绑定手机号
确认绑定









社区投稿
智猩猩AI整理
近年来,世界模型(World Model)在视频生成与具身智能中越来越像一条主线:它试图学习环境的状态转移规律,让系统在给定条件下预测未来演化。
但在具身场景里,世界模型真正难的点往往不是“生成一段看起来合理的视频”,而是做到三件事同时成立:
•可控:动作(action)施加进去,世界能稳定响应
•物理一致:接触与形变符合力学直觉,能长时滚动不漂
•可视:输出是高保真、跨视角一致的可用观测(图像/视频)
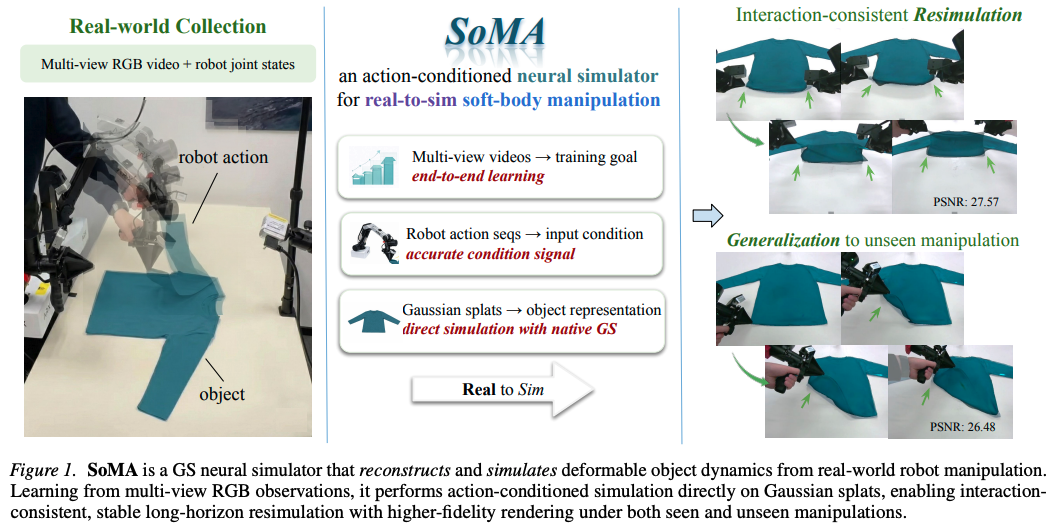
上海 AI Lab 联合复旦大学、香港大学等团队提出的SoMA,正是围绕上述这三点,给出了一种更“具身”的 world model 形态。SoMA不仅是一个仿真器,更是一个可以直接产出高质量训练数据的可控世界生成系统,它的世界演化发生在显式三维空间中,并把仿真与渲染统一在同一表征里,把世界模型从“生成未来画面”推向“动作驱动的可控世界”。
它以 3D Gaussian Splatting 作为物体表征,以层级图神经网络作为动力学仿真主干,构建轻量级的世界模型。在给定机械臂动作序列的条件下,模型能够进行接近物理仿真级别的世界状态演化预测,并同步输出多视角一致的高质量渲染结果。

论文标题:SoMA: A Real-to-Sim Neural Simulator for Robotic Soft-body Manipulation
论文链接:https://arxiv.org/abs/2602.02402
项目主页:https://city-super.github.io/SoMA/
01 简介
世界模型(World Model)的目标,是学习环境的状态转移规律:给定当前状态与动作,预测未来世界如何演化。在视频生成与具身智能中,它正逐渐成为连接“感知—控制—生成”的关键桥梁。
但具身场景对 world model 的要求,远比“生成一段看起来合理的视频”更苛刻:机器人真正需要的是一个可被动作稳定驱动、并且在物理与视觉上都足够一致的世界。
现实恰恰相反:
•真实交互数据昂贵、采集慢、难规模化;
•纯仿真数据便宜,却常出现物理与视觉不一致,导致“仿真里学得像,现实里控不住”。
SoMA 正是在这一矛盾中提出的。它构建了一个面向柔性体操作的 real-to-sim 神经仿真器:从真实多视角观测出发,将机器人、柔性物体与环境统一到同一仿真空间中,并让机械臂动作序列成为驱动世界演化的条件输入。
与两类路线相比,SoMA 的定位更接近“具身所需的动作驱动的世界模型”:
•不同于仅做 4D 重建 的方法:往往缺乏动作条件与可控性,容易“看起来对,但控不起来”;
•也不同于依赖精确物理参数的可微仿真器(MPM/SPH):real-to-sim 对齐成本高、迁移到新物体/新场景的门槛重。
具体而言,SoMA 采用 3D Gaussian Splatting 作为物体表征,并以层级图神经网络建模力驱动的动态传播机制。给定动作序列后,模型能够推进接近物理仿真级别的状态演化,同时输出高质量、跨视角一致的渲染结果,从而为具身柔体操作提供一个可扩展的数据生成环境。
02 挑战
要构建一个真正“可用”的 real-to-sim 世界模型,尤其在机器人柔性操作中,难点不止一个。至少有三类硬挑战绕不开:
1)对齐与表征:看起来对 ≠ 控得起来
真实观测来自相机与机器人系统,仿真运行在理想化物理空间。
尺度不一致、坐标系不同、材料参数未知,会让模型陷入“视觉上对齐了,但控制信号施加不进去”。
同时,柔性物体连续形变,传统网格/粒子表示往往难以兼顾几何表达与仿真稳定性。
因此 world model 一方面要解决真实—仿真空间映射,另一方面必须选择一种既连续、又适合动力学传播且可渲染的表征方式。
2)渲染与长序列:动得清晰 ≠ 动得持久
具身训练最终要用的是视频/多视角图像。几何一致不够,还要视觉高保真与跨视角一致。
更关键的是长时间序列:滚动预测的误差会累积放大,最终导致形变失真、动态漂移甚至崩塌。
所以 world model 不仅要“能动”,还要“动得久、看得清”。
3)交互与因果:像素变化 ≠ 力驱动接触
柔性操作本质是力驱动的接触过程:局部接触引发全局形变传播。
若模型只拟合可见像素变化、没有建模交互与力传播机制,就很难达到仿真级物理一致性。遮挡进一步放大这个问题。
这意味着:面向具身操作的 world model,不只是生成问题,也不只是重建问题——而是几何表示、动力学建模与真实空间对齐三者耦合的系统工程。
03 方法
SoMA 构建了一个“具身级别”的可控世界(如图所示)。这个世界由三部分组成:
•柔性操作对象:用 3D Gaussian Splats 表达(既是几何/外观表示,也是可渲染单元)
•机械臂:以关节空间动作序列作为控制输入(动作直接驱动世界演化)
•多视角相机:提供真实 2D 观测监督,并通过标定建立真实空间与仿真空间的映射
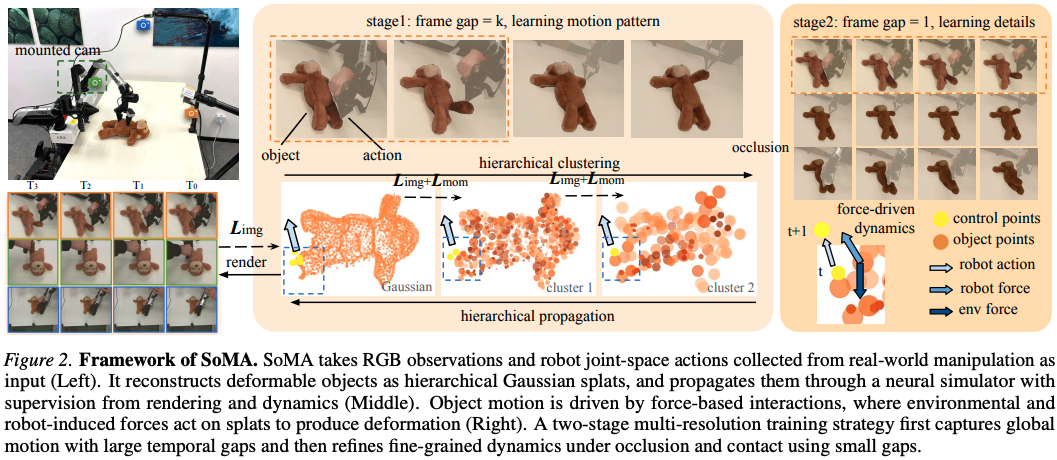
围绕前述三类挑战,SoMA 做了三层对应设计:
第一层:对齐与表示——机器人条件化的 real-to-sim 映射 + 3D Gaussian Splats 连续表征
SoMA 构建“机器人条件化”的 real-to-sim 映射,将真实观测中的机器人、物体与环境统一到同一仿真空间,解决尺度、坐标与控制对齐问题。
同时用 3D Gaussian Splats 作为连续表征,使物体既能高质量渲染,又能承载可传播的物理状态;机械臂不再被当作“视觉物体”复刻,而是以动作序列形式直接驱动系统。

一句话:它不是先重建一个“看起来像”的世界,而是直接搭一个“可以被控制”的世界。
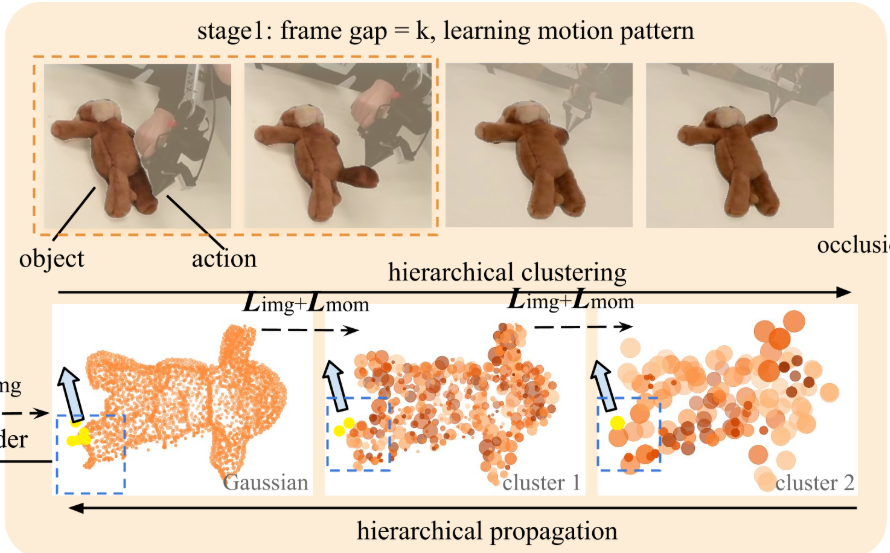
第二层:渲染与稳定——3D 隐空间动力学传播 + 多视角 2D 监督 + 多分辨率时间训练
SoMA 在 3D 隐空间中进行动力学传播,同时直接利用真实多视角 2D 图像监督。借助 Gaussian Splats 的可微渲染路径,模型在 3D 状态与图像空间之间建立稳定反传通道,多视角一致性进一步保证几何恢复稳定。
并引入多分辨率时间训练策略:先学长期粗动态,再细化短期变化,降低长序列成本并抑制误差累积。
一句话:它不仅“动得起来”,还“动得久、看得清”。
第三层:交互与动力学——层级图网络建模“接触→传播”,并引入物理一致性与遮挡感知监督
SoMA 采用层级图神经网络建模机器人—物体—环境交互结构,通过力驱动的状态更新机制,使局部接触影响能够向全局形变传播。
训练中加入物理一致性约束与遮挡感知监督,使模型在部分可观测条件下仍能维持动力学合理性,而不仅仅拟合可见像素。
一句话:它学习的不是表面变化,而是交互因果。
综上,SoMA 实际构建的是一个面向机器人操作的世界模型:给定动作序列,系统在物理一致的仿真空间中推进世界状态,并同步输出多视角、高保真的可视化结果。
04 实验
SoMA 在多个真实机器人柔性操作场景上完成验证,包括绳索(rope)、布料(cloth)、玩偶(doll),以及更具挑战性的叠衣服(T-shirt folding)任务。
评测同时覆盖两类设置:
•Resimulation:训练轨迹重演(看“复现能力”)
•Generalization:未见动作泛化(看“可控泛化”)
整体结论非常清晰:SoMA 在物理准确性与视觉质量上均显著优于现有方法。
定量结果:既更清晰,也更准确
研究从两方面评估模型表现:
•视觉一致性:PSNR / SSIM / LPIPS
•几何准确性:AbsRel / RMSE(深度误差)
相比 PhysTwin(物理驱动方法)与 GausSim(神经模拟器),SoMA 在大多数场景中取得 更高 PSNR、更低 LPIPS,同时深度误差显著下降。
这意味着模型不仅“看起来更清晰”,而且三维结构更准确。
更关键的是长序列稳定性:在叠衣服这类长时序任务中,SoMA 的误差累积更小,动态演化更稳定;对比方法在复杂形变下更容易出现结构漂移或局部崩塌。
质感差异的根源:SoMA 是“直接演化一个可渲染的三维世界”
视觉质量上的差异更容易从机制上解释。
传统神经模拟方法通常是:在低维状态空间预测节点位置→ 再交给独立渲染器生成图像。
而 SoMA 的更新发生在 3D Gaussian Splats 表征上:它不是“先仿真、再渲染”,而是在同一个三维表征里把两件事一起做了。
这带来三个直接后果:
•几何与外观统一:同一套表征同时承载形状与外观
•仿真与渲染同空间完成:状态更新直接影响可视化输出
•多视角一致性天然成立:每一步物理更新都会同步反映到各视角渲染中
因此,多视角渲染更一致,细节更锐利,形变更连续。
从定性结果看,SoMA 在布料褶皱、绳子弯曲、玩偶受力变形等细节上呈现更自然的动态变化;对比方法则更常见模糊、结构断裂或局部抖动。
换句话说:它不仅在“预测世界状态”,更是在“直接演化一个可渲染的三维世界”。

小结:SoMA 的优势集中在三点
综合来看,SoMA 在三方面形成优势:
•更准确的物理演化
•更稳定的长序列模拟
•更高保真的多视角渲染
这使它不仅是一个仿真器,更是一个可以直接产出高质量训练数据的可控世界生成系统。
05 总结
从更大的视角看,SoMA 其实卡在一个很关键的位置:
它既不像传统仿真器那样“参数重、对齐贵”,也不像纯生成式 world model 那样“画面强、可控弱”。
它更像是在回答具身世界模型最现实的问题——
不是“我能生成什么未来”,而是“我一动,世界会怎么变”。
这也是为什么可以把 SoMA 看作一种更接近具身需求的世界模型形态:“动作”作为因,“三维物理状态”作为中间变量,“多视角可视化”作为果。
传统物理仿真器:物理强,但现实接入门槛高
可微分 MPM、弹簧质点模型等路线,优势很明确:物理机理清晰、可解释。
但它们同样有硬伤:
•依赖精确物理参数设定,材料/摩擦/接触一变就得重新校准
•real-to-sim 对齐成本高,部署流程复杂
•渲染通常独立于仿真系统,视觉质量与多视角一致性不是核心设计目标
一句话:能仿真,但很难“轻量地接入真实世界”,更难快速迁移到新场景。
diffusion-based world models:感知强,但动作可控性与三维一致性难保证
近两年 diffusion-based world models 在视频生成上表现强势:
它们能生成“看起来合理”的未来帧,但多停留在像素空间或隐变量空间的动态建模:
•几何结构往往是隐式的
•物理因果关系未显式建模
•多视角一致性难以稳定保证
•更关键:对动作施加稳定、物理一致的响应并不容易
一句话:会“演戏”,但不一定“听指挥”。
SoMA:把“仿真”和“渲染”绑进同一个显式三维世界里
SoMA 的核心不同点在于:它的世界演化发生在显式三维空间中,并把仿真与渲染统一在同一表征里。
•几何是连续的:用 3D Gaussian Splats 表达
•动力学是力驱动的:用层级图神经网络建模交互传播
•动作是可控输入:动作序列直接驱动三维状态更新
•观测是可微输出:状态更新再通过可微渲染输出多视角图像
•同时在统一的 3D Gaussian Splats 表征中引入隐式物理属性编码,使几何、外观与动力学状态天然耦合,从而同时提升仿真精度、渲染质量与多视角一致性
这带来的本质收益是:几何一致性、物理一致性、多视角一致性不再是“后期补丁”,而是同一个框架下的内生约束。
一句话:它不是“先做仿真,再做渲染”,而是在一个统一三维表示里同时完成两件事。
最后一句话:SoMA 把世界模型从“生成未来画面”推向“动作驱动的可控世界”
如果说早期 world model 更像在回答——“世界将如何变化?”
那么 SoMA 所代表的方向更像在回答——当我施加一个动作,世界会如何真实地变化?
这或许正是具身智能真正需要的世界模型:可控、可视、物理一致,并且能规模化产出训练数据。










