绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
由何恺明团队提出的 MeanFlow 作为一种新兴的强大少步生成建模框架,其完全从头训练的成功机制尚未得到充分理解。Snap 研究团队通过训练实验分析表明,MeanFlow 目标函数可自然分解为两部分:轨迹流匹配与轨迹一致性。通过梯度分析发现,这两项目标存在显著的负相关性,导致优化冲突与收敛缓慢。
基于该发现,Snap 研究团队提出了一个统一多种训练目标框架 α-Flow(AlphaFlow),将轨迹流匹配、Shortcut Model 及 MeanFlow 纳入同一框架。
在 ImageNet-1K 256×256 类别条件生成任务中,使用标准 DiT 架构从头训练时,α-Flow 在不同规模与设置下均持续超越 MeanFlow。其中规模最大的 α-Flow-XL/2+ 模型取得了基于标准 DiT 架构的最先进结果:单步推理(1-NFE)FID 分数为 2.58,两步推理(2-NFE)FID 分数为 2.15。

论文标题:AlphaFlow: Understanding and Improving MeanFlow Models
论文链接:https://arxiv.org/abs/2510.20771
代码链接:https://github.com/snap-research/alphaflow
01 MeanFlow 训练分析
2025年,由何恺明团队提出的 MeanFlow 框架在生成模型领域取得了突破性进展,其论文获选为NeurIPS 2025 Oral 报告。该框架无需预训练、蒸馏或课程学习,在单步生成建模中表现出了强大的性能。然而,MeanFlow 作为一种新兴的强大小步生成建模框架,其完全从头训练的成功机制尚未得到充分理解。
通过代数变换,原始的 MeanFlow 损失 可改写为如下等价形式:
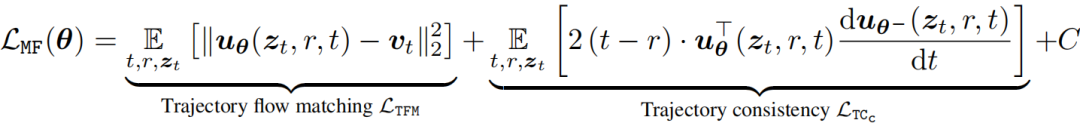
研究团队通过对 MeanFlow 进行训练实验分析,揭示了三个重要的观察结果:
可分解为轨迹流匹配 和轨迹一致性 两个目标,其梯度在训练过程中呈强烈负相关。
自身不具备必要的边界条件,这意味着 充当了其隐式边界条件。
标准流匹配损失 作为 的替代损失,但与轨迹一致性损失 的梯度冲突显著更小。
由上述分析结果引出一个关键问题:在优化 时,能否以更高效的方式优化 ,同时避免额外的计算开销?
02 统一单步、少步与多步基于流的 α-Flow 模型
1. α-Flow 损失
为解决上述问题,研究团队提出 α-Flow 损失——一个专为基于流的模型设计的新训练目标族。
定义 1. α-Flow 损失 定义如下:
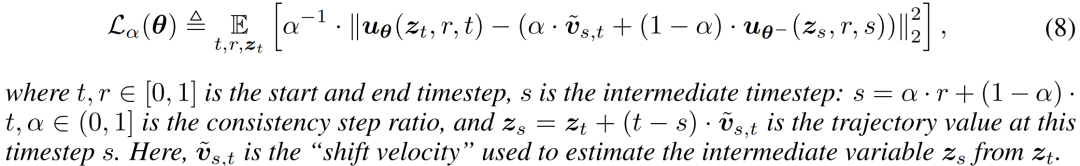
α-Flow 损失的直观展示见图 1e。其核心思想在于通过引入一个由 比例插值于 和 之间的附加时间点 ,来增强 与 之间的轨迹一致性。

图 1 多个少步扩散与流模型的训练轨迹比较
定理 1. α-Flow 损失统一了流匹配、Shortcut Models 与 Meanflow:
时,轨迹流匹配损失满足 。
时,Shortcut Models 损失满足 。
时,MeanFlow 损失的梯度满足 。
此外,若考虑一个 -参数化的网络 ,则 也包含了离散与连续一致性训练。具体而言,在设置 且 时:
对于任意 ,离散一致性训练损失满足 。
连续一致性训练损失的梯度满足 。
2. α-Flow 模型
α-Flow 损失使得一种从轨迹流匹配目标逐步过渡到 MeanFlow 目标的课程学习策略成为可能。该方法能更有效地解耦轨迹流匹配损失与一致性损失的优化过程,潜在地减少了对流匹配目标的依赖,并带来更优的收敛性。详细的课程学习过程可概括为以下三个阶段:
轨迹流匹配预训练 :为促使模型快速收敛至狭窄的 解流形,在训练初期优先优化轨迹流匹配目标。
α-Flow 过渡阶段 :当模型具备坚实基础后,训练目标开始从轨迹流匹配向 MeanFlow 过渡。
MeanFlow 微调阶段 :在最终阶段,训练完全集中于 MeanFlow 。
α-Flow 的整体训练流程如算法 1 所示:

在 α-Flow 中,当使用 损失函数(对应 的情况)时,其核心设计区别于原始 MeanFlow 方法之处主要在于以下两点:参数 的调度策略以及损失函数 本身的设计空间。
调度方案:α-Flow 训练过程的调度通过一个依赖于当前训练迭代次数 的 Sigmoid 函数实现,具体实现如算法 2 所示:

截断值:在使用固定 训练时,随着 趋近于0,单步生成性能同样先升后降。通过实验确定将调度截断值设置为 ,将 设为1。
训练目标:在 α-Flow 损失构建的统一框架下,除 Shortcut Models 使用 外,其余少步模型均设定 ,且不对 使用EMA。
自适应损失权重:其基本形式为:令 表示平方 损失,则自适应损失权重定义为 ,其中 ,加权后的损失为 。
无分类器指导(CFG):将 中的 设置为: ,其中 为引导尺度, 和 分别表示类别条件预测(类别为 )与无条件预测。
采样:对于两步生成,同时采用了一致性采样与 ODE 采样。最终方案设定为:对所有 DiT-B/2 架构采用 ODE 采样,而对所有 DiT-XL/2 架构采用一致性采样。
03 评估
研究团队在真实图像数据集 ImageNet-1K 256² 上应用 α-Flow。实验采用与 MeanFlow完全相同的 DiT 架构。评估指标采用 FID 和 FDD,并分别在 1 步与 2 步函数评估下衡量模型性能。
表 1 ImageNet-256×256 数据集上的类别条件生成。本表列出了几种从头开始训练的少步扩散/流匹配方法的实验结果。“×2”标记表示 FACM 方法每个训练周期所需计算量约为其他方法的两倍。为进行直接的“周期对周期比较”,α-Flow-XL/2、MeanFlow-XL/2 和 FACM-XL/2 均训练了 240 个周期。α-Flow-XL/2+ 是 α-Flow-XL/2 的微调版本,额外使用批次大小为 1024 的配置训练了 60 个周期。† 标记的 FID 分数是使用平衡类别采样策略评估的。
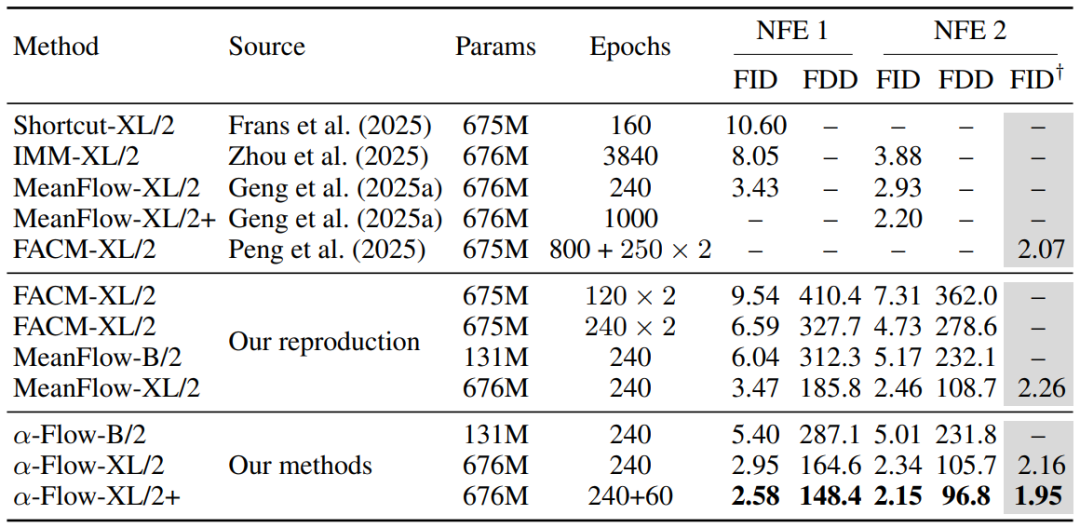
表 1 展示了 α-Flow 与此前少步扩散模型及流模型的对比结果,证明了其在 1 步与 2 步生成任务上的优越性能。在训练 240个 周期的模型中,α-Flow-XL/2 取得了 2.95 的 FID(164.6的FDD),相较于 MeanFlow-XL/2 实现了 15%(12%)的相对提升,相较于 FACM-XL/2 的提升达到 70%(60%)。最佳模型 α-Flow-XL/2+ 在 1 步生成上树立了新的最先进性能,FID 达到了 2.58(FDD 为 148.4),显著优于所有其他基于 SD-VAE 训练的少步扩散与流模型。此外,在 2 步生成任务中,α-Flow-XL/2+ 取得了 2.15的FID(96.8的FDD),同样超越了所有基线方法。特别值得注意的是,α-Flow-XL/2+ 仅用 23% 的训练周期便达到了 1.95 的FID,超越了 FACM-XL/2 在采用类别平衡采样策略下取得的 2.07 的FID。在图 2 中,α-Flow-XL/2 生成了更多高质量的图像,这些样本已用绿色框标出。

图 2 在ImageNet-1K 256² 数据集上,使用 DiT-XL/2 模型为MeanFlow与 α-Flow 生成的未筛选样本(seeds 1-8)。










