绑定手机号
确认绑定









智猩猩AI整理
编辑:汐汐
3月24日,Google Research重磅放出TurboQuant论文和博客,宣称通过PolarQuant + Walsh-Hadamard旋转,实现KV Cache最高6.4x极致压缩,几乎零质量损失,同时注意力计算速度最高8x提升。消息一出,全球内存芯片股集体跳水,Micron、Samsung、SK Hynix等股价重挫,市场担心“AI内存需求崩盘”。
然而,Google只发论文、不放代码与实现,留下一堆质疑声。真实落地效果如何?跨模型跨硬件鲁棒性怎样?就在行业还在观望时,一个个人开发者Tom Turney站了出来。
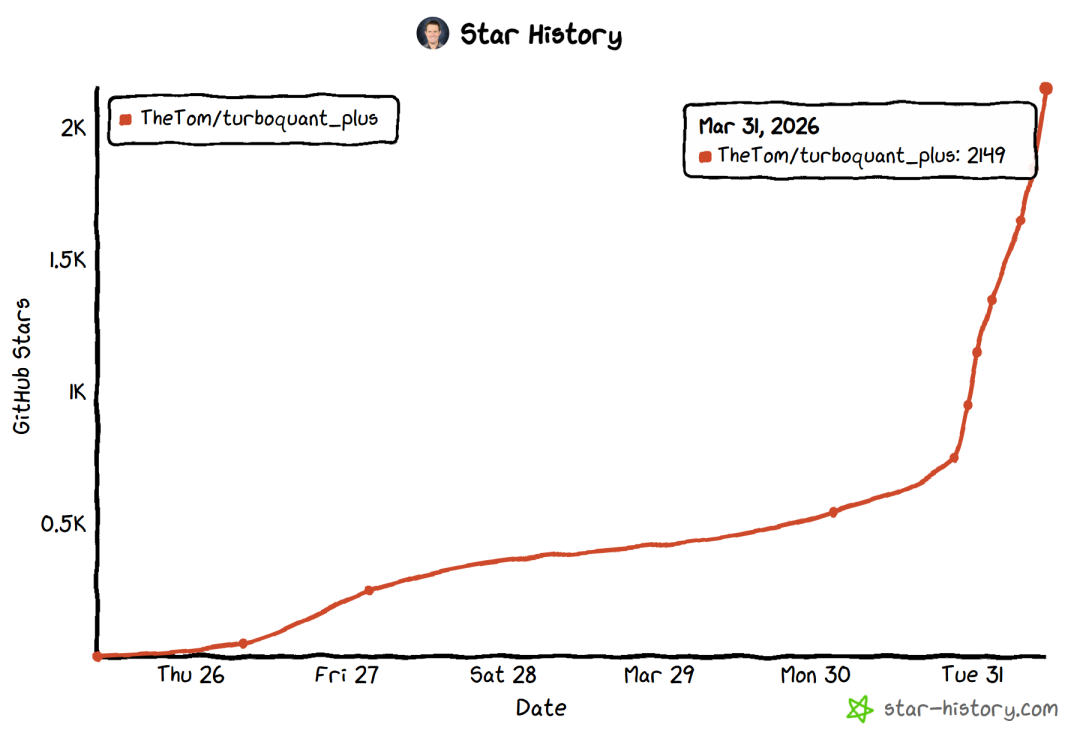
他仅用7天,就用Claude辅助,从论文数学公式出发,完整复现并超越原版,打造出turboquant_plus。GitHub短短5天不到就冲到2K stars(目前仍在疯涨)。
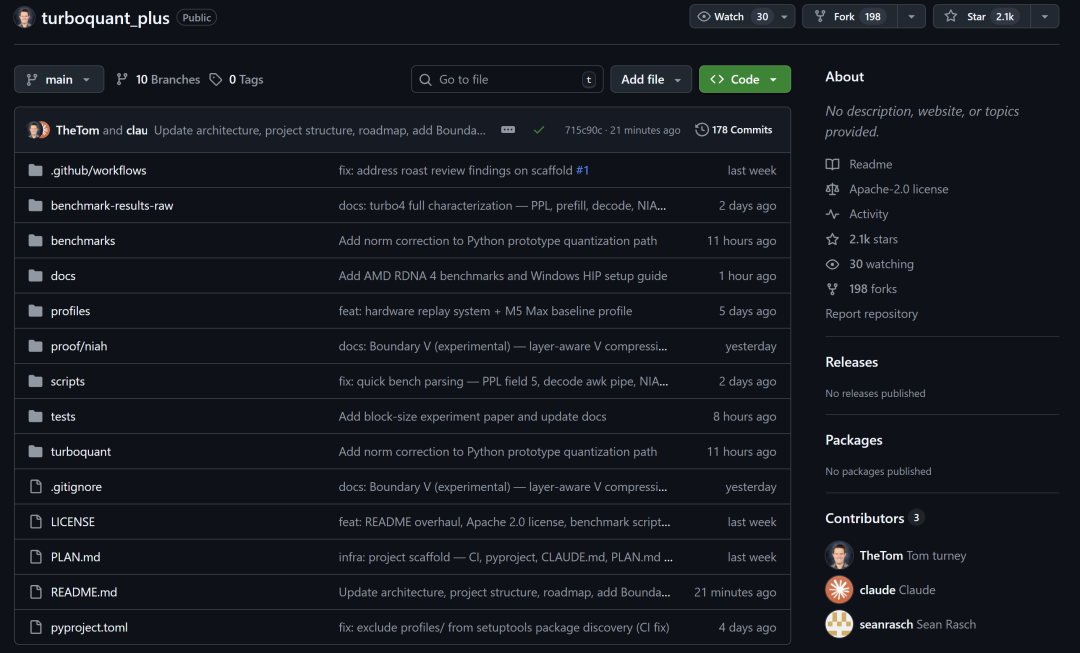
一个个人开发者,利用AI工具,仅仅一周时间,就在大厂研究与生产级裂地之间,硬生生撕开一条裂缝。
github仓库地址:https://github.com/TheTom/turboquant_plus/tree/main
Tom Turney(前Xoogler,现独立开发者)详细记录了整个过程:

视频中,Qwen3.5-35B-A3B MoE模型在MacBook上流畅运行,压缩后KV Cache仅占原先1/4.6,上下文轻松突破32K,长上下文预填充+解码丝滑无卡顿,现场展示Sparse V开启后的提速效果。
他不仅100%还原了Google的PolarQuant + WHT旋转,还在“Plus”层面加入了自己的研究:
整个过程公开透明,commit记录清晰可见,从3月24日项目启动,到3月30日Metal内核优化完成,真正做到“7天从0到生产可用”。

根据Github中的完整benchmark(M5 Max 128GB,Qwen系列模型,wikitext-2等测试集),加速数据如下:
在MacBook上实测,对全系Apple Silicon友好:
其Github仓库的README部分总共有约20个表格,具体内容可查看链接:
https://github.com/TheTom/turboquant_plus/blob/main/README.md
该仓库以及帖子发布后,截至目前已经产生了百万次浏览量,以及超七千次点赞和转发,同时大量网友和开发者的讨论。
Tom Turney本人最新发帖,宣布社区实现已在Apple Silicon/NVIDIA/AMD全平台跑通,附build指令和benchmark链接,强调“30+测试者已验证”。
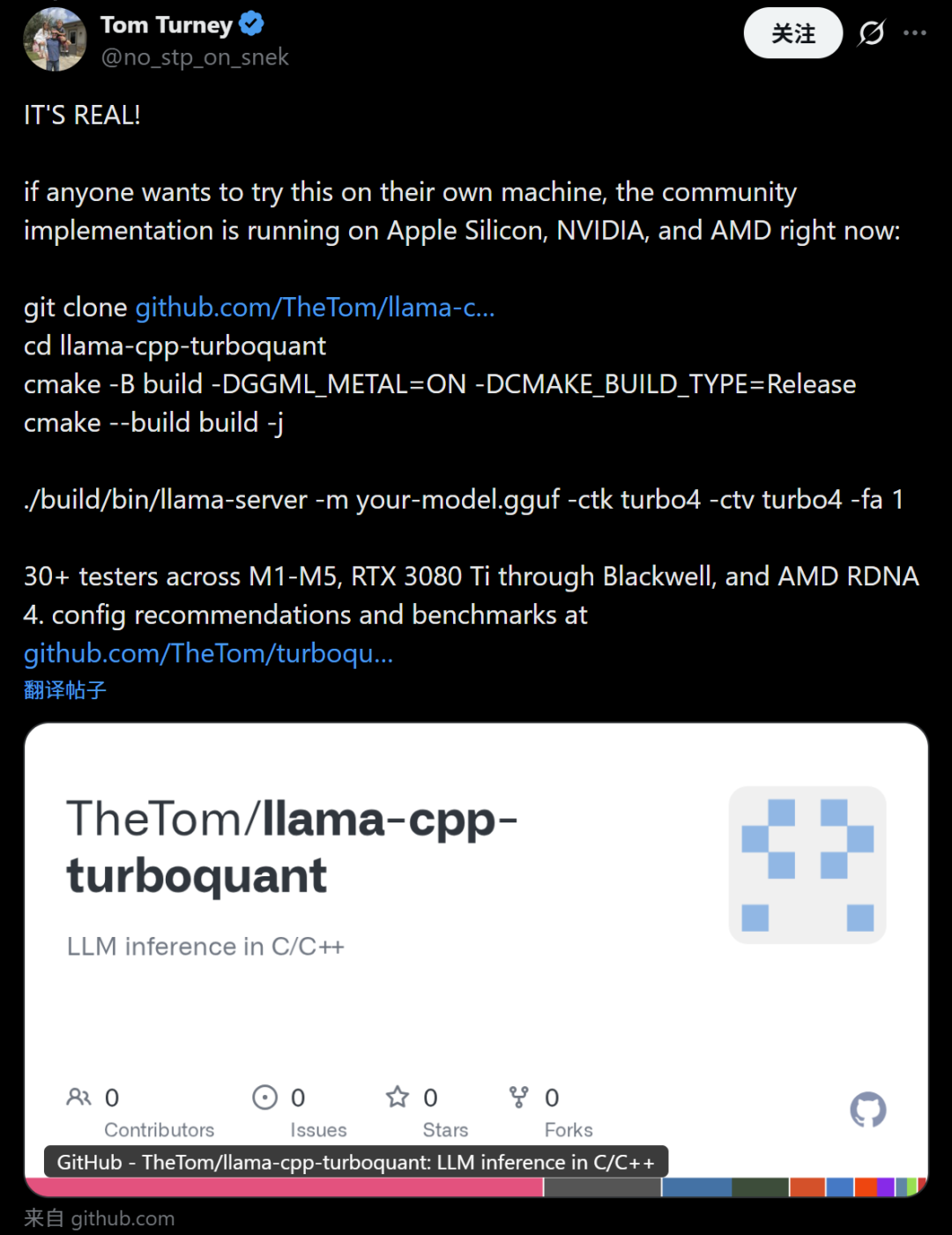
有网友艾特他感谢道其实现能够在本地运行模型并扩大上下文窗口。

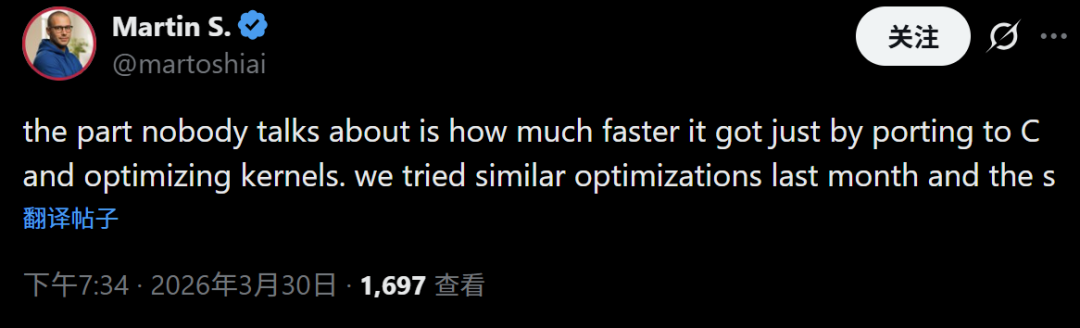
有开发者强调了光是移植到C语言并优化内核就已经提高了非常高的速度,而这是很多人忽略的地方。
个人开发者@ModernGrindTech借此高度评价道,“solo dev时代一人胜过15人团队协调”,现在这种效率过于惊人。

独立开发者Nkemka Akah评论道“Sparse V”优化是天才之举,直接在上下文中跳过90%的值解压缩。

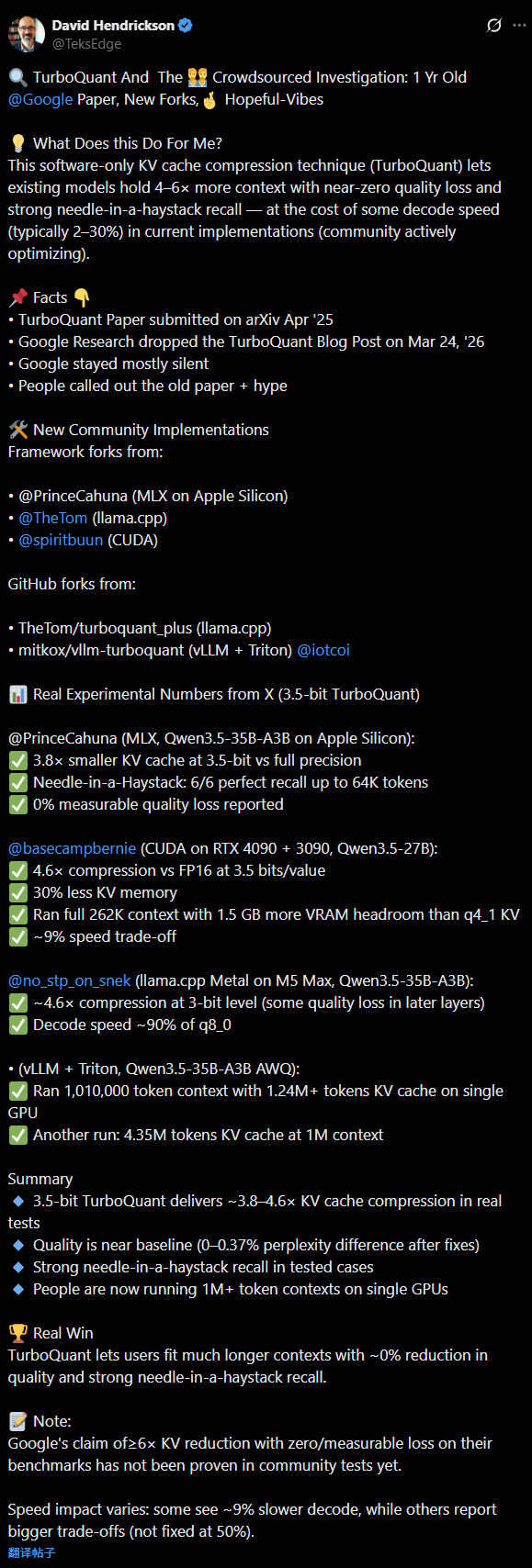
AI创业者、Columbia PhD、Generative Software Engineering作者David Hendrickson引用了该仓库,并将TurboQuant称之为“Real Win(真正的胜利)。
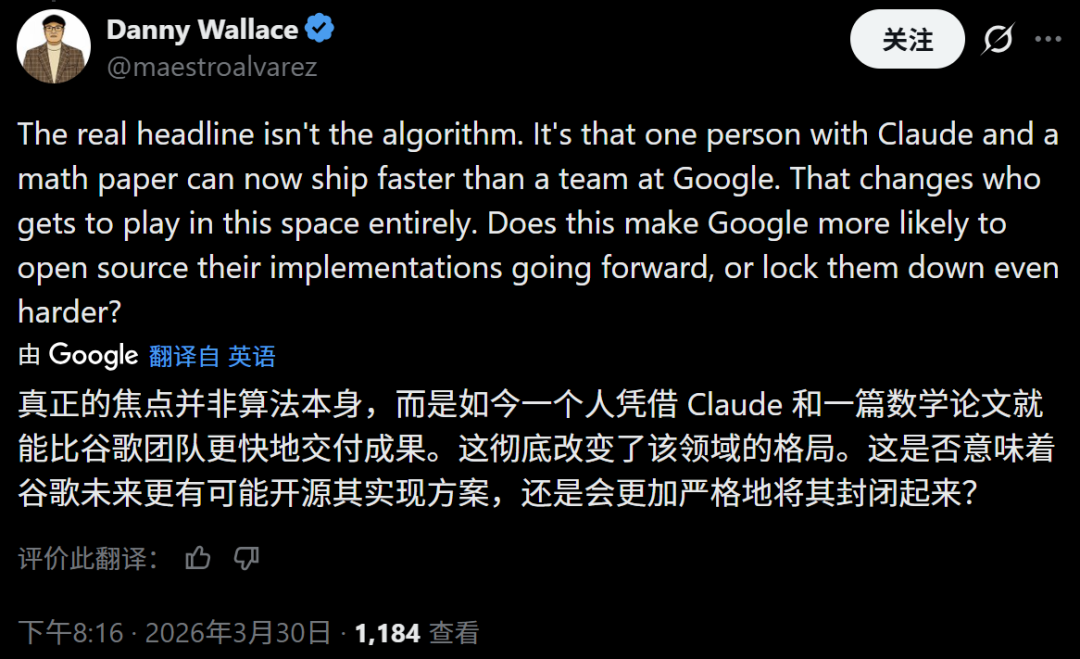
不过也有人表示了担忧,因为此事,一个人仅凭Claude和一篇论文就能快速复现成果,彻底改变了领域的格局,完全无法猜到未来大厂会开源还是会更严格地封闭。
AI时代,大厂的论文发布已经不再那么激动人心,而像Tom Turney这样的个人开发者将大厂的顶级论文短短一周内就复现并落地、甚至适配了多个平台,让个人用户也能切实用到才是最震撼的。
这不是简单的“复现”,而是一场彻头彻尾的超越。从Python原型到llama.cpp原生支持,从Metal GPU内核到Sparse V、Asymmetric K/V、Temporal Decay等独创优化,Tom用Claude作为超级搭档,把数学公式直接翻译成能跑在MacBook、RTX显卡甚至低配消费级硬件上的极致性能。
Google论文发布后迟迟不放代码,行业还在争论可行性,社区却已经用从4.6x KV Cache压缩、近零PPL损失到35B MoE模型轻松跑262K上下文、2747 tok/s预填充等实测数据给出了最响亮的回答。
更重要的是,这件事正在重塑整个AI生态的权力版图。大厂的研究成果不再是高墙内的专利,而是被AI工具和开源精神支撑起的生产力杠杆。solo dev不再是“追随者”,而是能用周末时间就把顶级研究变成人人可用的工具的“定义者”。
内存厂商股价因为一篇论文而波动,个人开发者却用实际跑通的本地大模型,证明了AI的未来门槛正在史无前例地降低,一台笔记本、一篇arXiv、一位AI助手,就足以撬动曾经需要整个团队数月才能完成的事。










