绑定手机号
确认绑定









论文一作投稿
智猩猩AI整理
1898年,严复翻译赫胥黎的《天演论》时,提出了一个影响深远的标准:好的翻译应当做到"信、达、雅"。信,忠于原文;达,通顺易懂;雅,文辞优美。这三个字看似简单,却精准地回答了一个根本问题:我们该用什么标准来衡量"好"?
一百多年后,同样的问题出现在了一个全新的领域:什么才是一张"好"的数据可视化?
我们每天都在和图表打交道。财报里的柱状图、新闻里的折线图、Dashboard上的热力图……但你有没有想过,一张图表的"好坏"到底该怎么判定?好看就够了吗?数据准确但丑陋算好图吗?设计精美但让人看不懂呢?
这些问题,人类专家可以凭经验快速判断。但当我们把同样的问题交给AI,事情就变得有趣了。

论文链接: https://arxiv.org/abs/2510.22373
代码地址: https://github.com/HKUSTDial/VisJudgeBench
模型链接:https://huggingface.co/xypkent/visjudge-7b
Hugging Face: https://huggingface.co/papers/2510.22373
来自香港科技大学(广州)、DeepWisdom (MetaGPT) 与蒙特利尔大学的研究团队发现,严复的"信达雅"三字,恰好对应了数据可视化质量评估中最核心的三个维度:
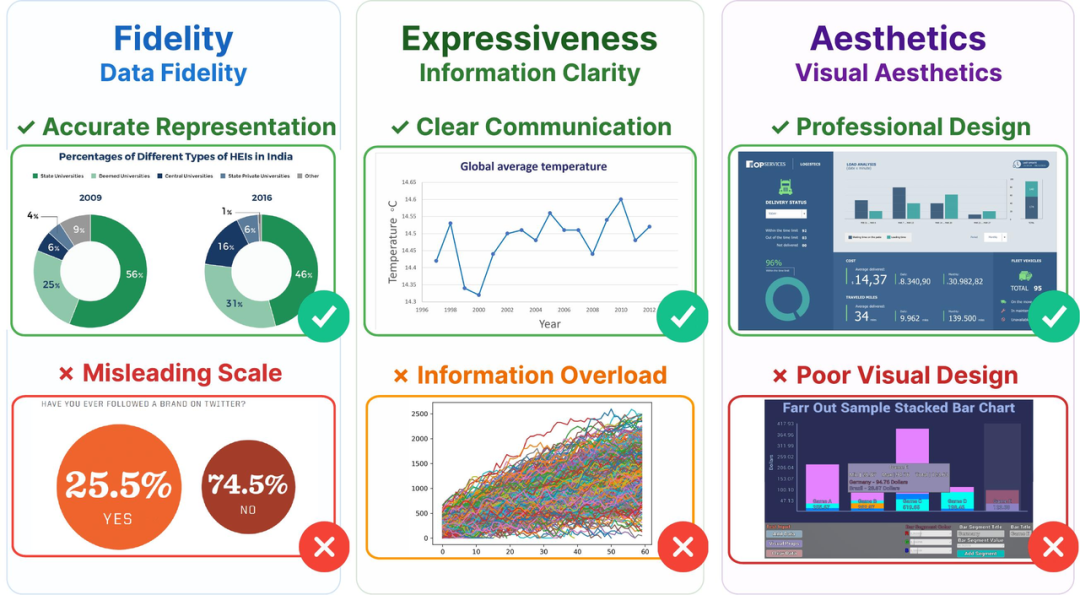
信 → Fidelity(数据忠实度)
翻译讲究忠于原文,图表讲究忠于数据。一张图表首先必须准确呈现底层数据,不能因为坐标轴截断、比例失真、色彩误导等问题歪曲事实。就像翻译中的"信"要求译者不能篡改原意,可视化中的Fidelity要求图表不能"说谎"。
达 → Expressiveness(信息表达力)
翻译讲究通顺达意,图表讲究信息传达。一张图不仅要数据准确,还要让读者能快速理解其中的信息、发现关键洞察。标签是否清晰?层次是否分明?趋势是否一目了然?这对应的正是"达"的要求:让受众真正"读懂"。
雅 → Aesthetics(视觉美感)
翻译讲究文辞优美,图表讲究设计协调。配色是否和谐?布局是否均衡?风格是否统一?好的视觉设计不仅赏心悦目,更能降低认知负担,引导读者关注最重要的信息。
这三个维度缺一不可,构成了一个完整的评估体系。一张只有"雅"没有"信"的图表,不过是漂亮的谎言;一张只有"信"没有"达"的图表,是正确但无用的数据堆砌;而只有三者兼备,才是真正的"好图"。
有了评估标准,下一个问题是:当前的AI大模型,能做到"信达雅"兼顾吗?
答案令人意外。
研究团队在构建的VisJudge-Bench基准上,对GPT-5、Claude-4-Sonnet、Gemini-2.5-Pro等12个顶尖多模态大模型进行了系统测试。结果发现,这些模型的图表评估能力,与人类专家存在巨大差距。
一个典型的例子:一张金融热力图,缺少X轴标签和颜色图例,梯度色还造成了虚假的数据边界。人类专家一眼看出问题,评分仅1.7/5。但GPT-5却被它"专业"的外表所迷惑,给出了4/5的高分,理由是"视觉惊艳且专业"。
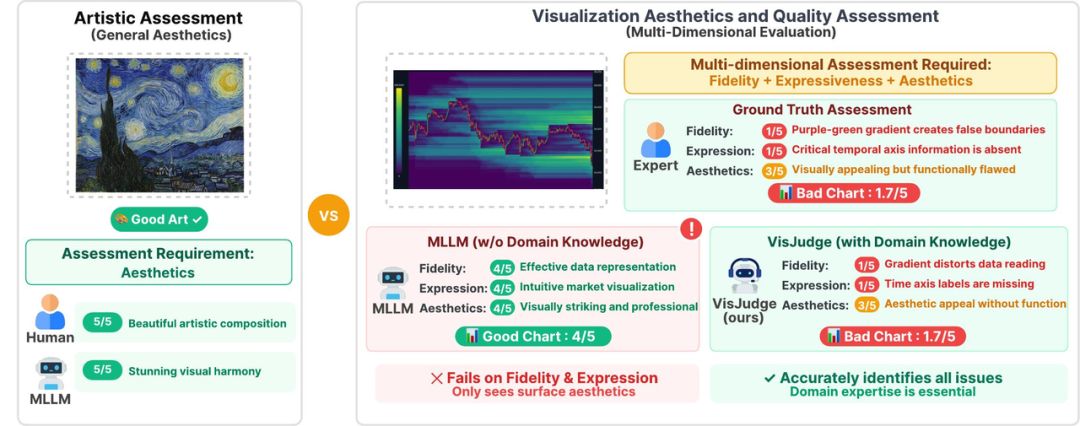
这就好比一位翻译评审,只看到译文"辞藻华美"就给了满分,却完全没注意到原文的意思已经被改得面目全非。AI做到了"赏雅",却忽略了"辨信"和"审达"。
这并非个例。研究团队的系统测试发现,即使是最强的GPT-5,与人类专家的评估一致性也不足50%,几乎相当于"每两次判断就有一次不靠谱"。通用模型缺乏对可视化领域"信达雅"标准的深度理解,这正是问题的根源。
既然发现了问题,下一步就是为AI提供学习和考核的标准。研究团队构建了VisJudge-Bench,这是首个基于"信达雅"原则的可视化质量评估基准。
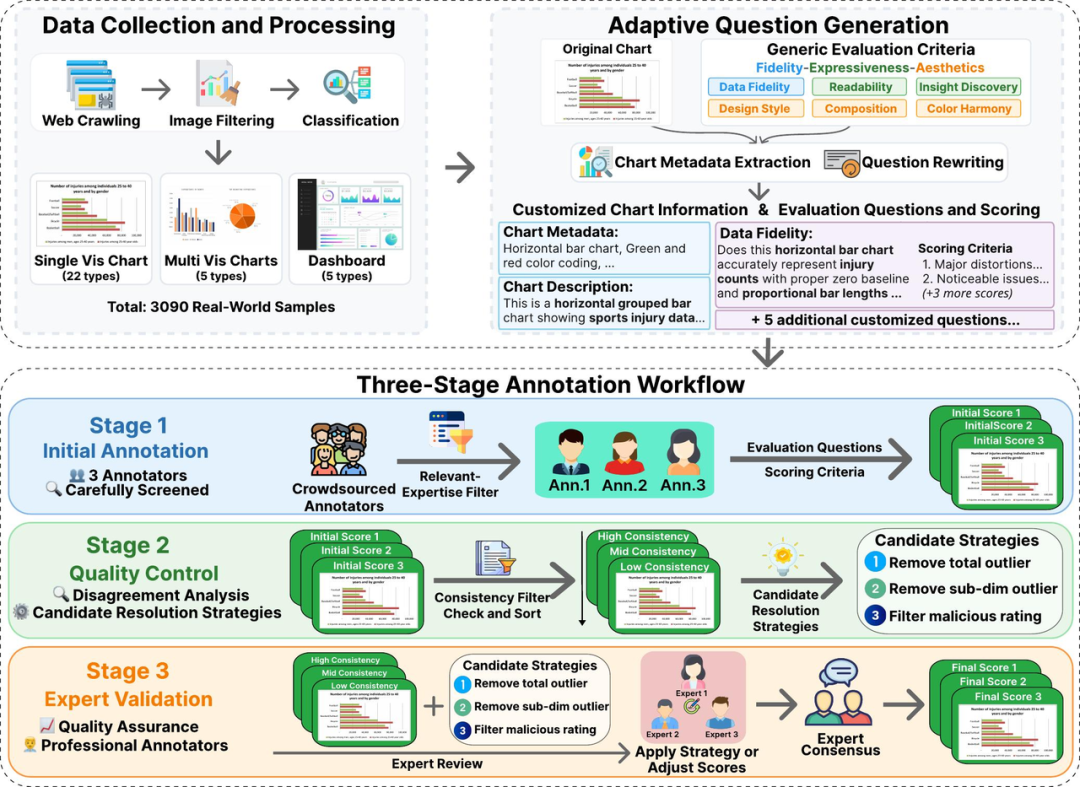
这份"考卷"的编制相当严谨:
题库建设: 从30万+网络图片中层层筛选,最终保留3,090个高质量样本,覆盖单图表(22类)、多图表(5类)和仪表盘(5类)共32种图表类型。数据来源涵盖学术论文、商业报表、新闻报道等真实场景。
评分标准: 将"信达雅"细化为6个可量化的子维度:Data Fidelity(数据忠实)、Semantic Readability(语义可读性)、Insight Discovery(洞察发现)、Design Style(设计风格)、Visual Composition(视觉构图)、Color Harmony(色彩和谐)。并且针对每张图表的具体类型和内容,自动生成定制化的评估问题和五分制评分标准。
阅卷流程: 通过CloudResearch平台招募603位经过严格筛选的标注员,每张图表由3人独立在6个子维度上打分,再经过算法自动检测评分一致性、识别离群值和恶意评分,最后由3位可视化领域专家逐一终审。这套"众包初筛 + 算法辅助 + 专家终审"的三阶段流程,确保了评分的可靠性。
有了高质量的"考卷"和"标准答案",研究团队进一步训练了一位专业的"AI评审"——VisJudge。
VisJudge以Qwen2.5-VL-7B-Instruct为基座,通过强化学习(GRPO算法)进行领域微调,让模型学会按照"信达雅"的标准,像人类专家一样为图表打分和给出评判理由。
效果如何?直接看数据:

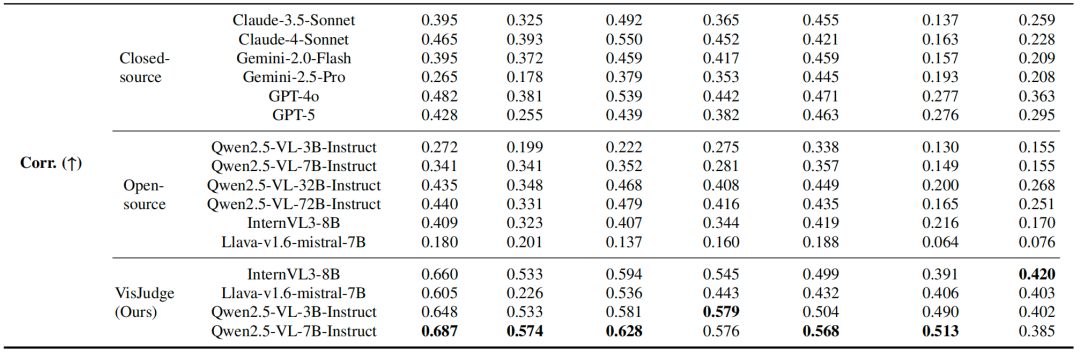
相比GPT-5,VisJudge的评估误差降低了23.9%(MAE从0.553降至0.421),与人类专家的判断一致性提升了60.5%(相关性从0.428提升至0.687)。一个仅7B参数的专业模型,全面超越了GPT-5等顶尖通用模型,甚至超越了参数量10倍于己的Qwen2.5-VL-72B(MAE 0.702)。
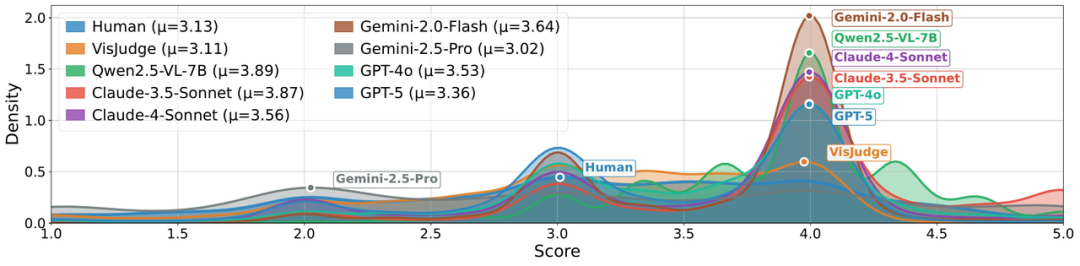
更关键的是,从评分分布来看,通用模型普遍存在系统性偏差:Qwen2.5-VL-7B和Claude-3.5-Sonnet的均值高达3.89和3.87,几乎对所有图表都"高抬贵手";Gemini-2.5-Pro又走向另一个极端,均值仅3.02,对稍有瑕疵的图表就"一票否决"。而VisJudge的评分分布与人类几乎完全重合(均值3.11 vs 人类3.13),既没有"分数膨胀"的讨好倾向,也没有"过度保守"的苛刻毛病。
在严复的框架里,VisJudge真正做到了"信达雅"兼顾。
一位好的评审,不仅要能判断好坏,还要能指导改进。在展示VisJudge的实战能力之前,先来看两组典型案例,直观感受"通用模型"和"专业评审"之间的差距。
案例一:拒绝"老好人",一眼识破混乱布局

一张布局极度混乱的Treemap,人类专家评分仅1.67。但Qwen2.5-VL-7B给出3.67分并称其"图例清晰",Claude-4-Sonnet给出3.08分并夸其"空间组织出色",GPT-5也给出3.17分。而VisJudge准确给出2.00分,正确识别出"布局混乱、难以解读"的核心问题。
案例二:告别"过敏症",读懂复杂仪表盘
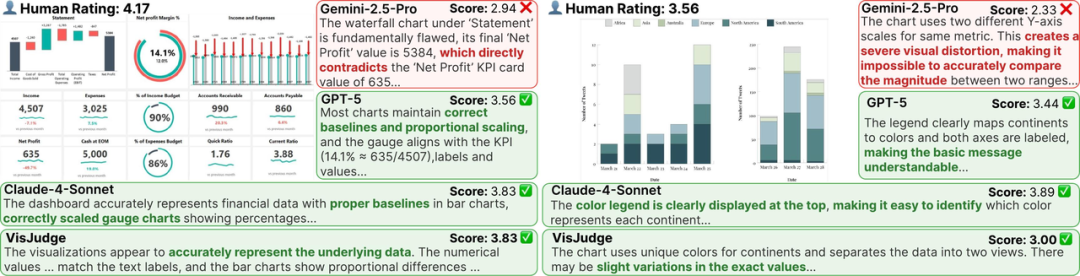
一张设计精良的财务Dashboard,人类专家给出4.17分。然而Gemini-2.5-Pro仅给出2.94分,因为一个局部瑕疵就"一票否决"了整张图,忽略了图表在数据呈现和布局设计上的整体优势。而VisJudge给出3.83分,与人类判断高度吻合。
这两组案例揭示了通用模型的两种系统性偏差:对差图表"高抬贵手"(分数膨胀),对好图表"吹毛求疵"(过度保守)。而VisJudge有效纠正了这种双向偏差。
VisJudge的能力不止于此,它还展现了"从裁判到教练"的进阶能力。
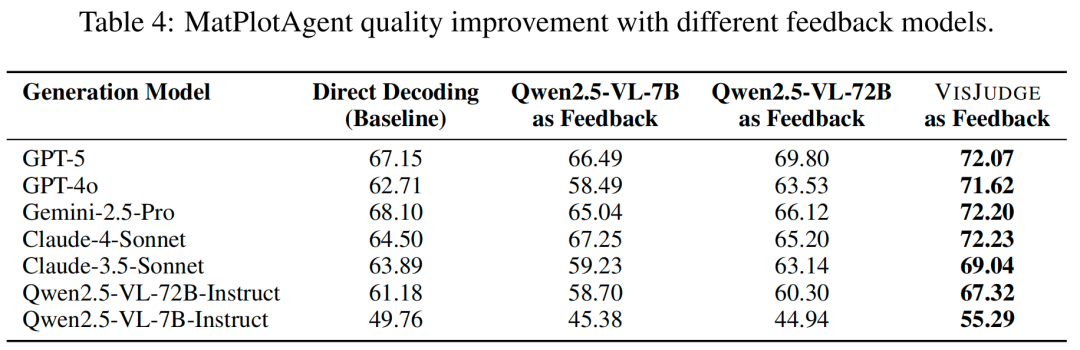
指导可视化生成: 将VisJudge作为反馈模型接入MatPlotAgent可视化生成系统,所有7个生成模型的输出质量均获得最佳表现。以GPT-5为例,直接生成得分67.15,接入VisJudge反馈后提升至72.07。而未经微调的Qwen2.5-VL-7B作为反馈时,生成质量反而平均下降2.39分,说明有偏差的评审给出的"指导意见"会适得其反。
优化可视化推荐: 在HAIChart可视化推荐系统中,VisJudge作为奖励模型使推荐准确率提升了5.3%。
这意味着VisJudge不仅能告诉你"这张图哪里不好",还能帮助AI系统"画出更好的图"。从评估到生成,形成了完整的质量提升闭环。
值得一提的是,研究还揭示了一个重要现象:随着图表复杂度的增加,通用模型的表现急剧恶化。
从单图表到多图表再到Dashboard,通用模型的评估能力逐级下滑。在Dashboard场景中,Claude-3.5-Sonnet和GPT-5在Data Fidelity维度甚至出现了负相关(-0.031和-0.013),也就是说,专家认为好的图表,模型反而认为差,判断方向完全反了。
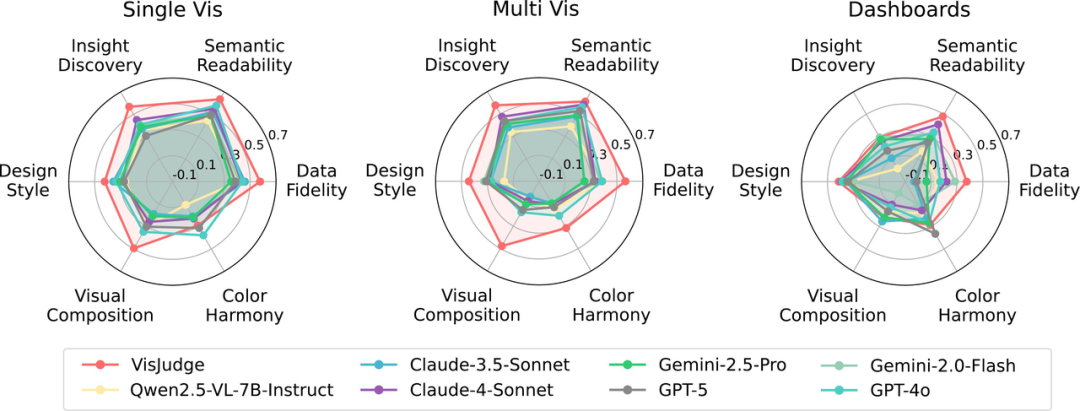
这并不难理解。Dashboard需要跨多张图表理解全局信息、梳理KPI之间的关联,这对模型的综合分析能力提出了极高要求。当前的通用模型还远未具备这种能力。而VisJudge虽然也面临挑战,但在Dashboard场景下仍保持了0.224到0.482的正相关,展现出了显著的鲁棒性优势。
严复在128年前提出"信达雅"时,大概不会想到这三个字有一天会被用来衡量AI对图表的理解能力。但这恰恰说明了好的评估标准具有穿越时代的生命力。
无论是翻译、写作还是数据可视化,核心问题始终是一样的:如何在忠于事实、清晰表达和美学追求之间找到平衡? 这不是一个纯技术问题,更是一个关于"质量"的哲学问题。
VisJudge-Bench和VisJudge的意义,不仅在于提供了一套工具和一个模型,更在于为AI可视化评估领域建立了一套有据可依的"信达雅"标准体系。当AI能够真正理解这三个维度的内涵和平衡,它才算真正"读懂"了数据可视化之美。
论文已被ICLR 2026接收,数据集与代码已开源。










