绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
随着大语言模型(LLM)需求的激增,服务系统需处理具有多样化服务等级目标(SLO)的高并发请求。在计算密集的预填充(prefill)阶段,长上下文请求往往独占资源,导致高优先级请求遭遇严重的队头(HoL)阻塞,进而引发首token 延迟(TTFT)的SLO违规。现有的分块预填充技术虽支持中断,但陷入了响应性与吞吐量的两难困境:减小块尺寸虽提升响应速度却牺牲计算效率,增大块尺寸则加剧阻塞。如何在动态平衡执行粒度与调度开销成为亟待解决的核心挑战。
为此,清华大学联合北京科技大学的研究者们提出了FlowPrefill,这是一个专为优化有效吞吐量(goodput)而设计的 LLM 服务系统。通过将抢占粒度与调度粒度解耦,FlowPrefill 能够在不牺牲吞吐量的前提下实现及时抢占,从而缓解预填充阶段严重的队头阻塞,并提升在线服务质量。在真实生产轨迹上的评估表明,相比现有的SOTA系统,FlowPrefill在满足异构SLO的前提下,最大有效吞吐量提升了5.6倍。

论文标题:FlowPrefill: Decoupling Preemption from Prefill Scheduling Granularity to Mitigate Head-of-Line Blocking in LLM Serving
论文链接:https://arxiv.org/pdf/2602.16603
01 方法

如图5所示,一个典型的服务系统由三个主要组件构成:代理(Proxy)、预填充实例(Prefill Instances)和解码实例(Decode Instances)。FlowPrefill 的核心优化主要集中在预填充实例中。每个预填充实例包含三个核心模块:请求队列(Request Queue)、执行池(Execution Pool)和调度器(Scheduler)。
为了从根本上解决长请求导致的队头阻塞,FlowPrefill设计了两大核心技术:算子级抢占(operator-level preemption) 和 事件驱动调度(event-driven scheduling)。
算子级抢占能够在算子边界处实现自适应的运行时抢占,使 FlowPrefill 即使在长时间运行的预填充执行过程中,也能迅速响应新到达的高优先级请求。
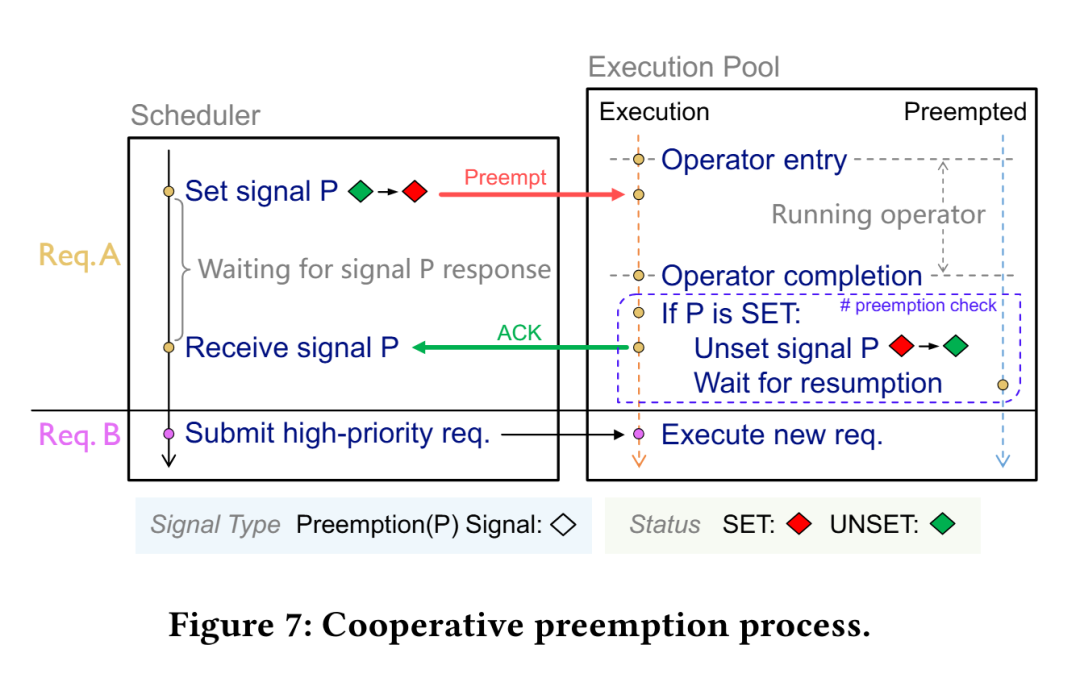
事件驱动调度仅在请求到达或完成时触发调度决策,从而实现对 SLO 敏感的优先级调度,而不会产生与抢占粒度成正比的调度开销。
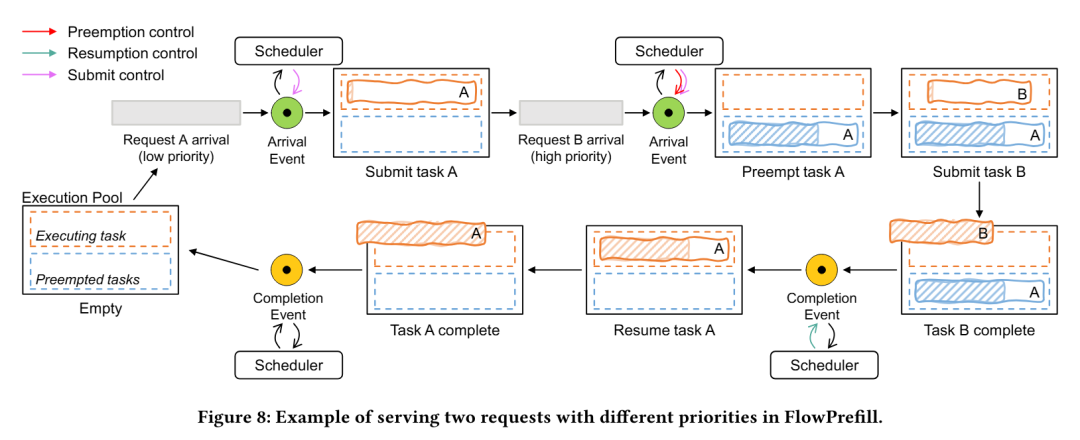
FlowPrefill 完整的调度流程如算法 2 所示。

因此,FlowPrefill 非常适用于 PD 解耦系统(即预填充与解码阶段分离处理),能够有效缓解由预填充阶段引发的队头阻塞,并在异构 SLO 要求下最大化系统有效吞吐量。
02 评估
研究团队将 FlowPrefill 与基线方法在 QwenTrace 数据集上进行了端到端性能对比,测试中变化了请求速率和 SLO要求。
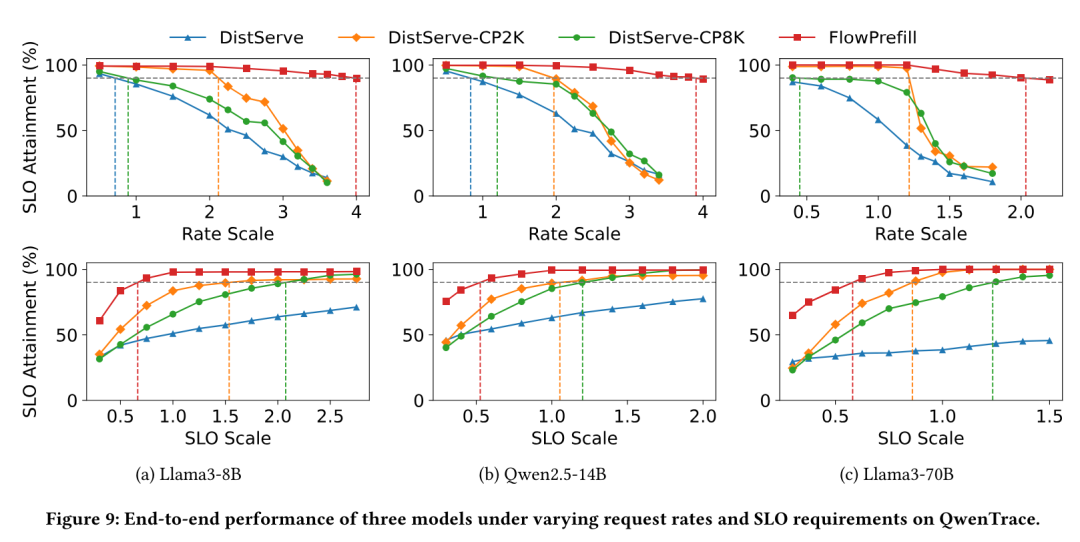
SLO 达成率 vs. 请求速率
研究团队在三种模型下评估了 FlowPrefill 在不同请求速率规模下的表现。如图 9 第一行所示,随着请求速率的增加系统负载上升,导致 SLO 达成率逐渐下降,因为越来越多的请求无法满足其延迟要求。图中的垂直线标示了最大有效吞吐量(Maximum Goodput)。
在所有模型中,FlowPrefill 能够承受的请求速率比 DistServe 高出 4.7 倍至 5.6 倍,并且相比 DistServe-CP2K 和 DistServe-CP8K 分别最高提升了 2.0 倍 和 4.5 倍。
这种提升主要归功于 FlowPrefill 在异构 SLO 环境下迅速抢占低优先级请求的能力。当高优先级请求到达时,事件驱动调度能迅速识别抢占机会,而算子级抢占则能挂起那些 SLO 要求较宽松的正在进行的长输入预填充执行,从而释放资源给对延迟敏感的请求,实现近乎无阻塞的中断。因此,延迟敏感型请求得以处理而不会产生不当延误(undue delay),这减少了预填充阶段的队头阻塞,并防止了 SLO 违规。
SLO 达成率 vs. SLO 要求
图 9 的第二行评估了系统在不同延迟要求下的鲁棒性。研究团队固定请求速率,并使用一个 SLO 缩放参数线性调整表 2 中的延迟目标。图9中的垂直线标示了各系统所能支持的最低 SLO 目标。
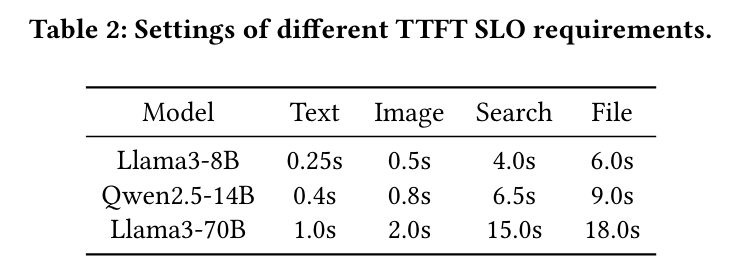
与 DistServe-CP2K 相比,FlowPrefill 支持 1.5×–2.3× 更严格的 SLO。与 DistServe-CP8K 相比,FlowPrefill 支持 2.1×–3.1× 更严格的 SLO。这些改进源于 FlowPrefill 对延迟敏感请求的近乎无阻塞执行,这提升了 SLO 达成率,并降低了平均延迟和尾部延迟。










