绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
当前视频生成模型虽然生成能力强,但推理成本过高,导致等待时间长、GPU开销大,难以大规模应用。现有加速手段中,一是免训练方法加速效果有限,且容易影响生成质量;二是步数蒸馏虽能提速,但在多步推理下增益不大,单次计算成本依然很高,整体负担仍难缓解。
为此,字节跳动研究团队提出了 FSVideo——一种基于Transformer的高速图像到视频(I2V)扩散框架。最终模型包含一个14B参数的DIT基础模型与一个14B参数的DIT上采样器,在实现与主流开源模型相当的性能同时,推理速度提升一个数量级。

论文标题:FSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
论文链接:https://arxiv.org/pdf/2602.02092
项目主页:https://kingofprank.github.io/fsvideo/
01 FSVideo 框架
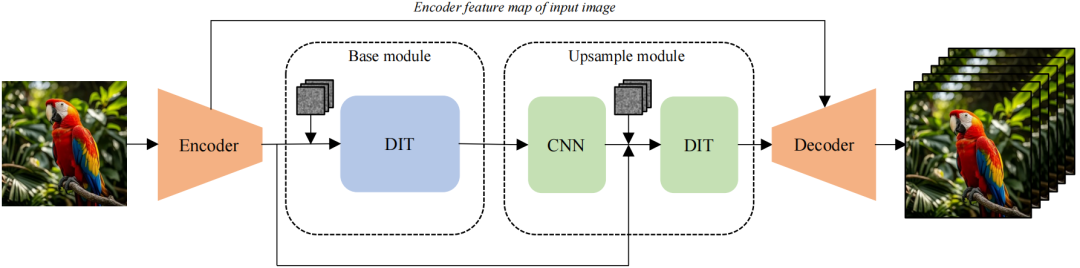
图 1 FSVideo 图像生成视频流程的总体框架
FSVideo 图像生成视频流程的总体框架如图 1 所示,该框架由以下关键组件构建:
1)高度压缩潜在空间的视频自编码器:研究团队引入了一种新的非对称视频自编码器FSAE,实现了总计384×的信息缩减;
2)改进的带有层记忆的DiT:提出了一种新的DiT架构,该架构引入层记忆机制,为扩散过程中的信息流提供更多自由度;
3)用于提升视频保真度的潜在视频上采样器:提出了一个上采样器模块,由卷积潜在上采样器和DIT优化器组成。
通过上述设计,FSVideo能够生成具有竞争力的视频质量,同时相比其他参数规模相近的开源模型,速度提升一个数量级(例如,比Wan2.1-14B快42.3×)。
1. 视频自编码器
研究团队提出了 FSAE 模型,其模型框架如图 2 所示。该方法所有下采样/上采样操作均在自编码器内部完成,这样的设计可获得更优的重建质量并减少伪影。

图 2 FSAE 总体框架
该视频自编码器基于DC-AE架构(一种面向图像生成的深度压缩自编码器)。以dc-ae-f32c32-sana-1.0版本为起点,通过在编码器与解码器中分别增加一组Transformer模块,将空间压缩比提升至64×64,同时将隐空间通道数扩展至128。继而将自编码器的2D卷积核扩展为因果3D卷积,以支持长视频生成及视频-图像联合训练。
进一步地,在下采样/上采样操作中融入时间维度,实现时空特征与通道之间的转换。最终,调整编码器与解码器外部两个模块的下采样/上采样方式,引入时间维降维,使自编码器实现4倍时间压缩,达成64×64×4的总体压缩目标。
2. 视频扩散 Transformer
由于DiT在高度压缩的隐空间中进行训练,需采用成熟的DIT架构以保证训练稳定性,同时探索如何更充分地利用其表征能力。基于此,研究团队选择Wan2.1-14B-I2V 的DIT结构作为基线并加以改进。
与WAN不同的是,在Patchify模块中采用了尺寸为 的卷积核——这是由于自编码器已实现高度压缩。该操作生成形状为 的隐式token序列,其中 表示批量大小, 表示隐式嵌入维度,序列长度 的计算公式为 。
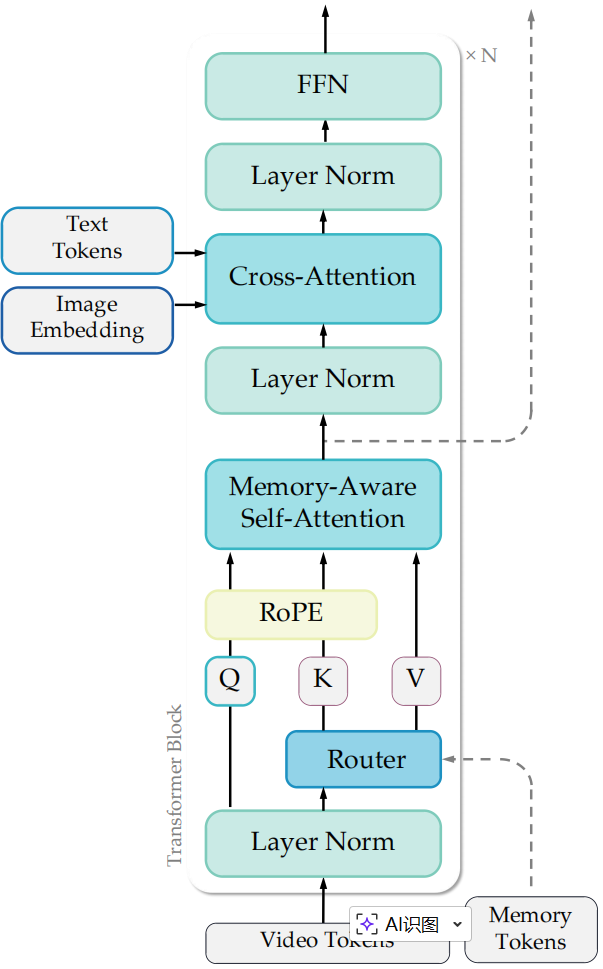
图 3 FSVideo的Transformer层
改进后的带层记忆Transformer层如图 3 所示,该层包含自注意力模块与交叉注意力模块,二者以UmT5文本嵌入和输入图像的CLIP嵌入为条件。
为增强层间信息流动并提升DIT的表征能力,引入了新型层记忆自注意力机制,该机制允许每一层自适应地关注来自所有前置层的部分注意力特征。与各层仅关注前一层隐藏状态的标准设计不同,层记忆机制使每个自注意力块能够访问所有先前层表示的可学习混合,从而在DIT深度方向上形成可微分的记忆。该设计促进了层级化信息复用,并增强了深度维度的时序一致性。
3. 视频上采样器
经过基础DIT训练后,由于FSAE的高度空间压缩,生成视频仍存在细节不足的问题。为此,研究团队提出了一个额外的上采样步骤以提升视频保真度。图 4 展示了潜在上采样器的训练框架,该上采样步骤包含两个模块:
1)卷积潜在上采样器:该设计将低分辨率潜在表示上采样至高分辨率特征空间,生成初步的潜在草稿;
2)高分辨率DIT精炼器:高分辨率精炼器随后以此草稿为条件,生成完整的视频序列。
该过程在保持低分辨率输入整体结构的同时,细化视觉细节并恢复高频特征,最终输出高质量视频。
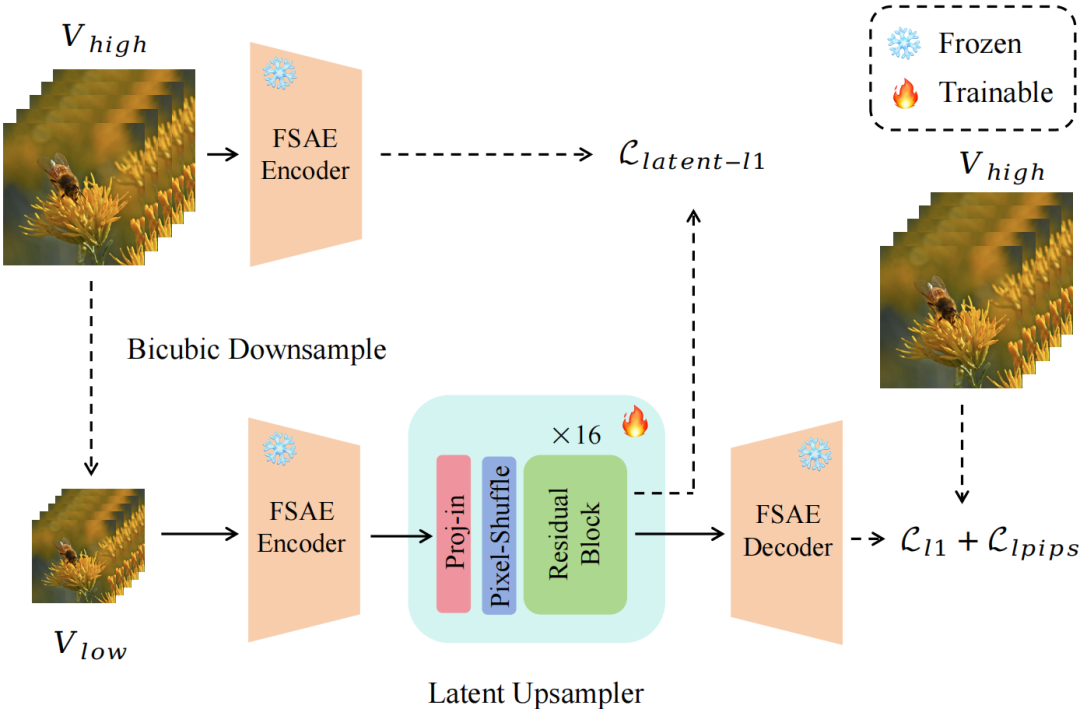
图 4 潜在上采样器的总体框架
02 评估
为评估FSVideo与其他主流I2V模型的性能,在VBench 2.0 I2V基准上进行了图像到视频的评估。
表 1 VBench 720×1280图像到视频生成结果
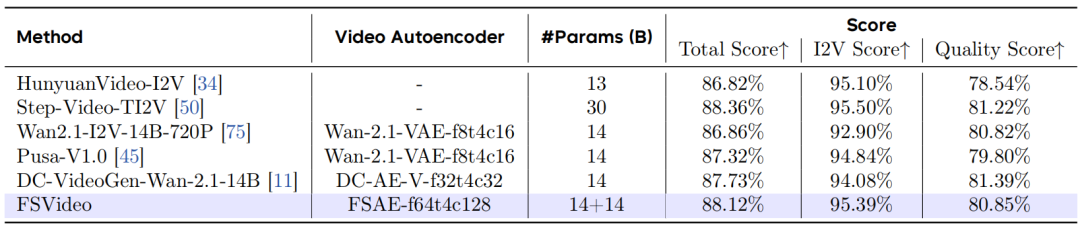
表 1 展示了720×1280分辨率下的VBench评估结果,实验结果表明 FSVideo 在与同类开源模型的比较中取得了具有竞争力的分数,虽略低于 Step-Video-TI2V,但实现了最高的视频压缩率。具体而言,相较于其他基于Wan 2.1 DIT 的模型,FSVideo获得了最佳总分,同时其压缩率高于DC-VideoGen等其他深度压缩方法。
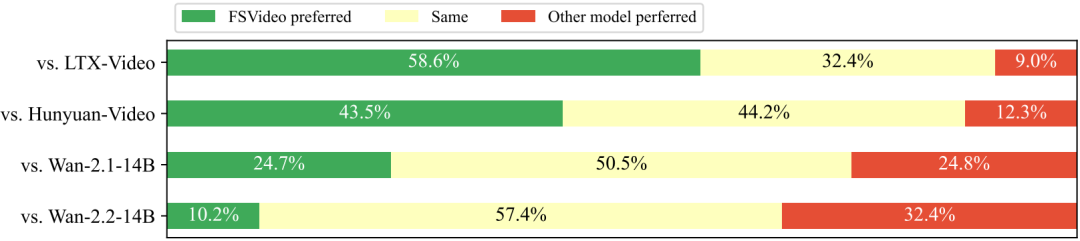
图 5 与其他模型的 GSB 评估对比
此外,针对FSVideo与其他主流开源视频生成模型开展了一系列人工评估,结果如图 5 所示。FSVideo的性能显著优于HunyuanVideo和LTX-Video,与Wan 2.1 14B相当,同时具备更高的压缩率,从而实现了更快的推理速度(如表 2 所示)。与Wan 2.2 14B相比,FSVideo的偏好度略低。但鉴于FSVideo受限于训练数据与计算资源,训练尚不充分,可以预见,在更充足、更高质量的训练数据及更长的训练周期下,FSVideo的性能有望得到进一步提升。
表 2 生成 5 秒 720×1280 分辨率 24 fps 视频的 DIT 推理速度比较

推理速度
在配备FlashAttention 3 的H100 GPU上评估了推理速度。单GPU情形,对FSVideo的两个DIT进行参数卸载;双GPU情形,利用FSDP与上下文并行技术降低内存占用,从而避免参数卸载。
由表 2 的评估结果可见,在单GPU场景下,即使采用参数卸载,Wan模型也无法生成5秒24 fps的视频,而FSVideo成功生成,耗时76.6秒。在双GPU场景下,FSVideo实现了42.3倍的加速,在NFE相近的情况下远快于Wan2.1 14B。若能突破GPU内存限制,例如采用FP8量化,预计FSVideo相较于Wan2.1 14B可实现至少58.7倍的加速。
此外,还可引入缓存或激进步长蒸馏等加速方法。由于这些方法减少了NFE数量,而本模型降低了每NFE的计算量,两者结合可实现乘法级的性能提升,进一步强化FSVideo的速度优势。










