绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
智能体强化学习(Agentic RL)已成为云集群核心负载,支撑 LLM 通过外部工具交互解决复杂问题,然而,与传统强化学习不同,智能体强化学习需要大量外部云资源,例如用于代码执行的CPU和用于奖励模型的GPU,这些资源都位于主要训练集群之外。现有的智能体强化学习框架通常依赖静态过度配置,即资源往往与长生命周期轨迹绑定或按任务隔离,导致严重的资源效率低下问题。
为此,小米罗福莉团队联合北京大学提出动作级编排(action-level orchestration)并构建统一资源管理系统 ARL-Tangram,能够实现细粒度的外部资源共享与弹性调度。ARL-Tangram采用统一的动作级表征与弹性调度算法,在满足异构资源约束的同时,最小化动作完成时间。此外,系统还定制了异构资源管理器,以高效支持在具有不同特性与拓扑结构的资源上执行动作级任务。在实际智能体强化学习任务上的评估表明,ARL-Tangram将平均动作完成时间(ACT)最多提升达 4.3×,强化学习训练步长加速 1.5×,外部资源节省 71.2%。该系统目前已部署,用于支持小米 MiMo 系列大模型的训练。
 论文标题:ARL-Tangram: Unleash the Resource Efficiency in Agentic Reinforcement Learning
论文标题:ARL-Tangram: Unleash the Resource Efficiency in Agentic Reinforcement Learning
论文链接:https://arxiv.org/pdf/2603.13019
为解决现有的强化学习框架在外部资源管理上的低效问题,研究团队提出了动作级调度(action-level scheduling),将外部资源管理的粒度从原来的轨迹级或任务级转变为更细粒度的动作级,即原子调用级别。将长生命周期环境/服务的资源占用进行拆解,并将相同资源类型的动作所需资源汇聚成池。此外,该细粒度资源管理支持弹性资源分配,以降低动作的执行延迟
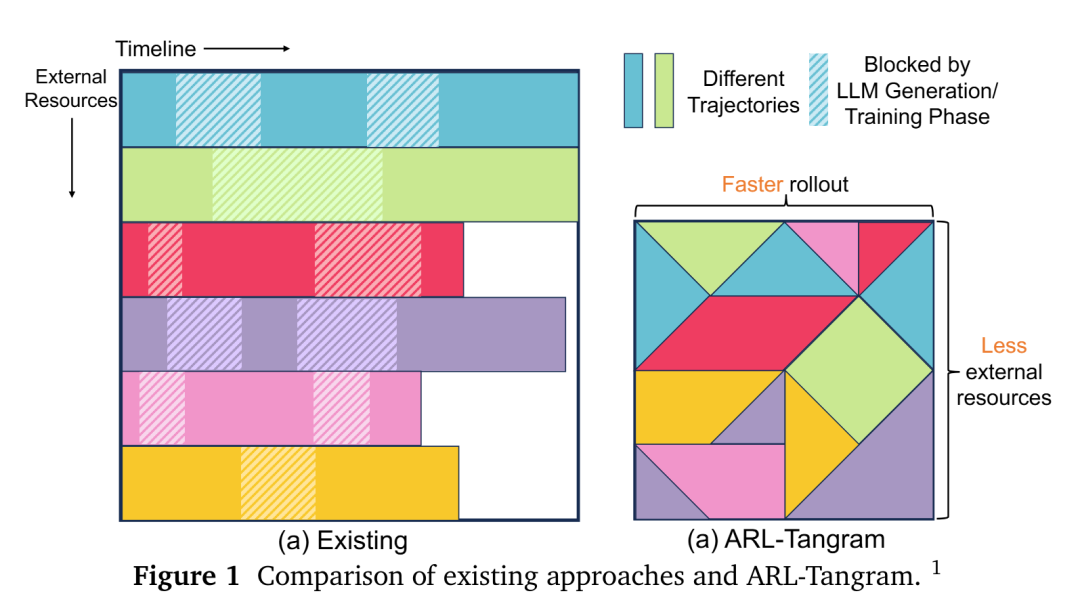
如图 1 所示,在两个 RL 任务和 4 个调用同类外部资源的轨迹上,与现有方法相比,动作级调度通过缓解过度配置减少了外部资源需求,并通过弹性资源分配加快了rollout速度。
然而,实现动作级调度并非易事,主要原因有三点:
首先,编排各种外部资源的动作非常复杂。单个动作可能需要多种资源类型,而各个动作不同的弹性和执行模式进一步加剧了这种复杂性,这就需要一种通用的抽象模型。
其次,调度器必须在延迟敏感的工作负载下运行。留给调度决策的时间窗口极短,这需要一种轻量级算法,能够处理高并发和突发的工作负载。
最后,如何统一且高效地管理具有不同特性和拓扑结构的异构外部资源也是一大挑战。
因此,研究团队设计了动作级资源管理系统ARL-Tangram(Agentic Reinforcement Learning Tangram),旨在对所有外部资源调用进行统一编排。
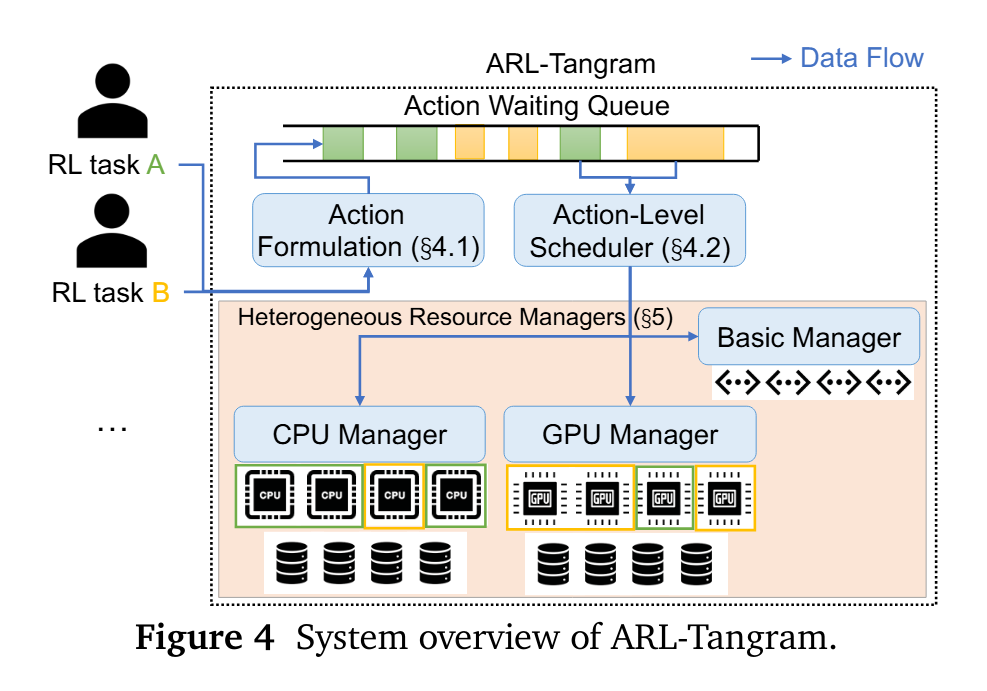
该系统首先通过统一动作表征(unified action formulation)管理具备异构资源需求与成本的各类动作,将每个动作转化为向量化的资源成本表示,该向量涵盖了 CPU、GPU、内存及 API 配额等各类资源约束。
关键在于,这一表征方式融入了弹性建模(elasticity modeling),使系统能够有效区分弹性动作,并计算出为动作分配更多资源时的执行时间降幅。
这种标准化的表征方式,让 ARL-Tangram 可将不同类型的动作统一为标准化格式,从而实现高效调度。
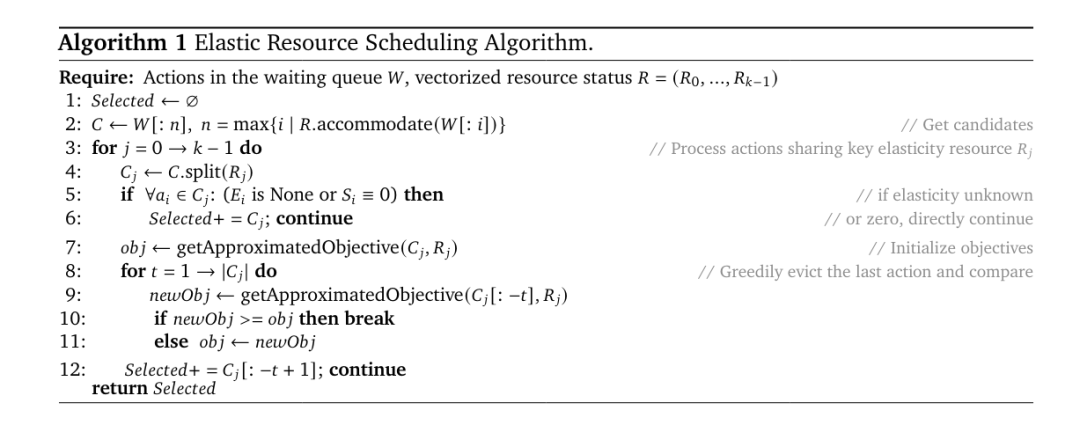
ARL-Tangram 的核心是弹性资源调度算法,其设计目标为最小化动作完成时间(Action Completion Time, ACT)。研究团队发现,缩短动作执行时间能够提升智能体强化学习(RL)训练的端到端效率,因此基于上述动作表征方法与系统实时状态,设计了一种启发式调度算法,该算法内置贪婪驱逐机制(greedy eviction mechanism),可动态制定调度策略,避免了因分配过于激进或保守,而导致次优的 ACT 和强化学习训练效率下降。
ARL-Tangram 是一款独立部署的系统,不依赖于特定的强化学习(RL)框架、外部调用类型及外部资源类型。这一设计使其能够适配各类外部资源,且可跨不同 RL 框架运行,兼具良好的通用性与易用性。
图6展示了在不同工作负载下,随着强化学习训练的推进,连续小时间窗口内的平均动作完成时间(ACT)变化。观察发现,ARL-Tangram下的ACT始终低于基线方法。这一结果表明,在相同外部资源条件下,ARL-Tangram能更有效地处理突发性工作负载,通过缓解过度配置和提升外部资源利用率来降低ACT。
研究团队进一步报告了10个强化学习训练步骤的平均时长(简称步骤时长),以此说明ARL-Tangram对端到端训练效率的提升作用。AI Coding与DeepSearch的步骤时长均显著下降,分别提升了1.4×和1.5×。
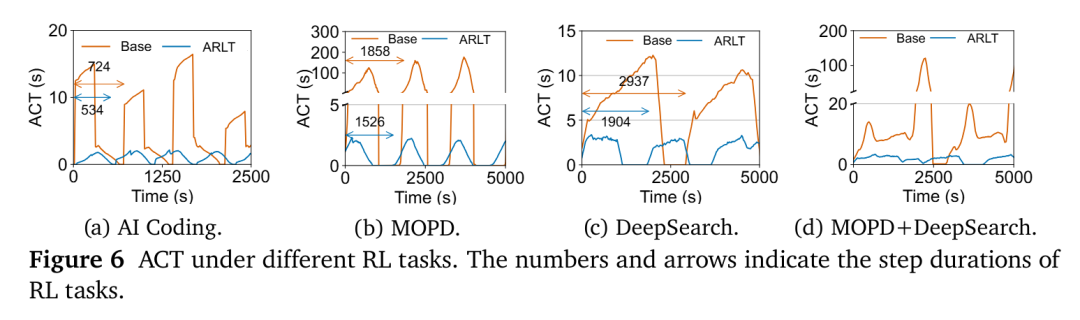
图7详细展示了轨迹时长的分解情况,进一步说明了ARL-Tangram在外部调用方面带来的改进。在AI Coding任务中,环境交互时长与奖励计算时长均显著减少,分别降低了 9.0×和 2.8×,总体降低了 4.3×。
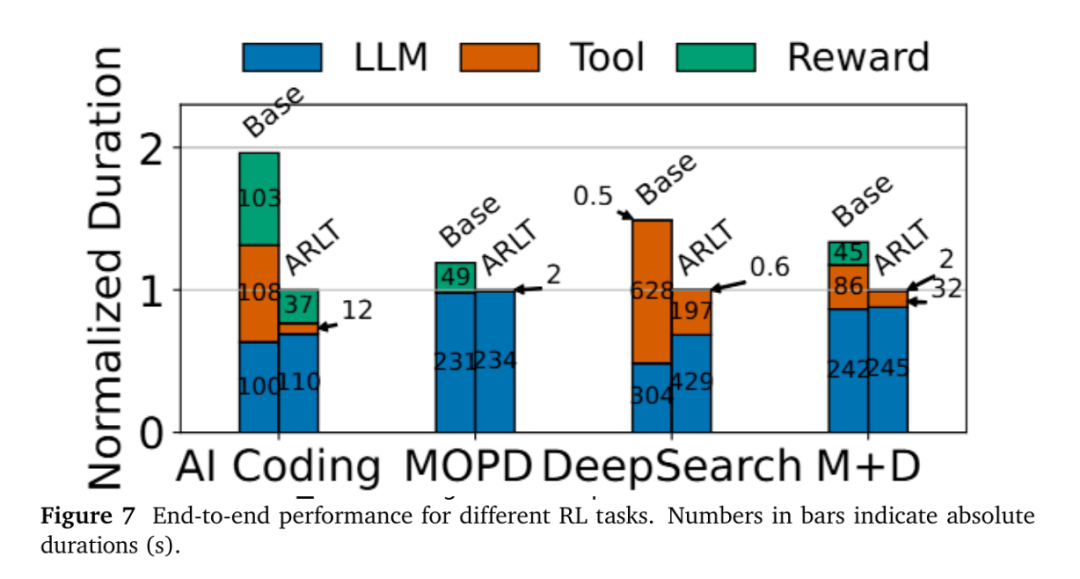
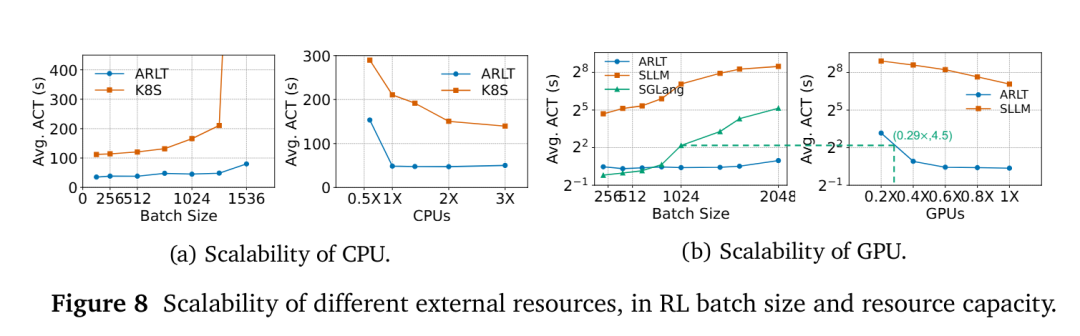
图8(b)右侧进一步突出了ARL-Tangram在固定批次大小(batch size)为1024的情况下降低外部资源成本的优势。ARL-Tangram仅需使用过度配置(over-provisioned)基线系统所需GPU数量的 29%,即可支持10个奖励服务,并实现相同的行动完成时间(ACT)。