绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
现在的自回归大语言模型,在进行长文、多轮对话和agent等任务的时候,常常会遇到上下文(context)爆炸的问题。即使最近大部分模型已经升级到了 1M 的 context,但也仅仅只能塞下哈利波特全系列的2/3。
在哈利波特生活的魔法世界中,邓布利多在觉得大脑不够用的时候,会从大脑中抽取自己的记忆到冥想盆中保存,当需要的时候再抽回自己的大脑中进行思考。在现实世界中,研究者们也为LLM建立了类似的冥想盆。但在本研究中,研究团队认为:现在由Andrej Karpathy提出的上下文工程范式是有问题的,开发者们自作聪明的把魔杖握在了自己手中,给模型下一大堆“上下文工程”来操纵模型的记忆。最终,当巫师的不是LLM,而是我们这些智商比模型低得多但是掌控着服务器电源的人类,而模型,只是替人类释放魔法的“代理”。
为此,腾讯 AI Lab 提出一种新型基础模型StateLM,引入了冥想盆范式:提供一套通用的记忆操作工具,让模型能够动态管理其内部状态。实验表明,StateLM 在长上下文推理任务中,其平均性能比标准大语言模型高出 10%;在深度研究(Deep Research )任务 BrowseComp-Plus 上效果更为显著,性能平均提升45%。总而言之,研究团队的方法能够推动大语言模型从被动的上下文工程接收者变成优秀的上下文工程师,使推理真正成为可管理、可延续的动态过程。该成果已被ICLR 2026收录。

论文标题:The Pensieve Paradigm: Stateful Language Models Mastering Their Own Context
论文链接:https://arxiv.org/pdf/2602.12108
项目地址:https://github.com/xyliu-cs/StateLM
模型:https://huggingface.co/collections/lindsay21/statelm
01 方法
研究团队工作的核心问题:如果把魔杖交给LLM,会发生什么?说不定能像多比一样一个响指干翻卢修斯马尔福?
为此,研究团队提出了冥想盆范式——给模型提供一系列用来操纵记忆的通用工具,包括"删除context"、"记录笔记"、"建立索引"、"阅读片段"等等,通过学习使用这些工具,StateLM 学会了成为一名优秀的上下文工程师!

StateLM 推理流程如图2所示,模型发现文本太长的时候,就会去建立索引,接着去搜索关键信息,记录笔记,然后再删除 Context 中的冗余信息,直至最后得到正确答案。
表1是 StateLM 的咒语书,包含了所有记忆相关的工具。

研究团队的训练流程如图五所示,分为监督微调(SFT)和强化学习(RL)两个阶段。与其他智能体训练不同的是,研究团队训练的目的不再是让模型适应某个Context Engineering框架(比如Context Folding和Resum),而是让模型成为最好的 Context Engineer 。

02 评估
那么,把魔杖交给LLM,最后发生了什么呢?
表2、表3分别是在大海捞针、长文QA、长对话、Deep Research 任务上的实验结果。可以发现,StateLM 在大部分任务上都实现了10%的效果暴涨,Deep Research 任务平均涨幅更是达到了40%。
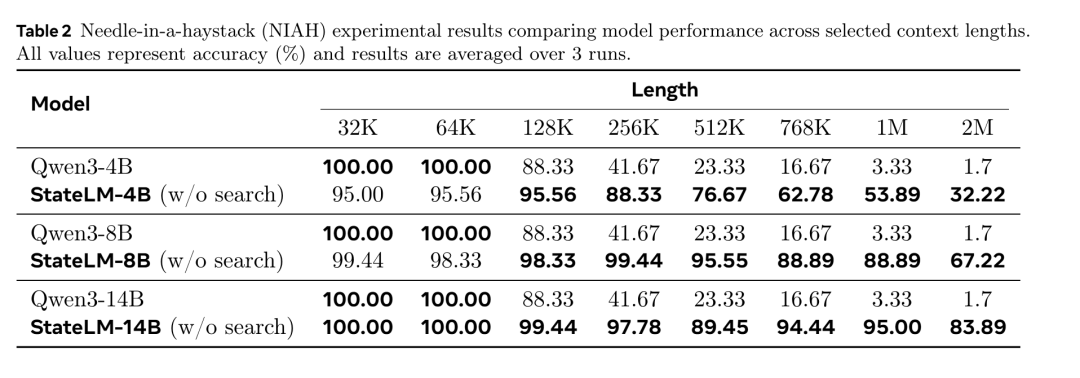

更关键的是通用性,这也是研究团队训练模型成为优秀的“上下文工程师”的意义所在。迄今为止的所有记忆框架都是task-specific的,还没有哪个框架可以同时在大海捞针、长文QA、长对话、Deep Research 任务上表现良好。MemAgent不适配Deep Research 任务,而Resum和Context Folding在长文 QA上也跑不起来。而StateLM,虽然只用了长文QA数据进行训练,但可以胜任四类任务,因为它学习的不是任务信息,而是操纵记忆的能力。
研究团队还展示了一个从1.5M tokens的哈利波特全集中,寻找哈利波特与魔法石前十章出现的所有教授信息的一个任务demo。










