绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
RGB-A 视频就是在普通彩色视频之外,还多了一个“透明度”通道。在游戏设计、影视制作及用户界面开发等创意领域展现出广阔的应用前景。然而,现有方法普遍受困于 RGB 与 alpha 通道的相互混淆,生成质量与透明度效果均难以令人满意。究其根本,核心挑战在于如何有效解耦 RGB 分布与透明度分布,并实现二者的协同学习。
天大研究团队联合提出视频生成模型 Wan-Alpha,一种高质量 RGB-A 视频生成方法,通过在潜空间与噪声空间中平移透明度分布的同时保持 RGB 保真度,实现了稳定且可控的透明度生成。
借助透明度感知扩散损失与均值平移噪声采样策略,所提方法在透明度渲染方面取得了优异效果。实验结果表明,该模型在文本对齐、视觉美感、自然度、运动平滑性及时序一致性等方面均显著优于现有最先进方法。Wan-Alpha 模型、代码已开源,相关论文已被 CVPR 2026 接收。
生成视频

Alpha 视频

 论文标题:Video Generation with Stable Transparency via Shiftable RGB-A Distribution Learner
论文标题:Video Generation with Stable Transparency via Shiftable RGB-A Distribution Learner
论文链接:https://arxiv.org/pdf/2509.24979
主页链接:https://donghaotian123.github.io/Wan-Alpha/
GitHub:https://github.com/WeChatCV/Wan-Alpha
HuggingFace:https://huggingface.co/htdong/Wan-Alpha-v2.0
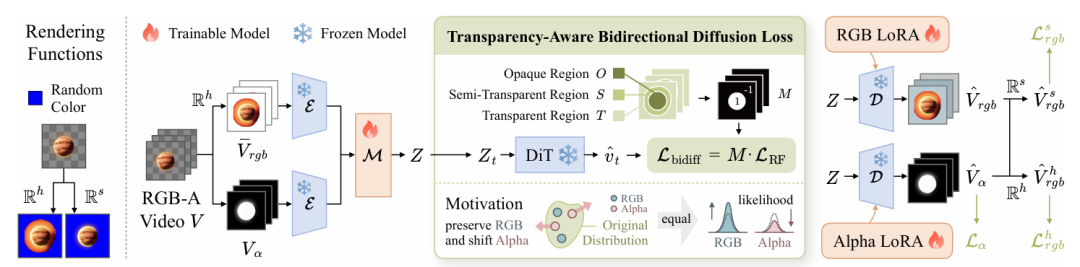
图 1 VAE 的训练框架。
1.可区分的 RGB-A 潜空间学习
Wan-Alpha 整体架构如图 1 所示,以预训练的 Wan2.1-T2V-14B 为基础,将 VAE 扩展为 RGB 与 alpha 共享潜空间,但直接编码易导致特征耦合,引入空洞与伪影。
透明度感知双向扩散损失:为改善潜空间质量,旨在保持 RGB 分布不变的同时平移 alpha 分布。通过引入冻结的 DiT,利用双向扩散损失 以掩码反转透明区域的损失符号,使 VAE 学习到更具区分性的 RGB-A 潜表示。
渲染损失:为增强重建质量,定义了软渲染与硬渲染两种函数,并从预定义颜色集合中随机选取背景颜色进行渲染。
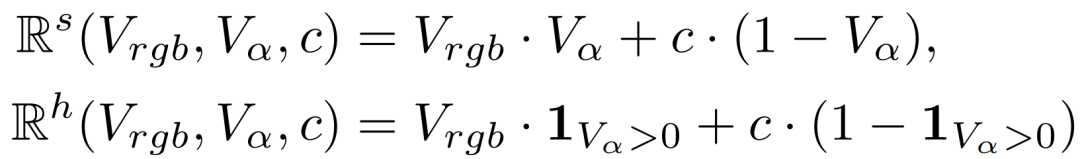
为使模型差异化关注不透明、半透明与透明区域,将结合了像素级、感知与边缘一致性约束的复合重建损失,
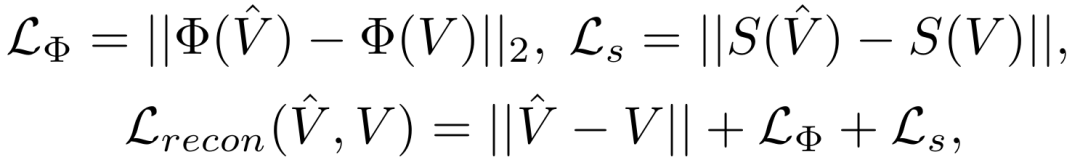
分别应用于 alpha 视频、软渲染视频与硬渲染视频三种模态,共同构成VAE的最终训练目标。
2. 可控的 RGB-A 生成
当将预训练的 RGB 模型适配至 RGB-A 任务时,保留基础模型的生成能力有助于提升性能,但也容易引入非期望的背景。
研究团队提出将透明度先验信息融入高斯噪声。该方法促使视频生成模型更好地区分不透明与透明区域,同时为透明度提供可控的生成机制。
透明度引导的均值采样器:在修正流框架下根据 alpha 视频平移噪声均值,引入高斯椭圆掩码精细控制透明区域的噪声分布。
架构设计如图 2 所示,采用预训练 RGB-A VAE 编码器获取潜变量,结合平移后噪声生成含噪潜变量,DiT 采用 DoRA 训练以提升语义对齐与生成质量。
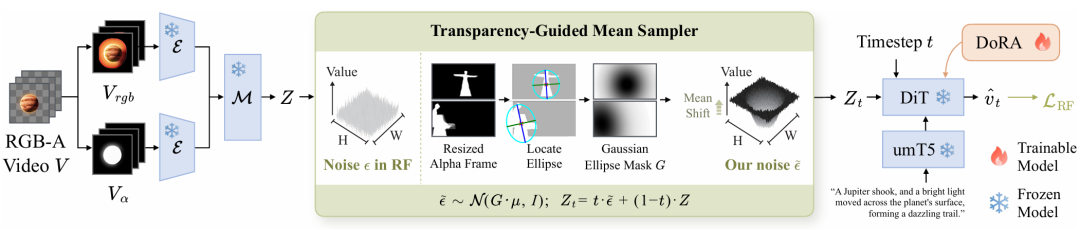
图 2 RGB-A 视频生成训练框架
推理时仅需修改初始噪声与解码器配置,参数可完全合并,无额外开销。借助 LightX2V 加速,仅 4 步采样即可生成高质量结果,推理速度较现有最优方法提升 15 倍。
VAE 训练数据涵盖 10 个图像抠图与 3 个视频抠图数据集,图像数据转换为静态视频后沿时间轴滑动窗口以模拟运动。数据集按 95:5 划分为训练集与验证集,分别包含 77,237 与 4,066 个视频。
RGB-A 视频生成数据源自同批采集,经筛选重点关注运动、半透明对象及光照效果样本,利用 Qwen2.5-VL-72B 生成描述并标注属性标签。最终数据集包含 301 个视频抠图视频、 43 幅图像抠图图像及 85 个互联网特效视频。

图 3 数据集样本示例。
RGB-A 视频生成作为新兴任务,目前仅有 TransPixeler 与 LayerFlow 能够生成 RGB-A 视频。对于 TransPixeler,除开源版本外,还在 Adobe Firefly 上评估其闭源版本。为进行更全面的对比,将 LayerDiffuse 集成至文本到视频模型 AnimateDiff 中。
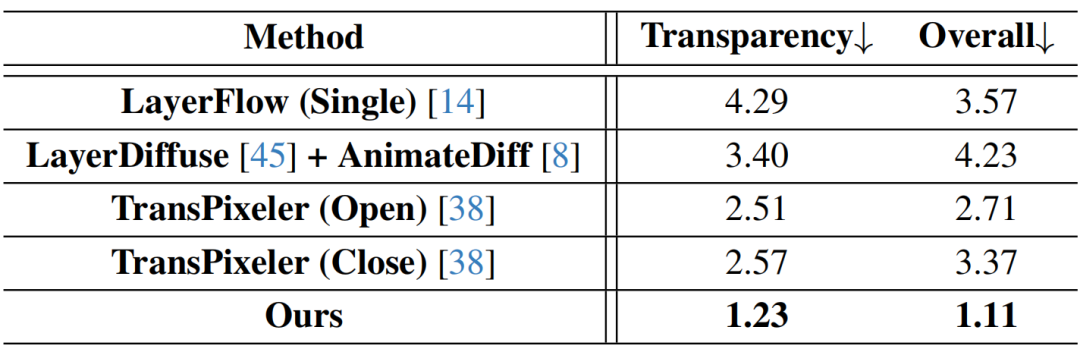
定量结果如表 1 所示,得益于框架设计——保持 RGB 分布以维持基础模型能力,同时平移透明度分布以更好区分透明度——Wan-Alpha 在表 1 的所有定量指标上均取得最优结果。
表 1 与现有 RGB-A 视频生成方法的定量对比结果。


图 4 与现有 RGB-A 视频生成方法的定性对比。
定性结果如图 4 所示。该模型能够生成细腻的发丝、自然的人物动作、逼真的火焰与烟雾,以及准确的透明玻璃与眼镜效果。用户研究结果(表 2)进一步验证了所提模型的优越性。
表 2 用户对透明度正确性与整体质量的排名结果。