绑定手机号
确认绑定









智猩猩AI整理
编辑:六六
世界模型使人类或智能体能够与生成式环境进行交互。Cosmos、HY-World 以及Genie系列的出现显著推动了该领域发展,充分展现了基于视频的世界模型对人工智能基础研究和生成式媒体应用的深远影响。
尽管潜力巨大,当前开源的基于视频的世界模型方案仍主要局限于预训练阶段。现有方法通常依赖原始视觉数据的像素级监督,以隐式方式学习遵循输入动作,难以在交互式长时程生成中保持准确性和一致性,亟需新的训练范式来突破这一局限。
针对上述挑战,浙江大学联合腾讯混元研究团队提出了WorldCompass——一种专为“引导”世界探索而设计的强化学习框架。该框架的核心思想是引入强化学习,基于交互信号更直接地引导模型探索世界;为此,研究团队针对世界模型的自回归、交互式及长时程生成范式,对强化学习的各阶段进行了系统性重新设计,旨在赋予模型更高的生成准确性与时序一致性。

论文链接:https://arxiv.org/pdf/2602.09022
论文标题:WorldCompass: Reinforcement Learning for Long-Horizon World Models
01 方法
为将强化学习应用于自回归、交互式及长时程的基于视频的世界模型,需解决以下挑战:
如何为自回归视频生成模型生成采样轨迹?
如何设计可靠评估交互式生成的奖励函数?
如何高效地使用强化学习优化世界建模?
针对上述挑战,研究团队从采样策略、奖励机制与优化效率三个维度提出了强化学习框架WorldCompass ,如图 1 所示。

图 1 WorldCompass 框架概述
1. 面向自回归生成的片段级展开策略
研究发现,序列级展开方案从根本上不适用于自回归视频生成,核心问题在于反馈信号过于稀疏:单一的整体奖励无法精准定位动作偏离或质量下降的具体片段。
针对此问题,研究团队制定了专门面向自回归视频生成的片段级展开策略。给定语义文本或图像条件 、动作条件序列 以及待展开的目标片段索引 ,首先自回归生成前 个片段。随后,为第 个目标片段生成 个候选展开样本。在第 个片段处,第 个样本的生成过程及其奖励评估可形式化如下:
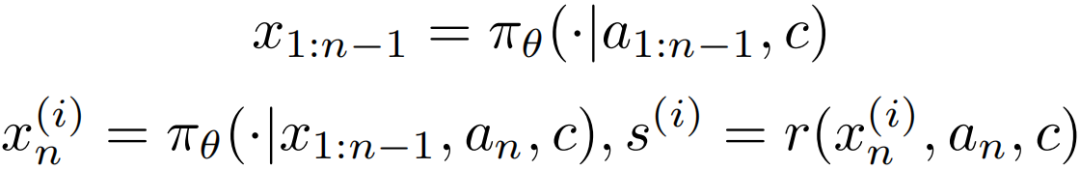
片段级展开策略具有两个关键优势:
1)展开效率:前 个片段仅需采样一次并重复使用,模型只需针对第 个片段执行 次重复采样。计算复杂度由 降至 ,显著提升了采样效率。
2)一致且细粒度的奖励:基于相同历史观测生成展开样本,避免前缀差异带来的不一致性;并在相同上下文中评估,获得粒度更细、可比性更强的奖励信号,使优化更聚焦于当前生成质量。
上述优势使得模型能够更有针对性地优化以合成高保真片段,确保梯度更新由当前生成质量驱动,而非历史信息差异所主导。
2. 面向交互式生成的奖励函数
在交互式视频生成任务中,奖励设计重点关注两个核心属性:交互跟随能力与视觉质量。为此,分别为每个采样片段设计了专门的奖励函数。
交互跟随分数:该指标衡量生成片段是否遵循给定的动作条件。参照Genie 3等研究工作,动作信号被分解为平移与旋转两个分量。
为评估动作执行情况,采用先进的3D基础模型估计生成片段中的相机轨迹,并将其映射至预定义离散动作空间,以计算动作遵循准确率。
1)旋转动作:通过比较相邻帧间相对相机旋转量与预设阈值判断动作是否正确。
2)平移动作:由于检测位置尺度随场景变化,单一通用阈值难以适用,因此设置多个平移阈值;只要在任一阈值下平移动作与条件输入匹配,即判定为正确,从而确保跨场景评估的鲁棒性。
最终,分别计算旋转准确率与平移准确率,并将二者均值作为交互跟随分数,以提供更具区分度的优化引导。
视觉质量分数:采用 HPSv3 作为奖励模型评估生成视频的视觉逼真度。该模型同时评估文本-视觉对齐程度与美学质量。
上述两个奖励函数可互为约束:通过平衡这两个优化目标,框架能有效防止模型因偏执一端而牺牲另一端,从而抑制奖励破解,实现更稳健的训练。
3. 高效的强化学习优化
受DiffusionNFT启发,研究团队采用负感知微调策略进行策略优化:从不同初始噪声中采样展开数据,并直接以流匹配目标函数训练模型。
给定第 个视频片段的 个样本 ,及其对应的交互跟随分数 和视觉质量分数 ,首先计算每个奖励维度的优势函数:

随后,通过对两个归一化后的优势进行带裁剪的线性组合,推导出第 个样本的最优性概率:
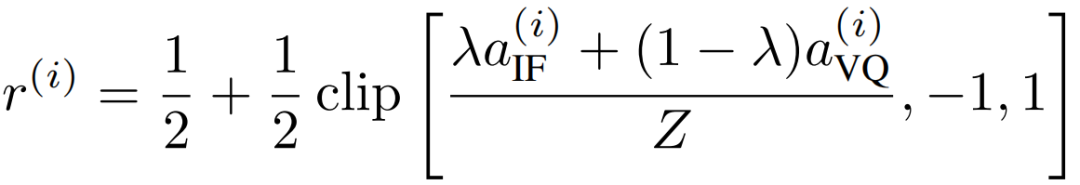
最终的优化损失函数定义为:
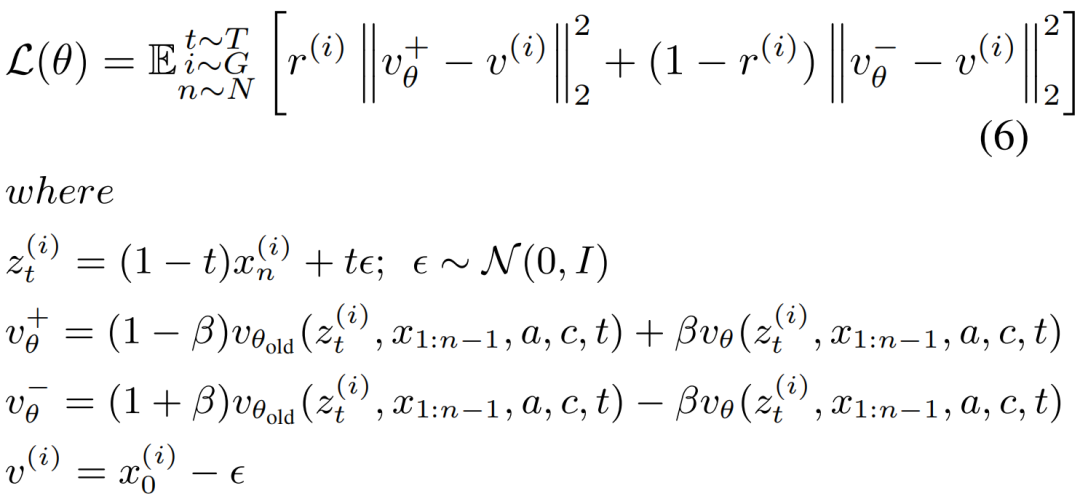
值得注意的是,原版 DiffusionNFT 中使用的KL散度损失在本研究中被省略。取而代之的是,采用较低的学习率和指数移动平均更新策略来防止过优化,从而获得更优的最终结果。
高效训练策略:上述优化过程需遍历扩散采样时间步 、展开样本数 和最大片段长度 ,这一过程计算密集且耗时。为此,采用以下加速策略:
1)针对采样时间步 :每轮迭代从去噪轨迹中随机选取时间步子集,而非处理全部 步,在保证性能的前提下显著降低了计算开销。
2)针对展开样本 :采用Best-of-N策略,仅选取奖励排名前3和后3的样本用于训练,通过聚焦高信息价值样本(高奖励用于强化、低奖励用于纠错)提升训练效能。
3)针对片段长度 :实施渐进优化策略。目标片段索引 从 1 到 循环递增(如算法1第3行所示)。这种调度方式自然引入了课程学习效应,逐步延长任务长度以契合强化学习原则;同时,保持各并行节点视频长度统一,最大化硬件利用率与采样效率。

02 评估
研究团队采用WorldPlay作为基础世界模型进行评估,并选取其两个变体HunyuanVideo-1.5-8B与Wan2.2-5B进行严格验证。这些模型支持八种基本动作:前、后、左、右平移,以及上、下、左、右旋转。上述基本动作可组合为复合动作。
1. 定量结果
图 2 展示了整个强化学习训练过程中奖励分数的演变。值得注意的是,该方法在极少的训练步数内,即在具有挑战性的动作输入上实现了交互跟随与视觉质量的双重显著提升。
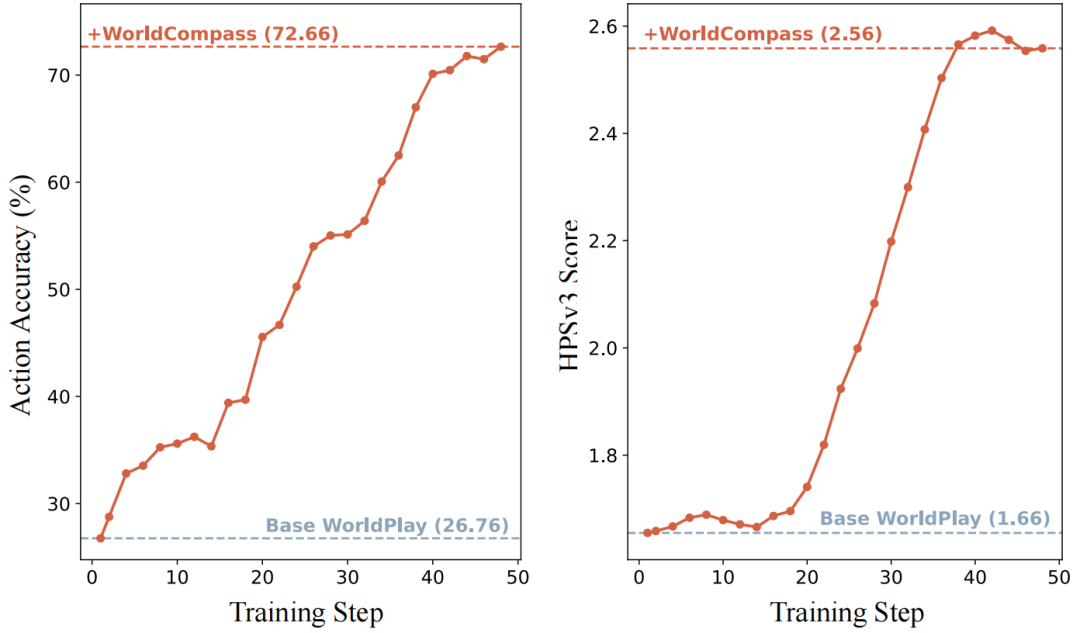
图 2 WorldPlay(HunyuanVideo-1.5)在强化学习训练过程中,交互跟随分数与视觉质量分数的演化过程。
为贴近真实应用场景,将各测试样本的动作控制序列划分为基本动作与复合动作两类。为全面评估模型在不同条件下的表现,在短(约 125 帧)、中(约 253 帧)、长(约 381 帧)三种视频长度上测试不同模型变体。采用4帧采样间隔,计算所有生成片段的平均动作跟随准确率与 HPSv3 视觉质量分数。
表 1 两个WorldPlay版本的定量结果:HunyuanVideo-1.5-8B(与Wan2.2-5B。 对不同场景下两种模型变体的性能进行了对比:1)基础模型;2)经过WorldCompass后训练的模型。
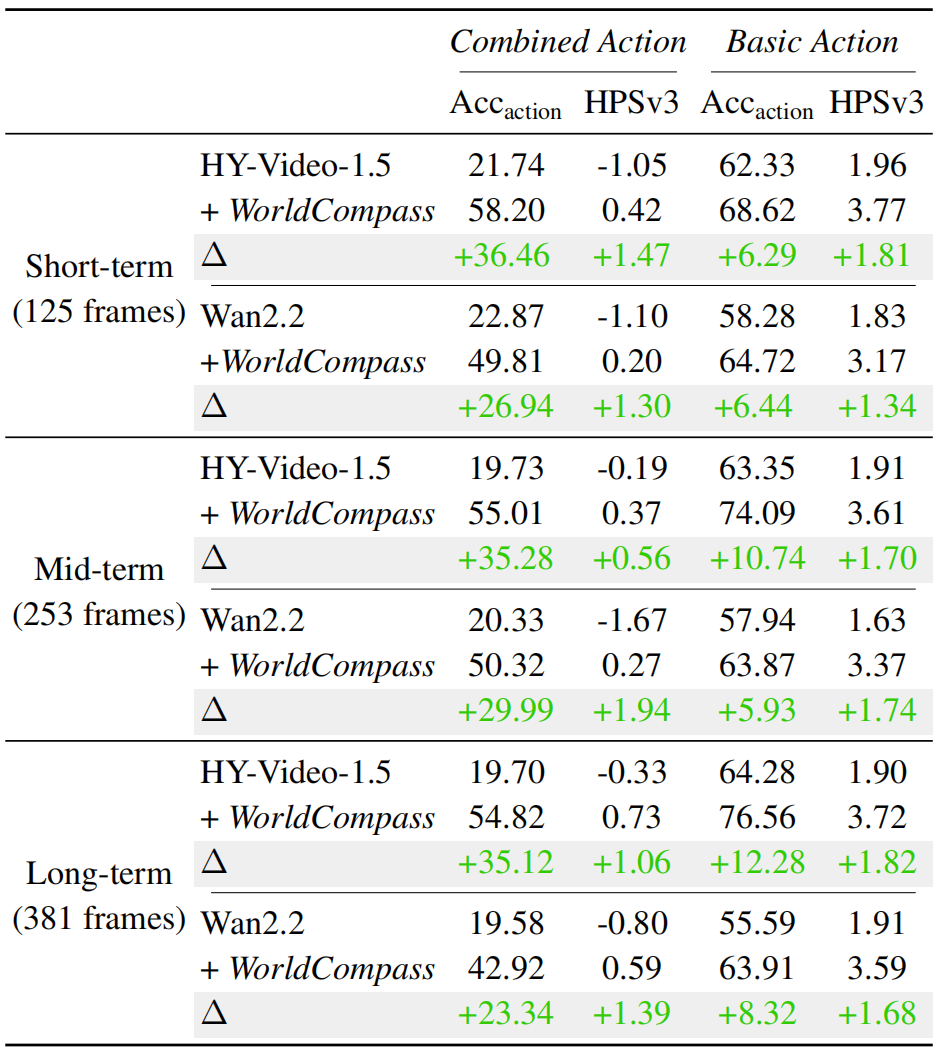
表 1 提供了全面的对比分析,WorldCompass在不同基础模型版本和不同视频长度下均带来了实质性的性能提升。具体而言,对于复杂的复合动作输入,该方法将平均准确率从约20%提升至55%;对于基本动作输入,交互准确率提高了10%。除了实现更优的交互跟随性能外,强化学习训练还提升了生成视频的整体视觉质量。
2. 定性结果

图 3 复杂复合动作序列下的定性比较

图 4 简单基本动作序列下的定性比较
图 3 和图 4 分别提供了针对复杂复合动作和简单基本动作序列,在有和无强化学习训练下的生成结果视觉对比。定性结果与定量发现相一致:WorldCompass后训练框架显著增强了模型遵循交互的能力,同时改善了视觉质量。










