绑定手机号
确认绑定









智猩猩AI整理
编辑:宁宁
围绕大模型外层 harness(负责上下文组织、记忆更新、检索调用与工具编排的运行框架)做自动化优化,正在成为提升复杂任务表现的重要方向。但目前该工作仍高度依赖人工经验:开发者往往需要反复查看失败案例、手工调整提示、检索、记忆与工具使用逻辑;而现有不少文本优化方法又把反馈压缩成分数、摘要或短模板,难以保留长链路任务里真正有诊断价值的执行细节。
为此,斯坦福、MIT 等机构研究学者提出了自动化 harness 搜索框架 Meta-Harness。它的核心思路是:不再只优化单条 prompt,而是直接把完整 harness 程序作为优化对象;同时把历史候选的代码、分数和执行轨迹完整写入文件系统,让coding agent 自主检索、分析失败原因并改写 harness,从而把原本依赖人工试错的系统优化过程自动化。
实验结果表明,Meta-Harness 在在线文本分类任务上相较 ACE 将平均准确率从 40.9% 提升到 48.6%,同时额外上下文开销从 50.8K tokens 降到 11.4K;在 200 道 IMO 级数学题上,平均 pass@1 相比无检索基线提升 4.7 个点;在 TerminalBench-2 上,Meta-Harness 在 Claude Opus 4.6 上达到 76.4%,超过 Terminus-KIRA 的 74.7%,在 Claude Haiku 4.5 上达到 37.6%,高于 Goose 的 35.5%。

论文标题:Meta-Harness: End-to-End Optimization of Model Harnesses
原文链接:https://arxiv.org/pdf/2603.28052
项目链接:https://github.com/stanford-iris-lab/meta-harness-tbench2-artifact
带互动演示的项目页面:https://yoonholee.com/meta-harness/
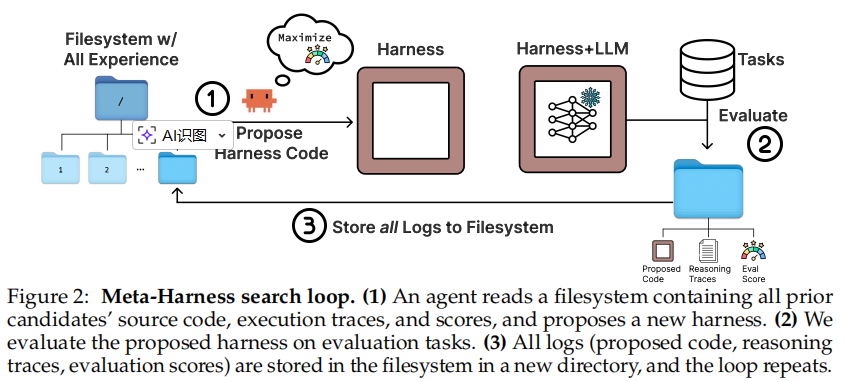
Meta-Harness 的优化对象不是单条 prompt,而是完整的 harness 程序。研究团队定义harness 为一个包裹固定语言模型的有状态程序:它决定每一步给模型看什么上下文、如何更新状态、什么时候检索,以及如何组织提示。目标是在固定底层模型的前提下,找到使任务表现最好的 harness;若同时考虑准确率和上下文成本,则在 Pareto 前沿上筛选候选。
它的外循环很简单:提出候选 harness → 在搜索集上评测 → 把代码、分数和执行轨迹写回文件系统 → 继续下一轮,如图2所示。不同于许多方法预先写死父代选择规则(parent-selection rule)或搜索模板,Meta-Harness 把“该看哪些历史候选、分析哪些失败模式、做局部修改还是整体重写”交给 proposer(提案智能体)。简而言之外循环只负责搭建舞台,真正的诊断和提案由 coding agent 完成。
Meta-Harness的核心在于完整历史经验通过文件系统暴露给 proposer。研究团队认为,harness search 的难点不是没有反馈,而是反馈太容易被压缩坏:单一分数、LLM 摘要、模板化反思,往往会丢掉真正关键的诊断信号。为此Meta-Harness 不把经验压成一个大 prompt,而是让 proposer 用 grep、cat 等终端操作主动查看原始代码和执行轨迹。研究团队统计,在高难设定下proposer 每轮中位数读取 82 个文件,其中约 41% 是旧 harness 代码,40% 是执行轨迹。这说明它依赖的是跨多轮历史的诊断,而不是围绕最近一次结果做局部修补。
在具体实现上,实验里的每个 harness 都是单文件 Python 程序,可以修改 prompting、retrieval、memory 和 orchestration 逻辑;proposer 使用 Claude Code + Opus-4.6,底层被优化模型在搜索过程中保持冻结。一次典型运行大约评测 60 个 harness,持续 20 轮左右。从搜索结果看,Meta-Harness 学出来的并不是统一模板,而是任务相关的程序策略:在文本分类中,它发现了 Draft Verification 和 Label-Primed Query 两类结构;在数学推理中,它学出了一个四路 BM25 检索程序,根据题型切换不同的候选数、去重与重排策略。
研究团队在三个任务域上评测 Meta-Harness:在线文本分类、检索增强数学推理和智能体编程任务。
在线文本分类任务域内。研究团队使用 GPT-OSS-120B,在 LawBench、Symptom2Disease 和 USPTO-50k 三个数据集上测试。Meta-Harness 的平均准确率达到 48.6%,显著高于 ACE 的 40.9% 和 MCE 的 40.0%;同时额外上下文仅 11.4K tokens,明显低于 ACE 的 50.8K 和 MCE 的 28.5K。这说明它的优势并不是“喂更多信息”,而是更高效地组织信息。进一步和 OpenEvolve、TTT-Discover、GEPA 等方法对比时,Meta-Harness 在搜索集上的中位/最佳准确率达到 50.0/56.7,而且只需约 1/10 的评测次数,就能追平其他方法的最终结果并继续拉开差距。
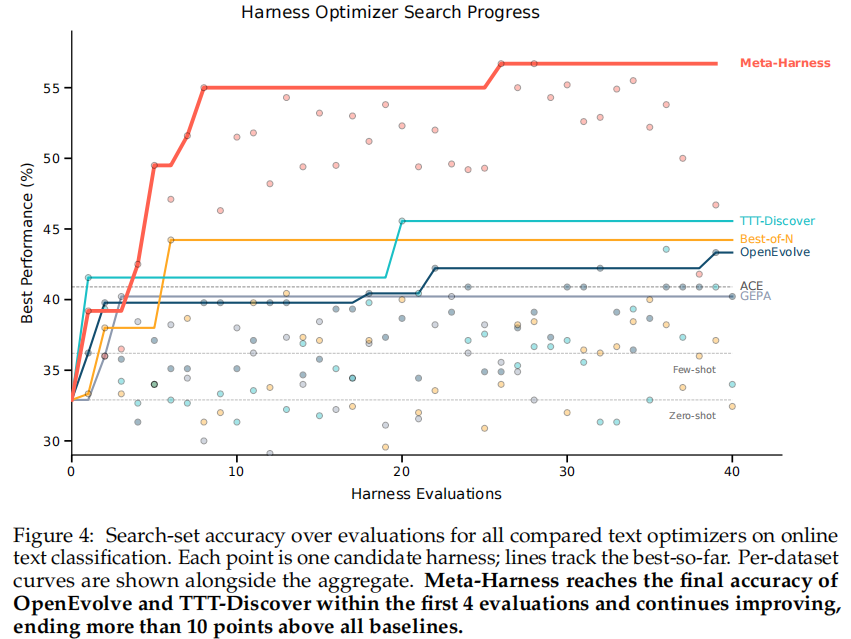
研究团队还做了一个很关键的消融实验。如果 proposer 只能看分数和代码,最佳准确率只有 41.3;若再加上 LLM 生成的摘要,最佳结果是 38.7;而接入原始执行轨迹后,最佳结果提升到 56.7。这说明对 harness search 来说,真正关键的不是更精致的摘要,而是保留原始执行轨迹中的诊断细节。研究团队还把最终 harness 放到 9 个未见过的数据集上做分布外泛化测试,平均准确率达到 73.1%,高于 ACE 的 70.2%,说明它学到的是可迁移策略,而不只是对搜索集过拟合。
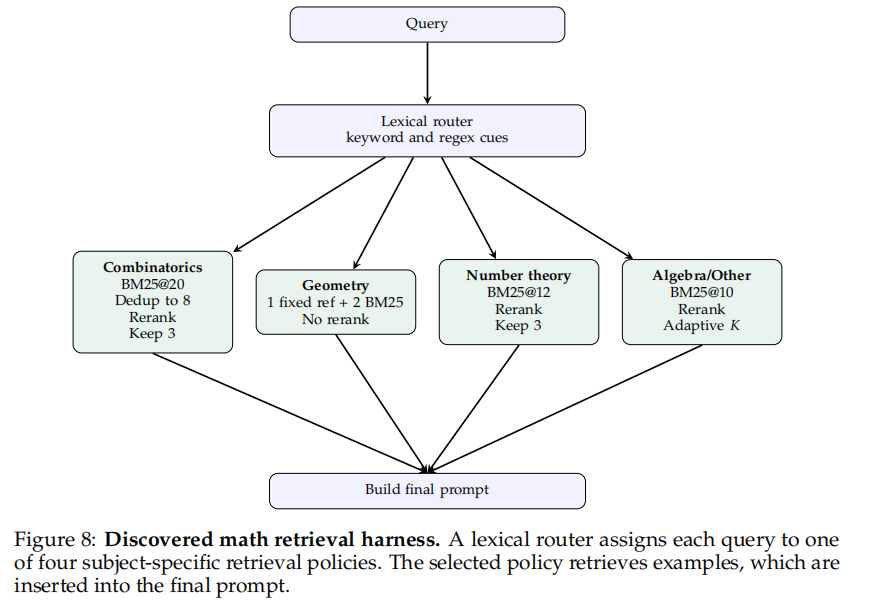
在数学推理任务任务域内。研究团队构建了一个超过 50 万道已解数学题的检索库,在 250 道奥赛难题上搜索,最终在 200 道未见过的 IMO 级问题上测试,同时迁移到 5 个搜索阶段未见过的模型。研究结果显示,Meta-Harness 的平均 pass@1 为 38.8%,比无检索基线 34.1% 提升 4.7 个点,也高于 BM25 Retrieval 的 37.5%。更重要的是Dense Retrieval 和 Random Few-shot 在一些模型上会出现负增益,而 Meta-Harness 更稳定。充分证明了高难数学任务中,关键不在“有没有检索”,而在能否自动学出合适的检索路由与重排策略。
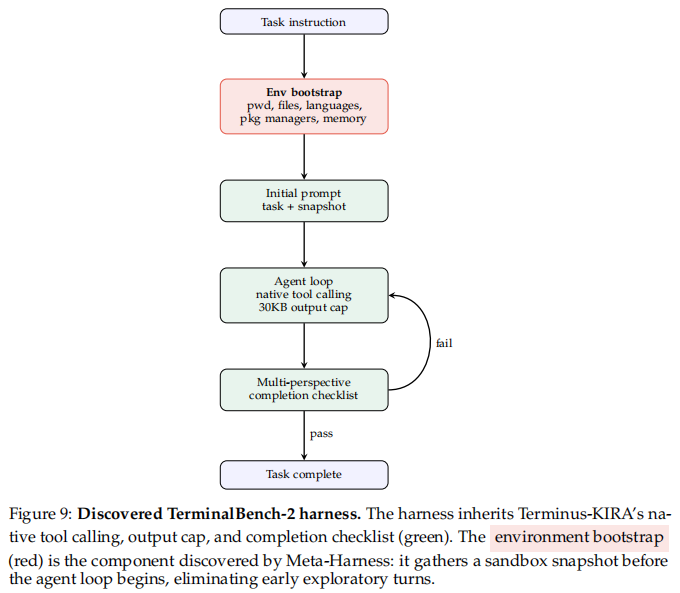
最后是 TerminalBench-2。Meta-Harness 从 Terminus 2 和 Terminus-KIRA 出发进行搜索,在 Claude Opus 4.6 上达到 76.4%,超过 Terminus-KIRA 的 74.7%;在 Claude Haiku 4.5 上达到 37.6%,高于 Goose 的 35.5%。更有意思的是,研究团队展示了 proposer 的搜索轨迹:它发现几次回归都混入了 prompt 改动,主动识别出混杂因素,最后转向更安全的增量改动——在 agent loop 之前加入环境快照——并得到最佳结果。这说明 Meta-Harness 并不是在随机试代码,而是在利用历史失败做因果式归因。
真正拉开差距的,可能不再只是模型本身。
当大模型能力逐渐接近时,真正决定系统上限的,可能不只是参数,而是模型外面那层能否被持续优化的“工作方式”。Meta-Harness 的意义就在这里:它让 harness 从人工经验,变成了可以被自动搜索、自动迭代、自动超越的对象。
从“调模型”走向“调系统”,Meta-Harness 代表的也许正是下一阶段 AI 工程的方向。










