绑定手机号
确认绑定









智猩猩AI整理
编辑:华严
当前视觉-语言-动作(VLA)模型发展迅速,但往往缺乏对物理世界的深刻理解,在面对新环境时,尤其是新动作或新技能的泛化性仍存在局限性。
为此,NVIDIA Jim Fan团队提出一个世界动作模型(WAM)DreamZero,基于拥有140亿参数的预训练视频扩散模型Wan 2.1所构建。与传统的VLA不同,DreamZero能够通过预测未来世界的状态和动作来学习,将视频作为世界演变的密集表征。通过模型与系统层面的优化优化,DreamZero实现了38倍的推理加速,支持以7Hz进行实时闭环控制。

在真机实验中,与顶尖VLA模型π0.5相比,DreamZero对新任务和新环境的泛化性提升2倍以上。更厉害的是,DreamZero仅在30分钟的play data上,即可将基于AgiBot G1预训练的模型迁移到全新的机器人本体上,同时保持零样本泛化能力。

论文标题:《World Action Models are Zero-shot Policies》
论文链接:https://dreamzero0.github.io/DreamZero.pdf
项目主页:https://dreamzero0.github.io/
01 方法
基于预训练的视频扩散模型构建世界-动作模型面临视频-动作对齐、架构设计和实时推理三大挑战。DreamZero的设计基于这三项核心挑战,训练了一个端到端的统一模型,确保模态间深度融合;采用自回归架构并充分利用闭环控制的特性;通过一系列软硬件优化方案,实现了38倍推理加速,实时控制达到7Hz。
1.1 DreamZero模型架构
DreamZero模型架构如图4所示,以自回归方式训练,用于预测视频帧和对应动作。DreamZero仅对视频模态引入自回归建模,避免来自闭环动作预测的误差传播。
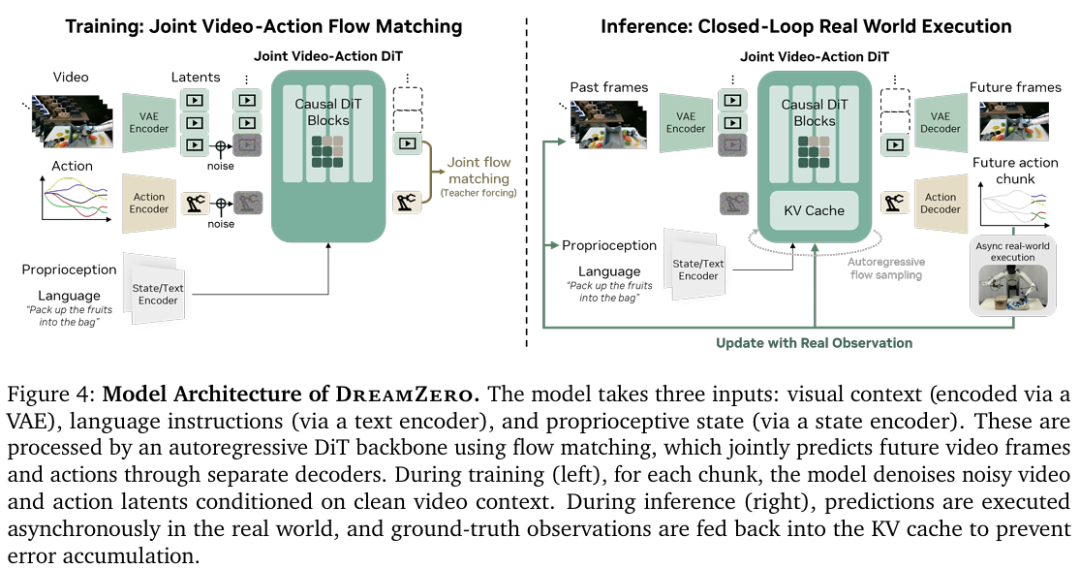
DreamZero采用流匹配作为训练目标,在视频和动作模态间共享去噪时间步,这有助于在训练初期更快收敛。此外,采用Teacher Forcing作为训练目标;模型学习在给定已去噪的前序数据块的条件下,对当前含噪块进行去噪。在推理时,DreamZero联合去噪视频和动作块,并利用KV缓存提升效率。
1.2 DreamZero的实时执行
基于扩散的世界动作模型继承了视频基础模型的强大泛化能力,但其迭代去噪过程与反应式机器人控制之间存在根本矛盾。研究人员对以下两个问题进行了研究:(1)是什么阻碍了世界动作模型成为反应式策略?(2)如何解决这个问题以实现实时控制?
反应式策略必须在数十毫秒内对环境变化做出响应。在单GPU上地实现 DreamZero每个动作数据块大约需要5.7秒,这种延迟使得闭环控制无法实现。
为此,研究人员通过异步闭环执行,将推理与动作执行解耦。这种结构将延迟约束从“机器人动作前推理必须完成”转变为“机器人动作执行与模型推理并行进行”,目标是将推理延迟控制在约200毫秒以下,以确保有足够的重叠时间来实现平滑、反应式的控制。
基于异步执行结构,通过并行化和缓存来优化推理吞吐量,再通过编译器和内核增强进一步降低延迟。
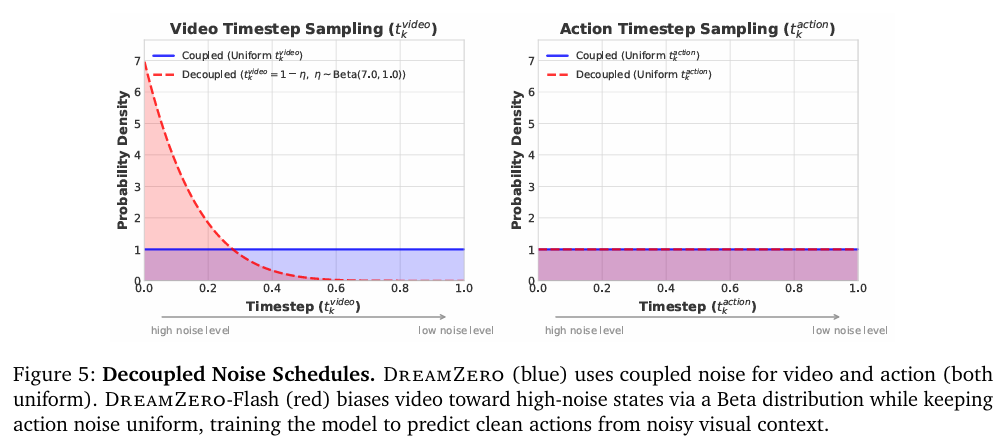
在模型层面,DreamZero-Flash通过在训练过程中解耦视频和动作的噪声调度,来解决扩散步骤的数量问题。在推理时,模型只需要进行1步扩散去噪,就能输出高质量的动作,而不需要等待视频完全清晰。
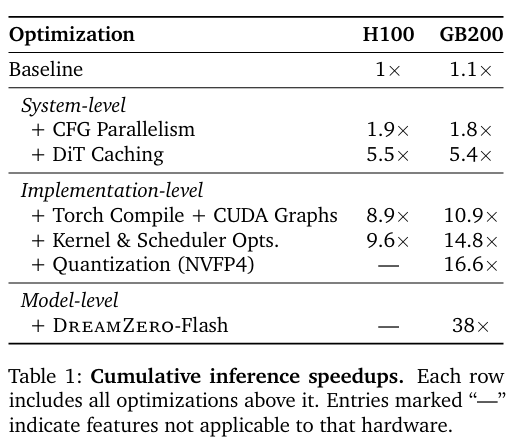
总体的加速效果如表1所示,系统和实现级优化在H100上带来了约9倍加速,在GB200上约16倍;加入DreamZero-Flash 后,在GB200上实现了38倍加速,将延迟从5.7秒降低到150毫秒。
02 实验
研究人员评估了DreamZero的零样本泛化性能,并与基线模型进行对比,旨在探究以下研究问题:
Q1. 世界动作模型能否更好地从多样化数据中学习?
在包含于预训练数据中的任务上(但在具有未见过的物体的零样本新环境中)直接评估预训练模型的开箱即用性能。结果如图8所示。
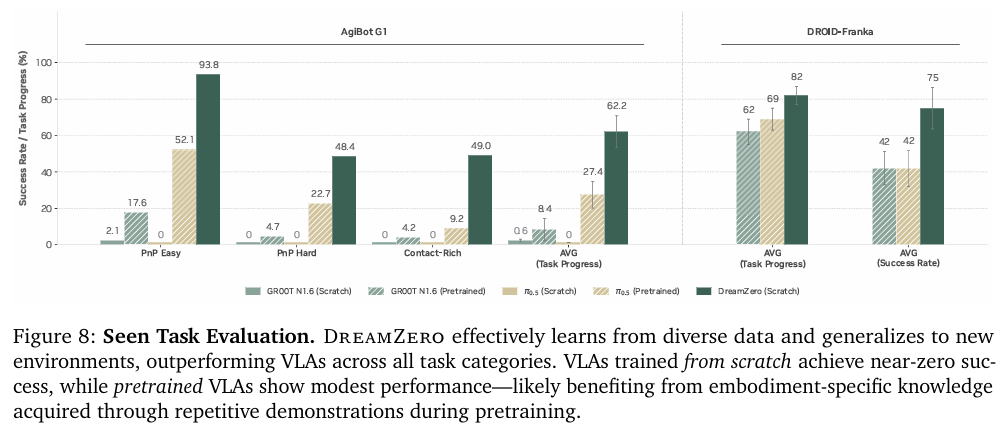
在AgiBot G1机器人上,VLA模型在所有任务类别中任务进度都接近零。相比之下,DreamZero能够成功地从异构数据中学习,取得了62.2%的平均任务进度,相较于VLA基线π0.5(27.4%)高两倍以上。
Q2. 世界动作模型能否泛化到未见过的任务上?
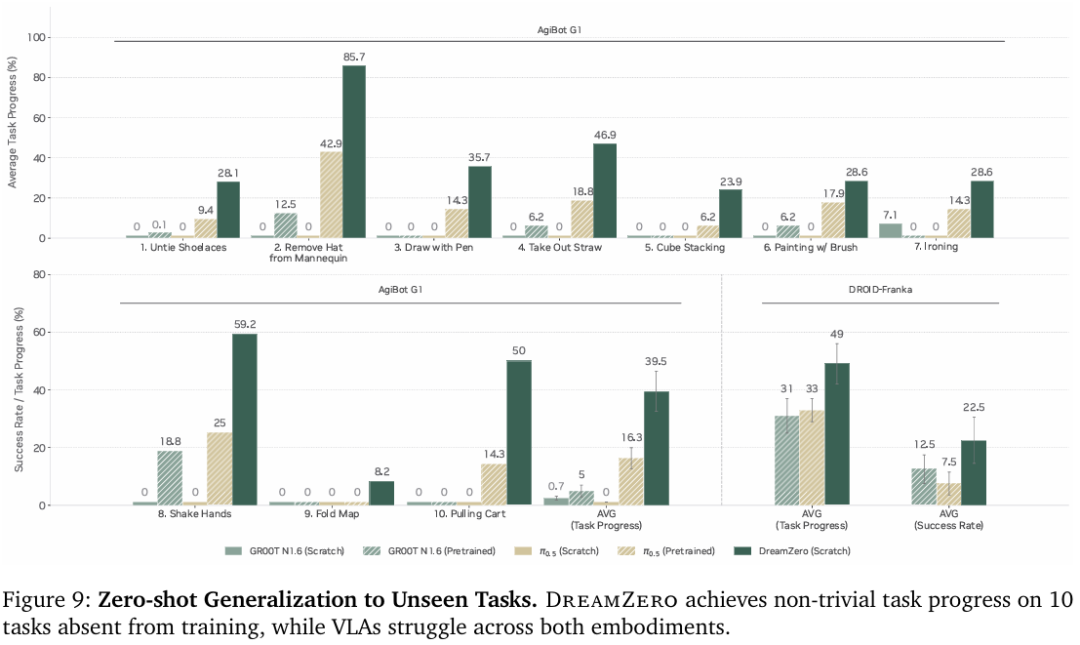
研究人员评估了模型对完全不在预训练数据分布内的泛化能力,包括解鞋带、熨烫、绘画和握手等10个任务。如图9所示。在AgiBot G1上,VLA模型取得的任务进度接近零,而 DreamZero达到了39.5%。
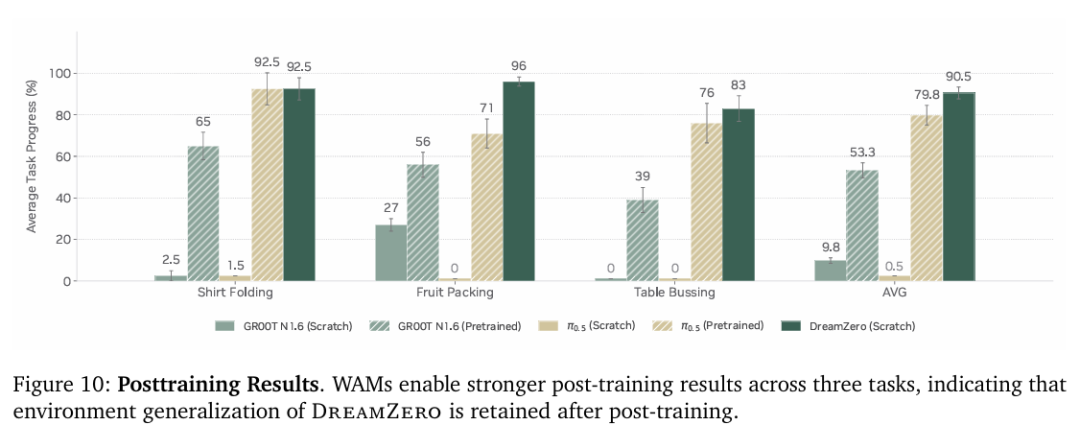
Q3. 世界动作模型是否能提升后训练性能?
研究人员探究了世界动作模型在针对特定任务数据进行微调后,是否仍能保持其泛化能力。图10展示了在三种具有不同数据分布多样性的任务上的结果。
Q4. 世界动作模型能否具有很强的跨具身迁移能力以应对未见任务?
实验分为从YAM机器人迁移到AgiBot G1机器人,和从人迁移到AgiBot G1机器人,并分别对9个未见任务收集了72条多视角轨迹。
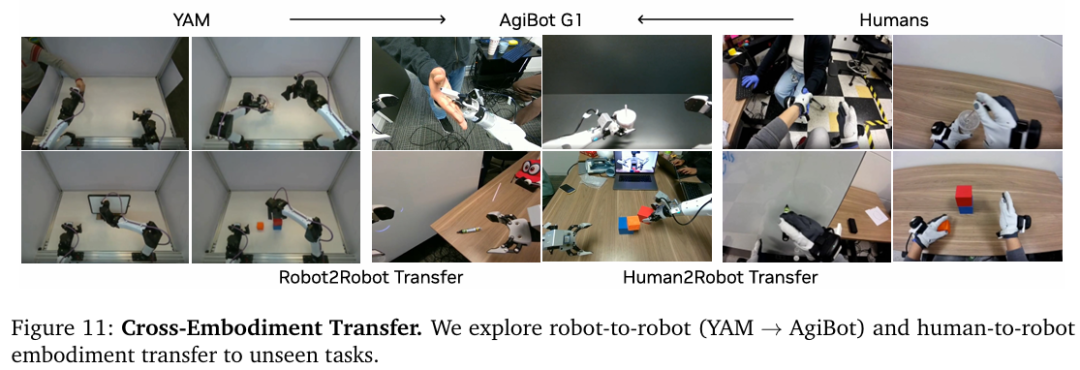
实验结果如表2所示,两种方式均提高了DreamZero的性能。从机器人到机器人迁移任务完成度从38.3%提升至55.4%。

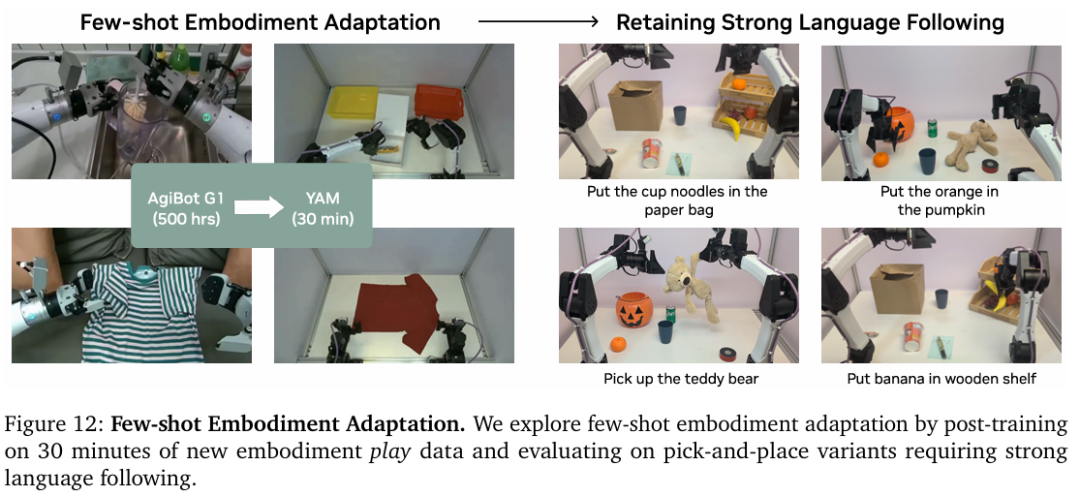
Q5. 世界动作模型能否实现少量样本适配到的新机器人本体?
仅使用11个任务的55条轨迹,约30分钟数据,在新的YAM机器人上对 DreamZero-AgiBot进行了后训练,如图12所示。尽管数据有限且多样性不足,但后训练之后的策略仍保持了强大的语言指令跟随能力,甚至能泛化到未见过的新物体。
03 总结
本文介绍了一个拥有140亿参数的世界动作模型DreamZero ,基于预训练视频扩散模型Wan 2.1所构建,能够从多样化的机器人数据中有效学习。与顶尖VLA模型π0.5相比,DreamZero的零样本泛化上的提升超过了2倍。
通过模型与系统层面的优化优化,DreamZero实现了38倍的推理加速,支持以7Hz进行实时闭环控制。此外,还实现了少量样本能快速适配到的新机器人本体,在AgiBot G1上预训练的DreamZero,仅用30分钟的play数据就能适应一个全新的机器人本体。










