绑定手机号
确认绑定









智猩猩AI整理
编辑:宁宁
给大模型智能体配备特定技能(skills),正在成为提升复杂任务表现的一条重要路线。然而,人工写技能扩展性太差,任务一多、模型一换,就得重新维护;而只靠模型参数知识自动生成的技能,往往又太空泛,难以真正解决复杂场景中的具体问题。
为此,阿里Qwen团队联合苏黎世联邦理工学院等高校研究者们提出了一个智能体技能自动生成框架Trace2Skill。它想解决的核心问题是:经验能否被蒸馏为可迁移的、声明式的skills,而不依赖参数更新或外部检索模块。 实验结果表明,这种基于轨迹的技能演化不仅能够提升技能质量,而且不会牺牲泛化性。演化得到的技能可以跨模型规模迁移,也能泛化到分布外任务。例如,由 Qwen3.5-35B 基于自身轨迹演化出的技能,可使 Qwen3.5-122B 在 WikiTableQuestions 上最高提升 57.65 个百分点。

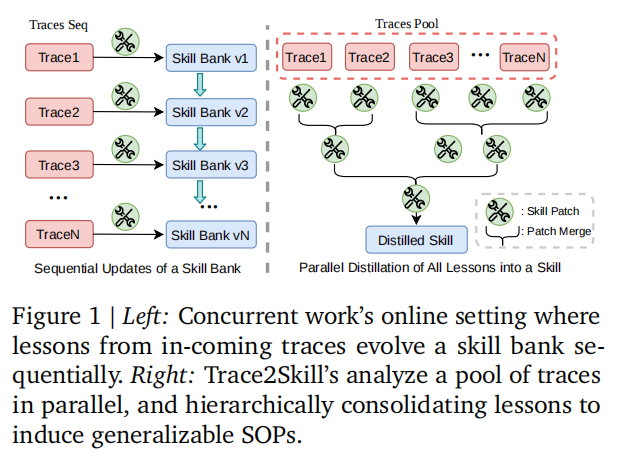
现有方法通常顺序更新 skill bank,而 Trace2Skill 改为并行分析多条轨迹,再统一蒸馏成一份技能。
Trace2Skill的出发点很明确:很多经验学习方法本质上仍在顺序处理轨迹,新轨迹来了,就抽一条 lesson去改技能库。问题是,这样容易把技能越改越碎,也容易受到更新顺序影响,对局部经验过拟合。因此,研究团队提出要把“顺序更新”改成“整体归纳”,尽量模拟人类专家写SOP的方式:先看大量案例,再总结成统一规则。
Trace2Skill 三阶段流水线概览。如下图2所示。
阶段 1:冻结的智能体 使用初始技能 (可由人工编写,也可由 LLM 起草)在不断演化的数据集上进行 rollout,生成带标签的轨迹 (失败轨迹)和 (成功轨迹)。
阶段 2:并行的错误分析器和成功分析器分别独立处理单条轨迹,并提出技能补丁(skill patches)。
阶段 3:通过归纳推理并结合程序化冲突预防机制,将所有补丁合并为一次统一的整合更新,得到演化后的技能 ,从而提升性能与泛化能力。
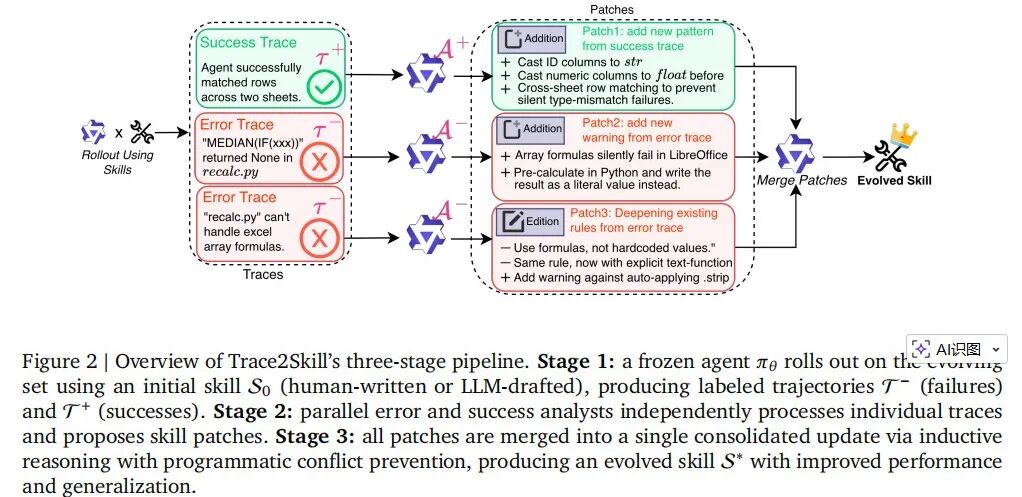
如上图所示,Stage 1收集成功/失败轨迹,Stage 2并行生成skill patches,Stage 3分层合并为新的技能目录。
论文主实验聚焦 spreadsheet 场景,使用 SpreadsheetBench-Verified 做演化和测试,并用 WikiTableQuestions 做 OOD 评估;此外还验证了数学推理和 DocVQA,考察这套方法是否具有跨任务泛化能力。如表1所示。
首先,研究团队给了两个关键基线。
其一是 Anthropic 官方的人类编写 xlsx skill,它对122B很强,在 SpreadsheetBench-Verified 上达到 48.33%,在 WikiTQ 上达到 74.68%;但它不具备稳定的跨模型迁移性,到了35B上反而比 No Skill 还差。
其二是模型只凭参数知识写出的 parametric skill,整体几乎接近 No Skill,说明“让模型凭常识胡写一份技能”收益非常有限。
在 Deepening 模式下,如果从人类已有 skill 出发继续打磨,收益很稳。以122B作为 skill author 时,Deepening +Error 在 SpreadsheetBench Vrf 上提升 17.5 个百分点,+Combined 提升 21.5 个百分点;而且这种收益还能迁移给别的模型,比如 122B 演化出的 Deepening +Error 给35B使用时,Vrf 还能提升 27.0 个百分点。在 OOD 的 WikiTQ 上,Deepening +Error 和 +Combined 也分别有 1.6 和 4.6 个百分点 的提升。
在 Creation 模式下,结果更亮眼。研究团队从一个几乎等于 No Skill 的 parametric 草稿出发,看轨迹蒸馏能否“从零长出技能”。
答案是可以:在SpreadsheetBench Vrf 上,122B-authored的Creation+Error提升22.83个百分点;其中最吸睛的是 35B-authored Creation +Error,当这份 skill 拿给122B使用时,在 WikiTQ 上直接提升 57.65 个百分点,达到 81.38%,甚至超过了人类写技能的表现。
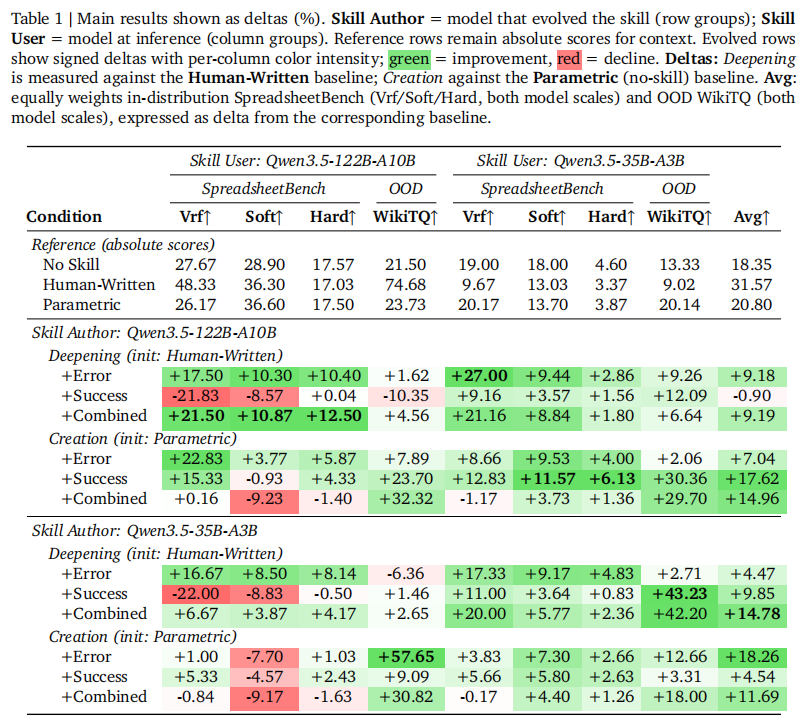
注: 最亮眼结果来自 35B-authored Creation +Error:
给122B使用时,WikiTQ提升57.65个百分点。
这套方法并不只对表格任务有效。数学推理实验中,122B-authored +Error skill 可让122B在 DAPO-Math-Test-100 上提升 3.0 个百分点、在 AIME 2026 上提升 2.9 个百分点;迁移给35B后,这两个指标都还能提升 5.0 个百分点。在 DocVQA 上,研究团队还发现一个很有意思的现象:“会做题”不等于“会写技能”。35B本身在 No Skill 条件下甚至比122B更强,但它并不是更好的 skill author;相反,122B-authored +Error 能同时显著提升122B和35B的表现。如表2、表3所示。
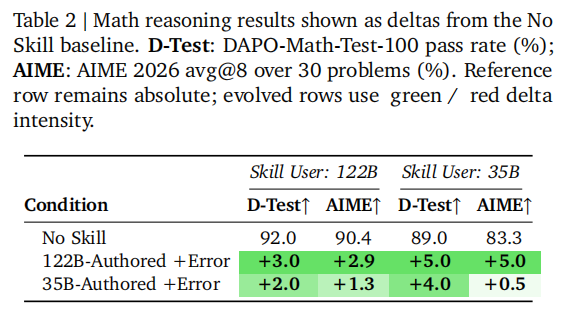
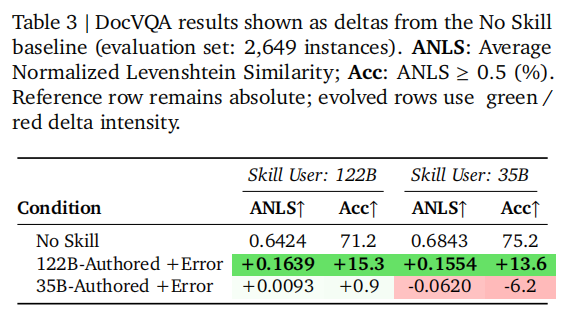
注: Trace2Skill 在数学推理和 DocVQA 上也有收益,
说明它不是 spreadsheet 专用技巧。
研究团队还做了几组很关键的分析。如表4、表5所示。
并行 consolidation 比顺序编辑更优:在122B上,Parallel 方案耗时约 3分钟,而 Seq-B=4 约 15分钟,Seq-B=1 约 60分钟,而且指标也更高。
统一的 skill 文档可能比 retrieval memory 更有效:与 ReasoningBank 对比时,Trace2Skill 在122B和35B上都取得更高结果。
agentic error analysis 确实比单次 LLM 总结更可靠,因为它能读 artifact、对 ground truth、验证修复,而不只是基于日志“猜原因”。
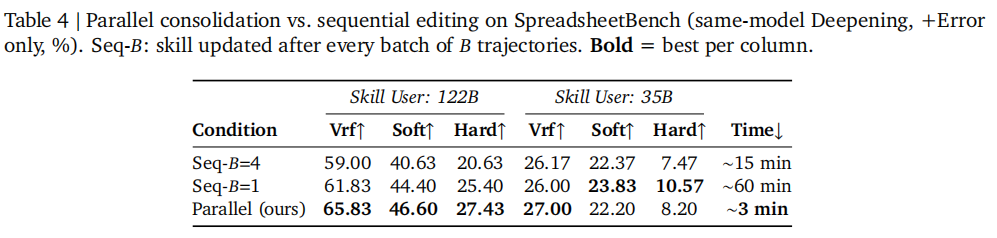
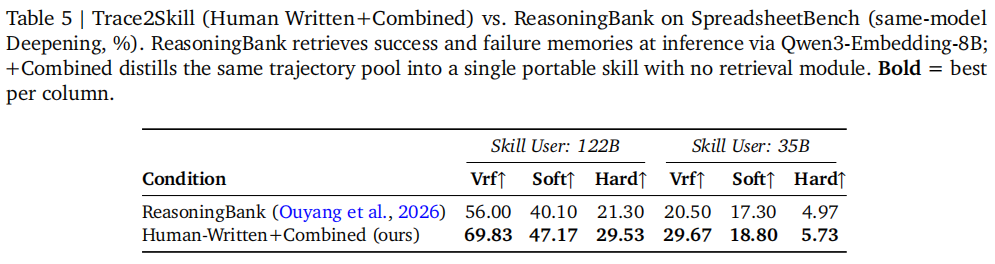
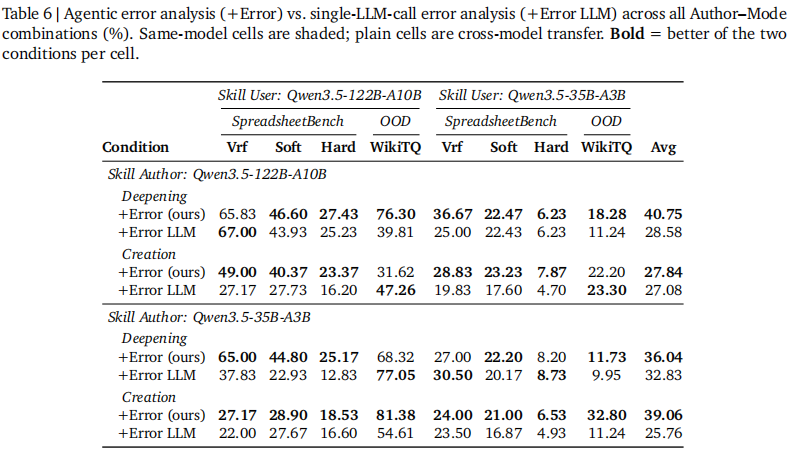
注: Trace2Skill 不仅比顺序更新更快,
也优于基于检索的经验库方案;
多轮 agentic 失败分析也明显优于单次 LLM 总结。
总之,Trace2Skill 不是简单地做“经验回放”或“自动写技能”,而是提出了一种新的技能生成范式:与传统方法沿着单个轨迹依次顺序更新技能不同,Trace2Skill会调度一组并行的分析性子智能体,从互不关联的轨迹批次中提出针对性的编辑补丁;随后,通过归纳推理和程序化冲突预防机制,将所有提案同时整合为一个连贯统一的技能目录。










