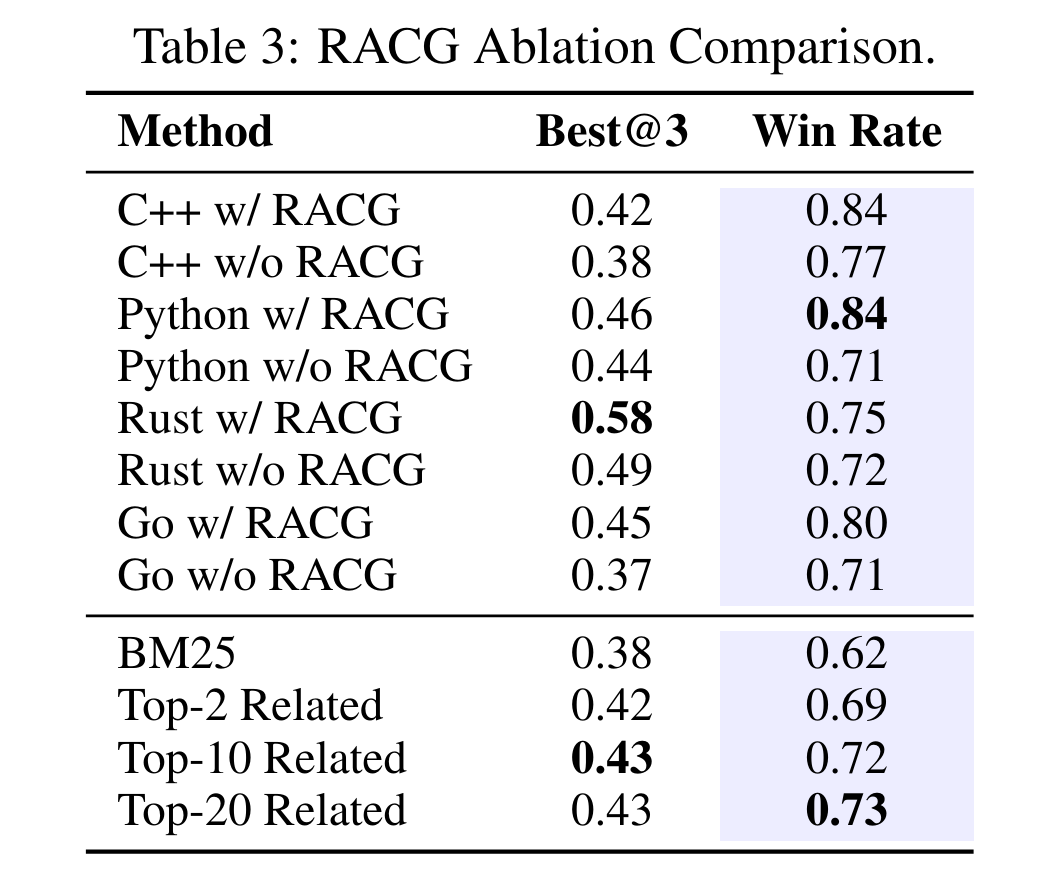
表 3 展示了基于 Qwen2.5‑Coder‑7B‑Instruct 提交者端 RACG 模块的消融实验结果。
表格上半部分呈现了四种编程语言(C++、Python、Go、Rust)的实验结果,对比了模型在启用与禁用 RACG 时的性能差异。表格下半部分则包含了基于检索的基线方法:BM25 以及 Top-k 相关检索(k=2、10、20)并进行重排序。
在所有语言中,集成 RACG 模块均能持续提升Best@3与胜率(Win Rate)。例如,在 C++ 场景下,RACG 将 Best@3 从 0.38 提升至 0.42,胜率从 0.77 提升至 0.84;在 Python、Rust 与 Go 语言中也观察到了类似的性能增益。
与纯检索方法相比,RACG 增强的方案在所有指标上均全面超越 BM25。其中,Top-20 检索取得了最强的基线结果(Best@3=0.43,Win Rate = 0.73),相较于单独使用 BM25(0.62),胜率提升了 0.11,这凸显了结构感知的上下文管理比单纯基于相似度的检索更有效。










