绑定手机号
确认绑定









余翀 (复旦大学 眸深智能) 等投稿
智猩猩AI整理
当具身智能成为 AI 领域的终极赛道,所有从业者都在面对同一个灵魂拷问:
为什么效果拉满的顶级 VLA(视觉 - 语言 - 动作)模型,只能跑在数据中心的 H100 上,却无法落地到资源受限的机器人端侧?为什么做了轻量化的模型,又必然面临精度跳水、任务成功率暴跌的行业宿命?
为此,眸深智能提出基于动态麦克劳林级数(Dynamic Maclaurin-Series, DMS)的具身智能运动大脑。从 Transformer 架构的底层逻辑出发,以数学定理为根基完成了架构级创新,在不损失、甚至反超 SOTA 模型任务成功率的前提下,实现了内存占用最高压缩 89%、推理速度最高 75% 的飞跃,真正填平了 “顶级智能” 与 “端侧落地” 之间的鸿沟,让通用具身智能的规模化商业落地,迎来了关键拐点。

论文标题:Dynamic Maclaurin-Series-Based Embodied Model
VLA 模型是机器人的 “中枢大脑”,它能直接把视觉画面、自然语言指令,转化为机器人的精准动作,是当前具身智能的核心技术底座。但时至今日,行业始终困在一个无法破解的 “不可能三角” 里:
更关键的是,过往所有的优化方案,都只是“局部修修补补”:无论是 KV 缓存、动态早退出,还是结构化剪枝、低比特量化,都只是针对模型的单一模块做优化,解决了一个瓶颈,另一个瓶颈立刻成为新的约束,最终提速效果有限,还始终跳不出 “压缩必掉点” 的行业铁律。
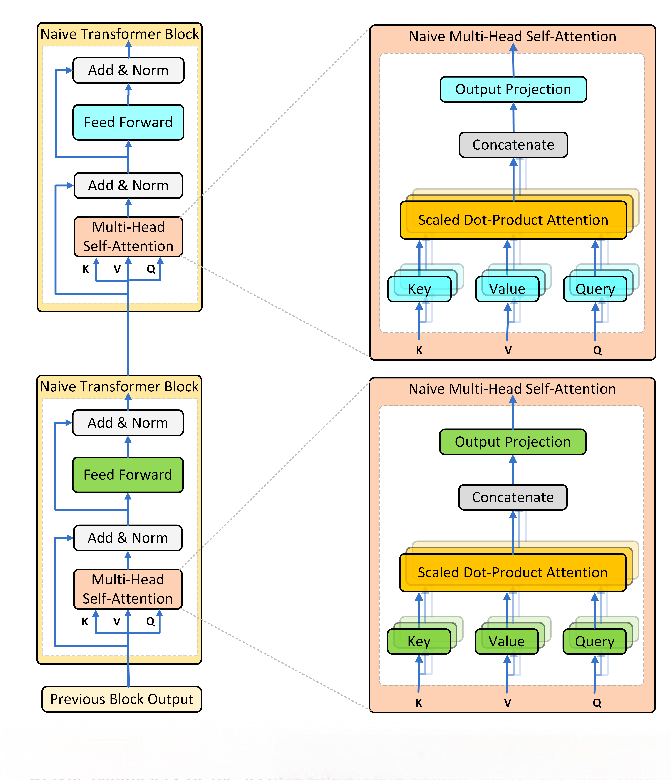
图1:原生 Transformer 架构
而 DMS 模型,从数学第一性原理出发,直接重构了 Transformer 的权重表达逻辑,从根源上解决了层间权重冗余、算力无效浪费的核心问题,第一次真正打破了这个 “不可能三角”。
DMS 模型的核心创新根基,是微积分中经典的麦克劳林级数定理:任意在 0 点无限可微的函数,都可以展开为以 0 为中心的幂级数,用有限的级数项,就能精准拟合复杂的函数变换。
而 Transformer 架构中,每一层的注意力模块(Q/K/V/ 输出投影)、前馈网络(FFN),本质上就是一个对输入张量进行变换的非线性函数。基于这个核心洞察,研究人员彻底推翻了传统 Transformer “每层独立存储完整权重张量” 的设计,提出了一套统一的麦克劳林级数权重逼近框架:
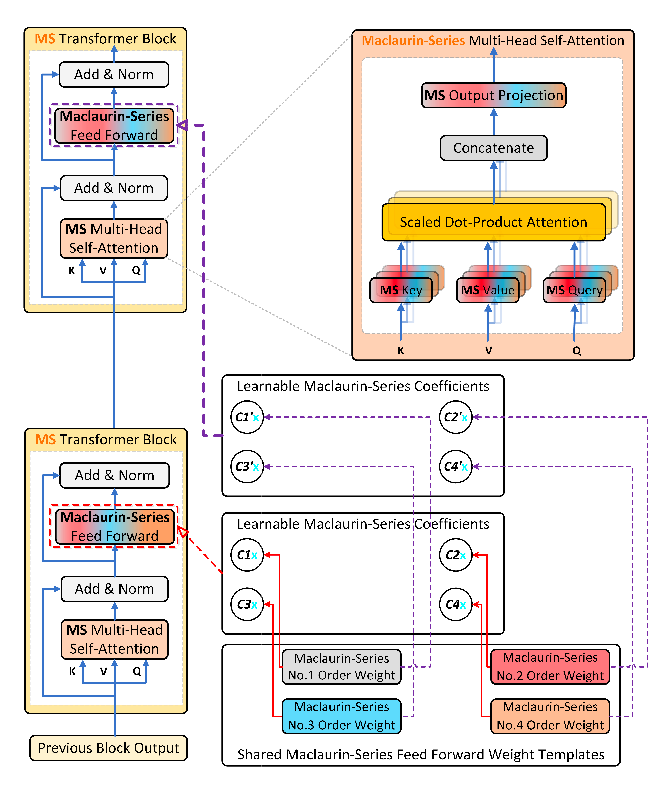
图2:DMS 模型架构
这是什么概念?
传统的 32 层 Transformer VLA 模型,就像盖 32 层楼,每一层都要重新设计、生产一整套完全独立的钢筋、水泥、建材,不仅耗材巨大,还极度占用存储空间;
而 DMS 模型,相当于只需要生产一套标准化的核心建材模板,每一层只需要调整几个配比系数,就能盖出结构强度、功能完全达标,甚至更优的楼层。
在最优配置下,仅用 12 套共享权重模板,就能完美拟合 32 层 Transformer 的全部权重变换,带来的效果是颠覆性的:
模型运行内存直接降至原版的 41%,极限配置下甚至能压缩到 11%,而任务成功率没有任何损失。这不是小修小补的模型压缩,而是从底层逻辑上,彻底解决了 Transformer 架构层间权重冗余的行业顽疾。
如果说共享权重模板解决了“内存爆炸” 的问题,首创的动态级数扩展机制,则彻底解决了“算力无效浪费” 的行业痛点,真正实现了 “好钢用在刀刃上”。
麦克劳林级数的核心精髓在于:拟合简单函数,只需要少数低阶项;只有拟合复杂函数时,才需要叠加更多高阶项。该团队把这个数学原理,完美落地到了 VLA 模型的推理过程中:
传统 VLA 模型,无论输入的指令和画面是简单还是复杂,都必须跑满全部层数、全部计算量,就像不管是城市拥堵路段还是高速公路,都始终一脚油门踩到底,不仅费油,还毫无必要;
而 DMS 模型,能根据输入的视觉 - 语言复杂度,自适应调整调用的麦克劳林级数项数量:
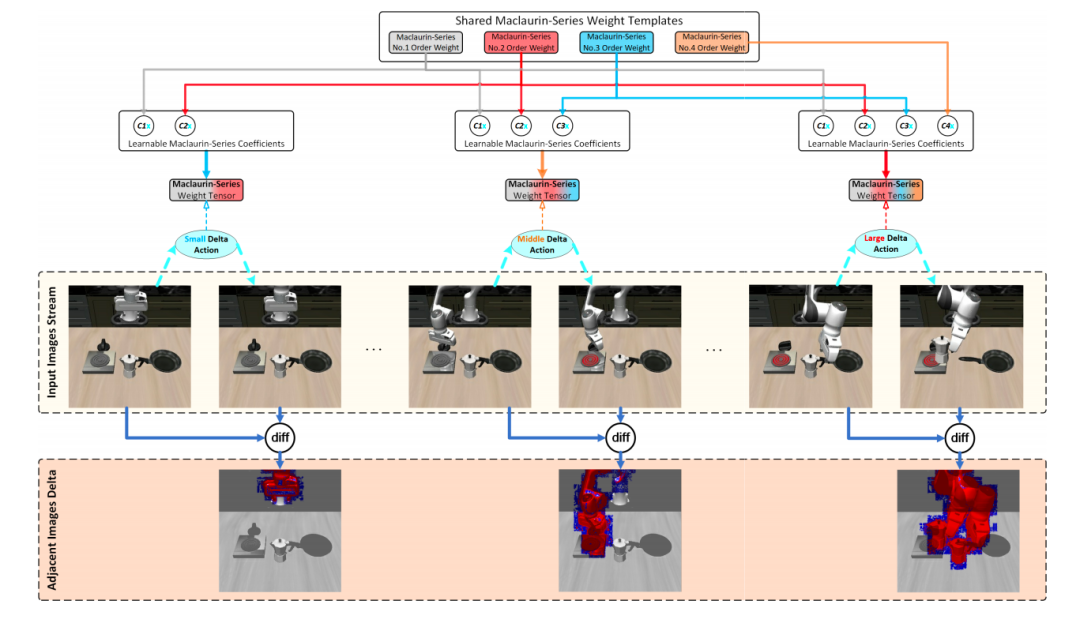
图3:麦克劳林级数权重模板的动态调用机制
为了让复杂度判断更精准,首创了target-action-diff 目标动作差分策略:先从语言指令中提取核心目标物体和对应动作,过滤掉画面中无关的背景和无效视觉 token,只针对有效区域计算帧间差异,判断场景复杂度。
消融实验证明,这套策略比全帧差分策略,能进一步提升任务成功率,让模型真正做到“关注该关注的,计算该计算的”。
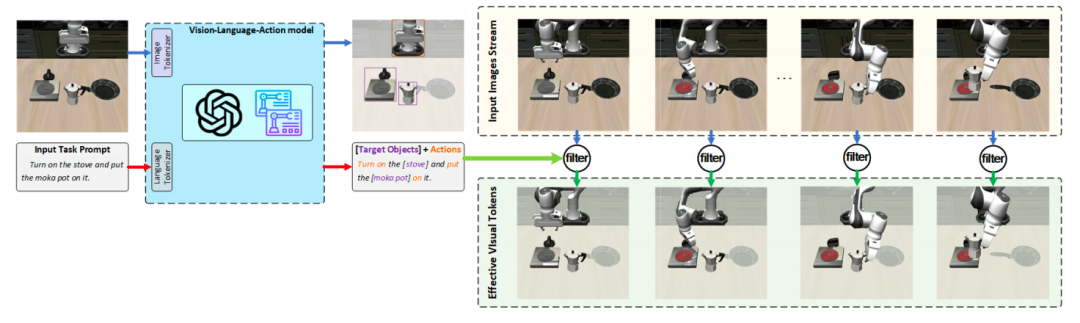
图4:target-action-diff 策略原理
在行业权威基准、真实机器人平台、全品类硬件部署上,完成了全方位的验证,每一组数据,都在刷新行业的认知。
1. 任务效果:轻量化不掉点,甚至反超 SOTA 基线
在LIBERO和SIMPLER两大行业公认的测试集上, DMS 模型与当前业界顶级的 VLA 基线(Octo、π0、π0.5、OpenVLA-OFT 等)正面交锋,结果一目了然:
2. 部署性能:跨平台全维度提速,端侧部署迎来史诗级突破
在从高端数据中心到边缘端的全品类硬件上,完成了部署测试,提速效果远超当前业界所有轻量化方案:
硬件平台 | 相对原版 OpenVLA 的推理提速 | 相对业界最优轻量化方案的优势 |
NVIDIA H100 | 最高1.78倍(78%提速) | 远超动态早退出、token 缓存等方案,同时精度损失近乎为 0 |
NVIDIA RTX4090 | 最高 1.76 倍(76%提速) | 让消费级显卡就能流畅运行顶级 VLA 模型,大幅降低部署门槛 |
Jetson AGX Orin 边缘端 | 最高 1.85 倍(85%提速)INT4 量化版达 2.96 倍 | 让原本只能在云端运行的大模型,实现了机器人端侧的实时闭环推理 |
与此同时,模型的内存占用实现了断崖式下降:12 个共享模板的最优配置下,Jetson Orin 端侧运行内存仅为原版的 41%,极限配置下可降至 11%,彻底解决了机器人端侧内存不足的核心痛点。
3. 与业界轻量化方案的正面 PK:全面碾压,无短板胜出
将 DMS 模型与当前业界主流的轻量化方案(动态早退出、INT4 量化、token 剪枝、token 缓存)进行了同条件对比,结果毫无悬念:
DMS 模型在保持与原版近乎一致的任务成功率的前提下,实现了远超所有方案的推理提速,同时内存占用降幅创下行业新高。即便是 INT4 量化版本,DMS 也在 Jetson Orin 上实现了 2.96 倍的提速,远超同精度下 QAIL 量化方案的 2.47 倍,同时任务成功率高出 2 个百分点。
很多人问,DMS 模型的核心壁垒到底是什么?
答案从来不是某一个模块的优化,而是从数学原理出发,对 VLA 模型架构的底层重构。过往的所有方案,都在 Transformer 的固有框架里做 “减法”,而我们用麦克劳林级数定理,建立了一套全新的权重表达与动态推理体系,做的是 “从 0 到 1 的创新”。
具身智能的终极愿景,是让机器人走进工厂、走进家庭、走进人类生活的每一个场景。而这个愿景最大的卡点,从来不是实验室里的模型有多强,而是顶级的智能能否真正落地到每一台机器人的端侧,能否在有限的硬件资源里,实现稳定、实时、精准的操控。
DMS 动态麦克劳林级数具身智能运动大脑,正是为了解决这个核心问题而生。它让顶级 VLA 模型告别了对云端大算力的依赖,让机器人端侧就能拥有媲美数据中心的智能能力,更低的延迟、更高的安全性、更低的部署成本,为工业机器人、服务机器人、人形机器人的规模化落地,铺平了核心技术道路。
而这,只是起点。未来,将继续以数学为根基,以落地为目标,持续突破具身智能的技术边界,让通用智能真正走进物理世界。










