绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
腾讯AI Lab副主任、杰出科学家俞栋近期因个人发展原因离职的消息,迅速在AI圈内传开。俞栋2017年从微软加入腾讯,近八年时间里带领团队在语音、自然语言处理、多模态等领域产出数百篇顶级论文与百多项专利,也深度参与了混元大模型的早期研发和技术推动。他的离开,被外界解读为腾讯AI“新老交替”加速的一个信号。
而就在离职消息传出前后不久,俞栋团队的最后一篇工作——Locas,该成果是针对测试时训练痛点的新型参数化记忆方案!

论文标题:Locas: Your Models are Principled Initializers of Locally-Supported Parametric Memories
论文链接:https://arxiv.org/pdf/2602.05085
现在的测试时训练(Test-time training,TTT)研究逐渐分为两个分支: 以Nested Learning为代表的全新模型架构,和以TempLora为代表的利用Lora模块作为记忆载体的架构。后者最大的优势在于直接用于已有大模型,其中主模型负责通用能力,Lora模块负责记忆上文。但 TempLora 反向传播训练的计算开销和“灾难性遗忘”一直是痛点,记忆准确性与模型智商的跷跷板问题难以解决。
为解决上述问题,TempLora原班人马,腾讯AI Lab俞栋团队提出了 Locas(Locally-Supported Parametric Memory)。该模块利用模型激活态和参数进行原则性初始化(principled Initialization),实现记忆的即时构建,收敛极快, 无需反向传播。此外,Locas 采用 Sideway FFN,完全不改动主模型参数,MMLU 通用能力近乎无损。仅需 0.02% 额外参数,在 LoCoMo 长对话事实检索中表现远超 TempLora。
01 方法
大型语言模型(LLM)的测试时适应(Test-time adaptation)是可靠部署的核心问题,现有方法存在明显短板:非参数化的上下文学习(ICL)和检索增强生成(RAG)完全依赖注意力机制,受上下文长度、提示词格式限制,导致可控性差;参数化的测试时训练虽能内化新信息,但需多次梯度迭代,计算开销巨大,且易引发分布偏移与灾难性遗忘。

如上图所示,研究团队通过一种新型参数化记忆模块 Locas 来应对测试时训练存在的挑战,该模块作为侧向 FFN 模块集成在 Transformer 层中,与主干 FFN 并行运行,其输出经过缩放后(scaled)添加到主路径中。这种设计使得模型能够在测试时真正扩展其容量,同时保留主干模型的预训练表征。
研究团队设计了 Locas-MLP 和 Locas-GLU 两种变体,以适配不同模型架构。

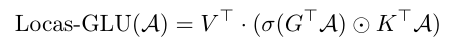
对于 Locas-MLP 变体,其逐层参数化记忆的规模会随着已记忆 token 数量的增加而线性增长。为此,研究团队将传统的 SVD 算法推广到两层非线性情形,提出用于压缩 Locas-MLP 变体的 NL-SVD 算法,以保留主要激活行为的同时降低潜在维度。

02 评估
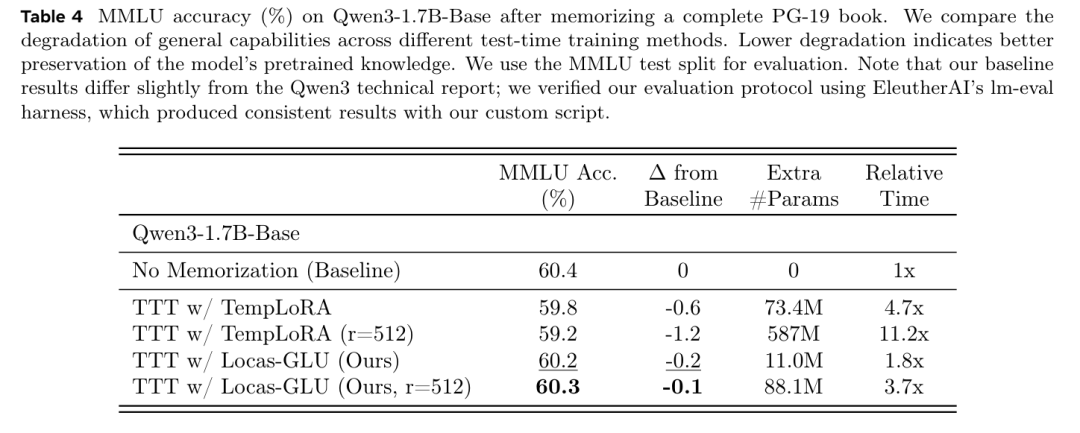
表 4 表明,与 TempLoRA 相比,Locas-GLU 表现出的灾难性遗忘显著更少。
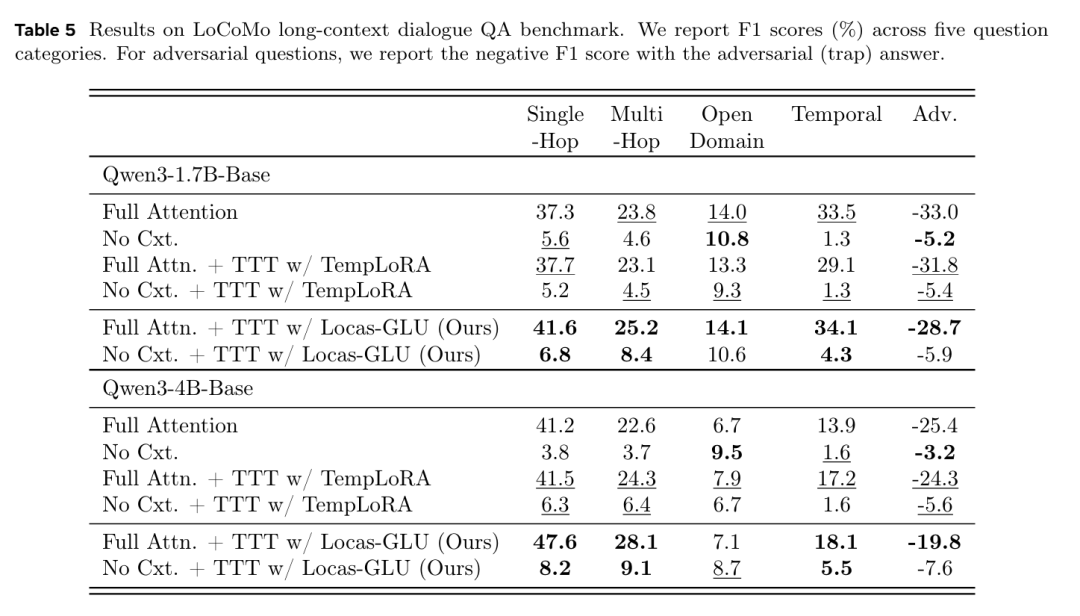
在 LoCoMo 长对话事实检索上的评估如表5所示,可以发现:
Locas-GLU 在大多数问题类型上持续优于两个基线。
在配备全注意力上下文的 Qwen3-1.7B-Base 模型上,Locas-GLU 在单跳问题上取得了 41.6% 的 F1 分数,而普通全注意力基线为 37.3%,TempLoRA 为 37.7%,相对提升分别为 11.5% 和 10.3%。在多跳问题上也观察到了类似的提升(25.2% vs. 23.8% 和 23.1%),这表明 Locas 能有效记忆事实并支持基于这些事实的组合推理。在Qwen3-4B-Base 模型上增益更为显著,Locas-GLU 在单跳问题上达到了 47.6%(比全注意力基线高出 15.5%)。
参数化记忆显著提升了时间推理能力。
在 Qwen3-1.7B-Base 上,Locas-GLU 在时间问题上的 F1 分数为 34.1%,而 TempLoRA 为 29.1%,这表明侧向记忆架构能更好地保留事件的时间序列结构。在 Qwen3-4B-Base 上,这一提升更明显(Locas-GLU 为 18.1%,而 TempLoRA 为 17.2%,全注意力基线仅为 13.9%),证明了大模型能更有效地利用记忆中的时间信息。
Locas-GLU 提升了对抗性鲁棒性。
虽然所有方法都表现出一定的对抗性问题易感性(负 F1 分数表明模型有时会落入陷阱答案),但 Locas-GLU 展现了更强的鲁棒性。在 Qwen3-4B-Base 上,Locas-GLU 的对抗性 F1 分数为 -19.8%,优于全注意力基线的 -25.4% 和 TempLoRA 的 -24.3%。这表明参数化记忆有助于将模型锚定在事实正确的信息上,不易被误导性上下文带偏。
无上下文评估揭示了参数化记忆的保留能力。
在没有任何对话上下文的情况下进行评估(见表 5 中的 "No Cxt." 行),Locas-GLU 持续优于 TempLoRA,尤其是在多跳问题上(Qwen3-1.7B-Base 上为 8.4% vs. 4.5%,Qwen3-4B-Base 上为 9.1% vs. 6.4%)。这表明 Locas-GLU 能更有效地将对话事实内化为持久的参数化记忆,即使无法访问原始上下文也能进行回忆。在时间问题上的差距(Qwen3-1.7B-Base 上为 4.3% vs. 1.3%)进一步验证了研究团队的侧向架构能更好地捕捉时间关系。










