绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
DiT 推动视频生成的发展,但主流模型仍未实现实时与无限生成的能力。现有方法或依赖小容量轻量模型导致质量低,或大模型推理速度慢。其根本问题在于训练-推理时长不匹配导致的时序漂移,以及因果掩码架构对生成质量的限制。
为应对上述挑战,北京大学联合字节跳动等研究团队联合提出首个 14B 参数规模的自回归扩散模型 Helios,通过统一的输入表示原生支持文生视频(T2V)、图生视频(I2V)与视频生视频(V2V)任务。
该模型在单张 NVIDIA H100 GPU 上可实现 19.5 FPS 的实时推理,支持分钟级视频生成,同时其生成质量与强基线模型相当,甚至超越某些 1.3B 参数蒸馏模型的推理速度。目前代码、基础模型及蒸馏模型已开源。

论文标题:Helios: Real Real-Time Long Video Generation Model
论文链接:https://arxiv.org/pdf/2603.04379
项目主页 : https://pku-yuangroup.github.io/Helios-Page
01 方法
Helios框架核心设计包含三个层面:
无限生成:通过统一历史注入机制,将双向预训练模型扩展为自回归生成器,在统一框架内支持 T2V、I2V 与 V2V 任务;
高质量生成:提出简易抗漂移策略,无需自强制(Self-Forcing)或错误库(Error-Banks)即可抑制时序漂移,实现分钟级高质量生成;
实时生成:引入深度压缩流,同时压缩视觉 token 数量与采样步数,使 14B 参数模型在单 GPU 上具备实时生成能力。
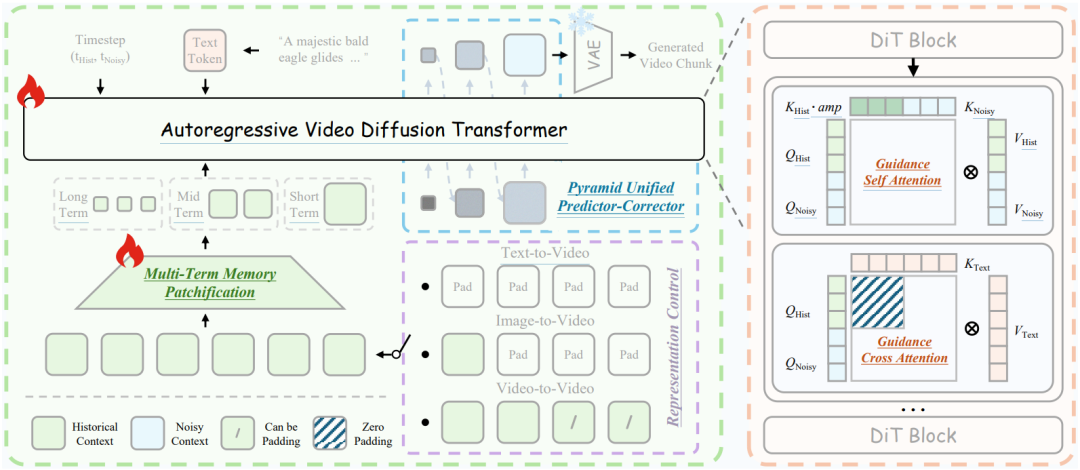
图 1 Helios架构。
1. 统一历史注入
表示控制:将长视频生成建模为视频延续任务。输入由历史上下文与噪声上下文拼接而成,历史帧数远多于噪声帧,模型以历史为条件去噪,生成时序连贯的延续内容。任务类型通过历史表示自动切换:全零为 T2V,仅末帧非零为 I2V,否则为 V2V。
引导注意力:历史与噪声上下文统计特性不同,需差异化处理:将历史时间步固定为0以保持清晰,并引入引导注意力增强其对生成的影响。
自注意力中分别计算QKV,通过按头调制的放大令牌对历史键选择性调制,聚焦判别性信息。
交叉注意力仅对噪声上下文注入文本语义,历史已融合语义,无需重复。
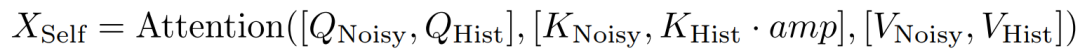
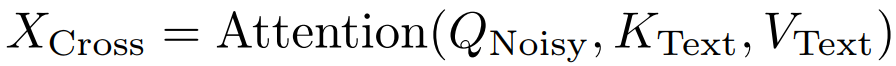
2. 简易抗漂移
针对长视频生成中的漂移问题,归纳其三种表现形式——位置漂移、颜色漂移与恢复漂移,并提出相应解决方案:
相对旋转位置嵌入应对位置漂移。限定历史上下文索引范围为 ,噪声上下文为 ,通过相对索引实现任意长度稳定生成,缓解旋转位置嵌入周期性与多头注意力的耦合。
首帧锚点抑制颜色漂移。将首帧始终保留于历史上下文中作为全局视觉锚点,约束后续片段统计量(饱和度、美学评分、RGB均值与方差)的分布偏移,稳定自回归外推下的时序一致性。
帧感知扰动克服恢复漂移。训练中模拟推理误差,对历史帧独立施加曝光调整、噪声添加或下采样上采样扰动,幅度分别从 、 与 均匀采样,且满足 。逐帧独立采样使时长为 的历史上下文对应 次独立扰动决策,显著提升模型对不完美历史的鲁棒性。
3. 深度压缩流——基于 token 的视角
为将14B视频模型的 token 计算量压缩至1.3B水平,提出深度压缩流(Deep Compression Flow),从两方面入手:
多时段记忆分块(Multi-Term Memory Patchification):基于历史信息的时间邻近性(近程主导局部运动、远程贡献全局上下文),构建分层窗口,将历史帧划分为短、中、长三时段,分别以递增的压缩比进行时空卷积压缩。总 token 数随视频长度保持恒定,在固定预算下保留更长历史,降低计算与显存开销。
金字塔统一预测校正器(Pyramid Unified Predictor Corrector):为降低含噪上下文的冗余,提出金字塔统一预测校正器——统一预测校正器(UniPC)采样器的多尺度变体,如图 2 所示。
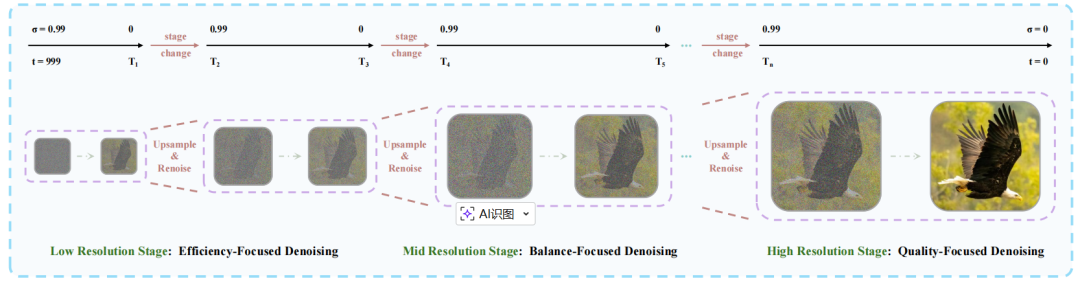
图 2 金字塔统一预测校正器的流程包含三个阶段:(i)低阶阶段侧重效率;(ii)中阶阶段兼顾质量与效率;(iii)高阶阶段优先保障质量。
针对含噪上下文,设计多尺度采样调度:早期在低分辨率潜空间采样以决定全局结构,后期逐步过渡至全分辨率细化细节。训练时划分多个分辨率递增阶段,通过线性插值路径学习跨尺度速度场,各阶段共享噪声调度以保证流匹配一致性;推理时按阶段分配步数迭代更新,实现高效生成。
4. 深度压缩流——基于步数视角
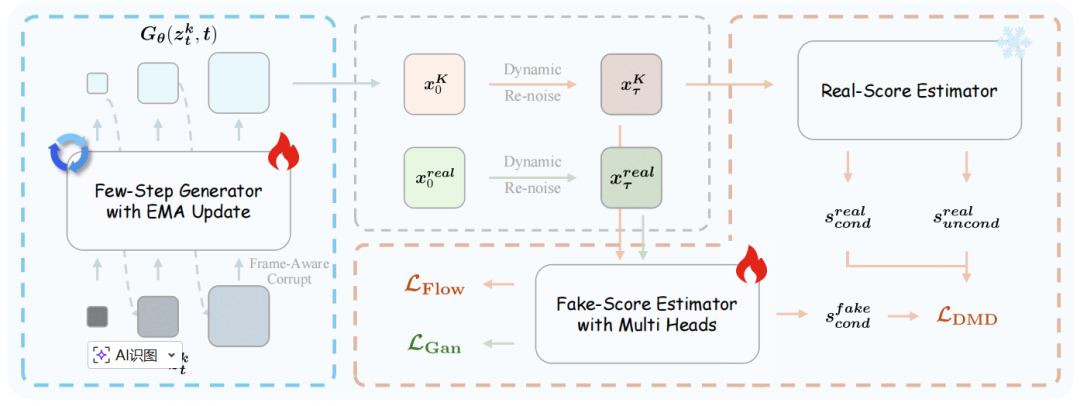
图 3 对抗层次蒸馏框架的流程。
Helios 提出基于分布匹配蒸馏(DMD)的对抗层次蒸馏框架,如图 3 所示 ,主要改进如下:
教师强制与简易抗漂移:蒸馏阶段仅以真实数据为历史上下文,单步单片段生成,配合简易抗漂移机制,在无需长展开下实现长视频稳定生成。选用长视频能力更强的 Helios-Base 为教师。
分阶段反向模拟:将 DMD 单轨迹恢复分解为多阶段迭代,逐层逼近干净样本,提升生成质量。
课程式学习:采用分阶段 ODE 预热、动态噪声调度(早期重全局、后期重细节),逐步提升优化难度,加速收敛。
对抗后训练:引入 GAN 目标突破教师能力上限,在伪造评分器中嵌入多粒度判别分支,以非饱和损失与近似正则项稳定训练,并采用随机裁剪降显存。
其他细节:生成器由中间模型初始化并继承教师评分器,损失由 DMD 与 GAN 加权构成,按 5:1 非对称更新伪造评分器与生成器,确保训练稳定与保真。
02 评估
1. 短视频生成
在81帧超短视频生成任务中,从美学(Aesthetic)、动态性(Dynamic)、平滑度(Smoothness)、语义一致性(Semantic)及自然度(Naturalness)五个维度评估各模型。Helios综合得分6.00,超越所有蒸馏模型,与多数同规模基础模型相当。蒸馏模型虽在美学与平滑度上占优,但源于饱和度高、运动幅度小,未必反映真实质量,故语义与自然度更具参考价值。Helios在这两项核心指标上表现优异,媲美甚至超越Wan 14B、HV Video等主流模型。
Helios在动态性与平滑度间取得良好平衡,既无蒸馏模型的静态倾向,也无激进加速引入的抖动与不连续。速度方面,单卡 H100 达 19.53 FPS,远超同规模FastVideo与TurboDiffusion(2–3倍),较Wan 14B提升52倍,优于七分之一规模的SANA Video Long。定性结果(图4、5)进一步印证:Helios生成视频更自然、更符合人类感知,质量与基础模型相当,优于蒸馏模型。
表 1 在81帧短视频上的定量比较。
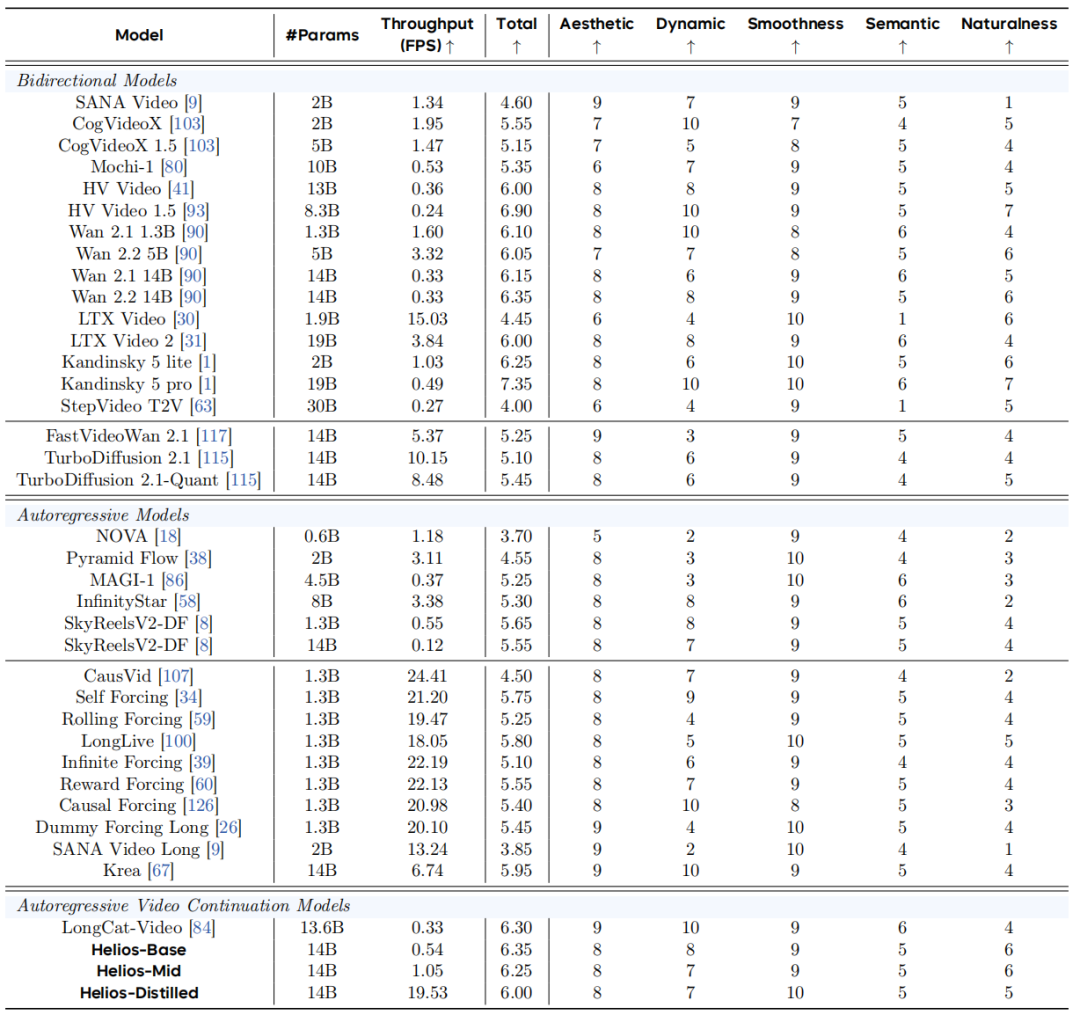

图 4 在81帧短视频的定性比较(part 1)中,Helios作为蒸馏模型,在视觉质量、运动动态及自然度方面达到甚至超越了基础模型的表现。

图 5 在81帧短视频的定性比较(part 2)中,Helios作为蒸馏模型,在视觉保真度、文本对齐及整体真实感方面达到甚至超越了基础模型。
2. 长视频生成
在表 1 基础上引入吞吐量(Throughput Score)与漂移得分(Drifting Score),评估不同时长下的长视频生成能力。如表 2 所示,Helios总分达7.08,超越最强基线 Reward Forcing,同时保持竞争性运行时间。
具体而言,Helios自然度得分更高(6分),避免了蒸馏模型的过饱和问题;动态性与运动平滑度更优,运动更生动且物理合理。此外,在美学、语义、自然度上均表现更低漂移,证明模型在长视频生成中能更好保持内容一致性与场景布局。
表 2 在120、240、720及1440帧长视频上的定量比较表明,Helios持续优于现有的实时长视频生成方法。
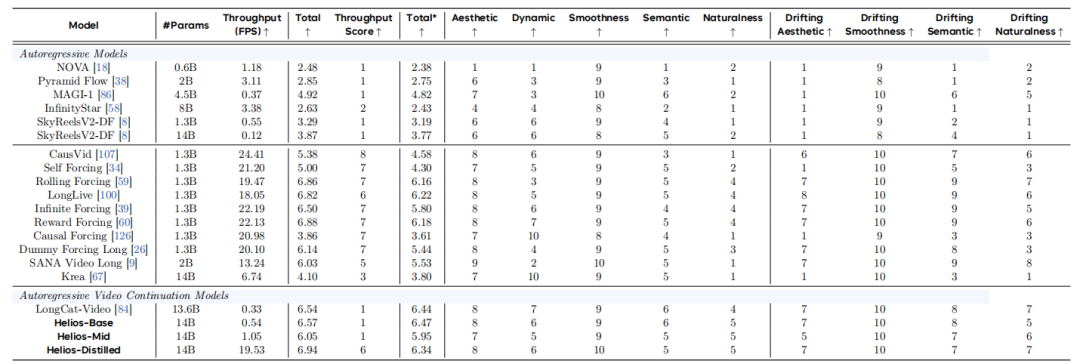
值得注意的是,尽管Helios-Stage1和Helios-Stage2未采用Self-Forcing或Error-Banks等策略,它们仍能有效缓解长视频生成中的漂移问题,这为提升长期时序一致性提供了一条互补的技术路径。图 6 和图 7 印证了这些定量结果:Helios能够随时间推移保持视觉质量,而基线方法则表现出明显的质量下降和不一致性。

图 6 在120、240、720及1440帧长视频的定性比较(part 1)。

图 7 在120、240、720及1440帧长视频的定性比较(part 2)。
3. 用户研究
针对长视频与短视频生成,各选五个模型开展并排对比。每轮对比两段视频,判断优劣或相当。每份问卷含40组对比,随机化顺序与位置以消除偏差。共收集200份有效反馈。结果显示,Helios在两类任务上均优于现有方法。
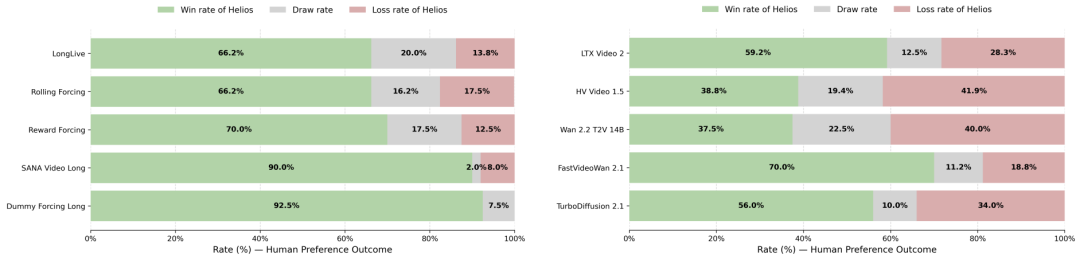
图 7 Helios与对比模型的并排人工评估。左:长视频;右:短视频。










