绑定手机号
确认绑定









作者:sheriyuo
地址:https://zhuanlan.zhihu.com/p/2001982062979215914
https://zhuanlan.zhihu.com/p/2002721782751335953
经授权发布,如需转载请联系原作者
Test-Time Scaling (TTS),也叫 test/inference-time computing,指在推理时使用更多计算代价来换取更优性能的方式。对于一个较小的模型,可以用数倍的推理时间取得较大模型或 RL 后模型的性能,其本质是把训练时间分摊为推理时间,实现免训练(training-free)的对齐效果(RL,SFT)。随着 o1、Qwen3-Max-Thinking 等工作的应用推广,TTS 具有很强的潜力与应用价值。
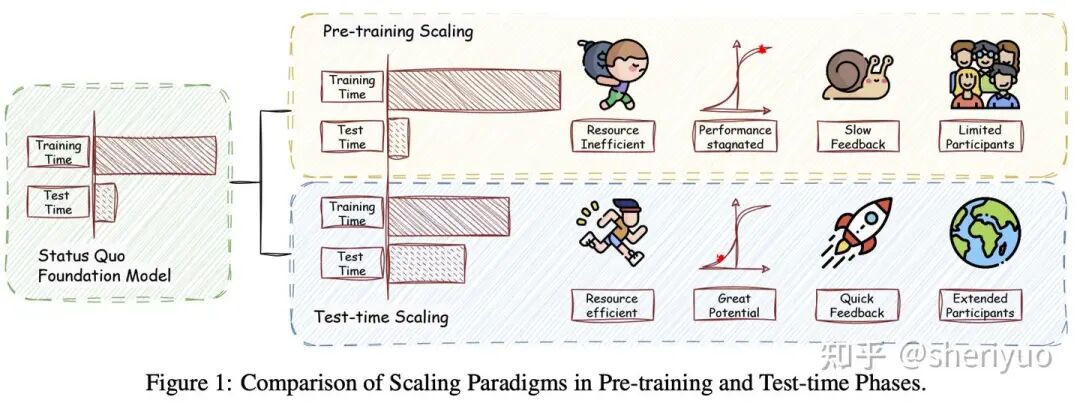
TTS 可以主要分为以下几类:
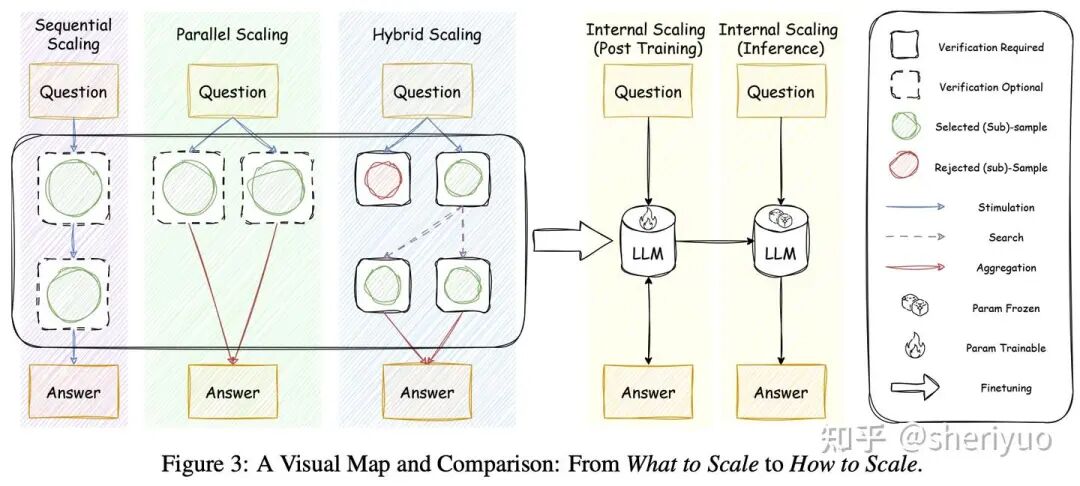
1. Sequential Scaling:严格意义上不是 TTS 而是 CoT。
2. Parallel Scaling:对一个 query 生成多条 response,经典的方法是 Best-of-N 和 Self-Consistency(Majority-Voting)。如果直接使用 ground-truth 来选取答案,得到的结果就是 pass@k;但是大多数情况下无法在推理时获得 ground-truth,于是便有了 Self-Evaluation:用模型自身的某些性质(logits,entropy)或直接选取多数来作为 reward function 选取答案。
3. Hybrid Scaling:对推理过程进行 token-level 或者 block-level 粒度的拆分,经典的方法是 Tree-of-Thoughts 系列(Beam Search,MCTS),本质上也是在探索 trajectory。
4. Internal Scaling:使用 training-based 策略,让模型学习 self-evaluation 和 computational budget。
Self-Evaluaion 作为一种 Verifiable Rewards 的替代品,既可以在 RL 中作为 reward(Co-rewarding),也可以结合 Best-of-N 等 TTS 方法使用,可以说是连接了 TTS 与 RL。那么到底如何用 TTS 实现免训练的 RL 呢?
一种常见的观点是 RL 并没有给 base model 本身学到更多的知识。相比于 SFT 尝试探索扩宽已有的分布,RL 其实是锐化(sharpen)了 base model 的分布,用 pass@k 性能的减弱换取更好的 pass@1 性能。
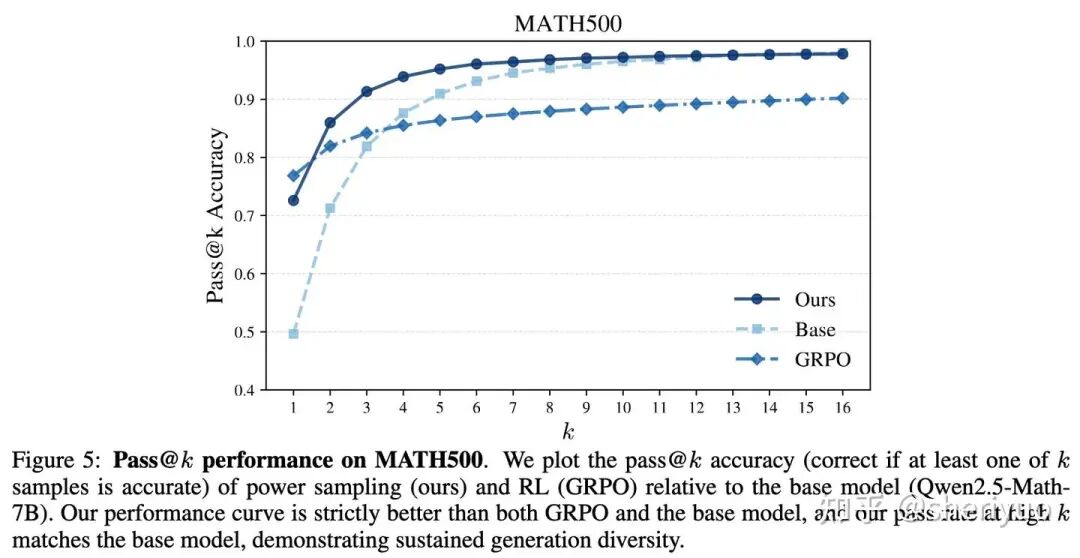

那么从 sharpen 后的分布去采样,是不是就能得到更好的效果呢?相比于调低 softmax temperature 这种 naive 的方法,使用 low-temperature 从 里采样可以得到更 sharp 的分布。

但是这样并不是真的从 里采样,而是对未来可能的 trajectory 做了一次 greedy decoding,这启发我们用 TTS 的方式来考虑这一问题。

Bayes 统计中,Metropolis-Hastings 算法可以从无法直接采样的分布 中估计抽样,其本质是一种Markov Chain Monte Carlo(MCMC)算法。具体地说,从已知的后验分布 中采样出初始状态 和若干个候选样本 ,对于每个样本以概率 接受,概率 拒绝。

采样的候选样本数越多,样本就越收敛于目标分布 。使用随机重采样的方法,从 中随机截取一段 prefix,重新采样后面的 token 得到 ,这样 便都可以计算得到,如此我们便实现了从 里采样,发掘了 base model 自身更多的性能。
Power Sampling 的实验结果甚佳,但是如何将 TTS 真正扩展到通用的 RL 场景比如 RLHF 和 RLVR 呢?我们需要回归到 Self-Evaluation 和 RL 的本质中。一些工作(Infalign,Nudging)尝试了用 RL 后的小模型来对齐 base model,但是这样的方法说不上是免训练;另一些工作(见附录)尝试了 Gibbs Sampling 从 RL 分布里采样,但是局限于 diffusion model。这些工作为我们提供了启发:直接从 RL 目标分布里采样,而不是使用策略梯度去更新参数。
对于 RLHF 中带 KL 约束的目标函数(PPO、DPO、GRPO),其存在闭式解,使用 Lagrange 乘数法即可证明。

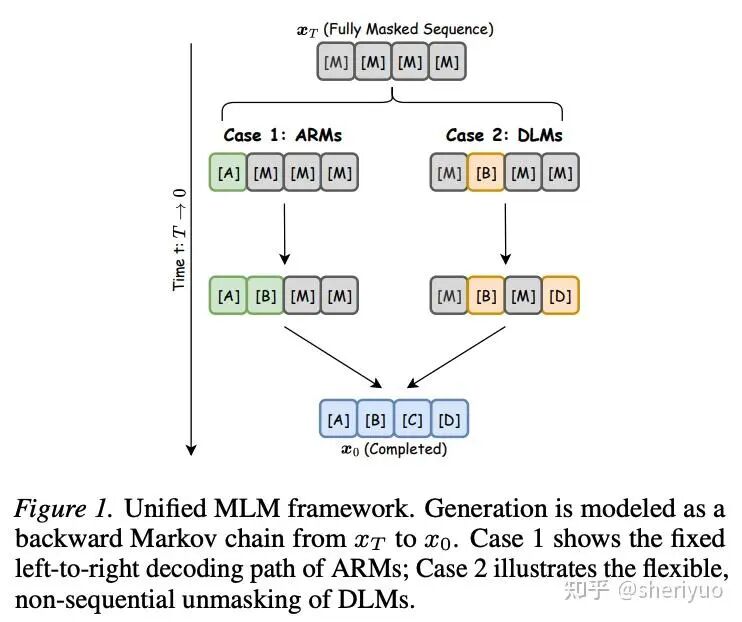
我们可以用 Mask Language Modeling 将 Autoregressive Model(ARM) 和 Diffusion Language Model(DLM) 统一建模为一个反向马尔可夫链
类似 Gibbs Sampling,我们直接从闭式解出发,将最优分布转移 拆解为了已知后验分布转移 和一个与 reward 有关的能量项 ,可以通过这个能量项引导 reference model 采样出 reward 更高的样本。
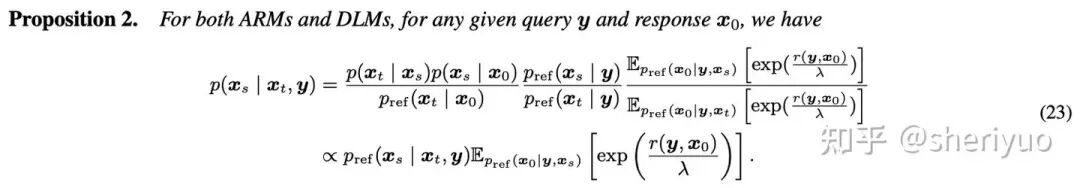
一个直观的方法是直接用 Monte Carlo 估计,对每一个 从后验分布 中采样出可能的 trajectory 进行估计。

这样我们便得到了一个能量引导的 TTS 采样方法,无需训练便可对齐 RL 最优目标分布。

同时可以证明这样采样的分布收敛于最优目标分布。
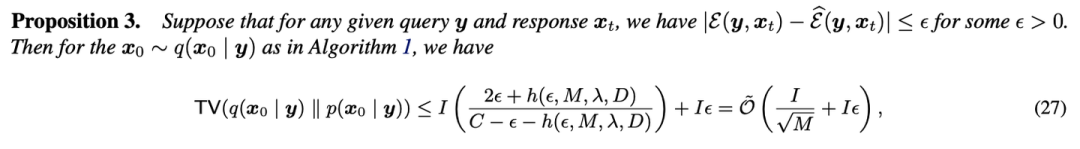
实验证明引入了能量采样的 TTS 相比于传统的 Best-of-N、Beam Search等方法对抗采样噪声更鲁棒,采样效率高的同时效果更佳,在 Reasoning、Mathematics、Coding 等数据集上测试结果超过 GRPO RL 后的模型。
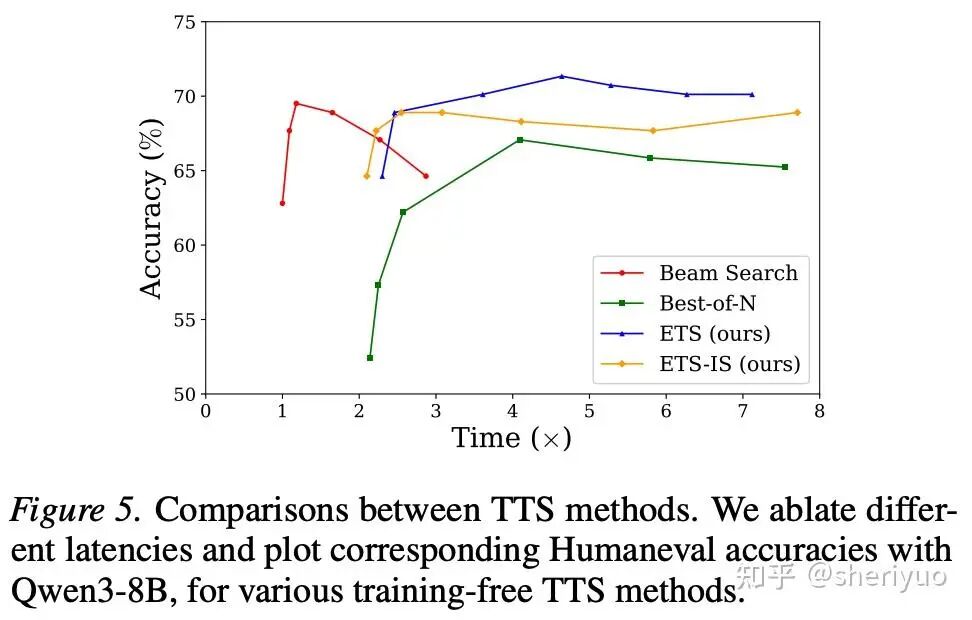

如何对这一简单的 Monte Carlo 方法进行加速?我们提出了异步推理 Pipeline 和 ETS-IS 加速方法,使用重要性采样(Importance Sampling)取得了良好的加速效果。欢迎阅读我们的论文 ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment 和 Github 代码库 查看更多细节设计、实验结果和理论证明。
TTS 在免训练 RL 上的研究方兴未艾,更多优秀的工作聚焦于更好的采样、估计与进化(Do Not Waste Your Rollouts: Recycling Search Experience for Efficient Test-Time Scaling),Power Sampling 等方法所带来的计算代价也需要更好的 Infra 来加速优化(https://github.com/maxzuo/mh-llm),我们会在后面的文章讨论这些内容。ETS-v2 的研究正在进行,我们聚焦于更好的估计与更优的加速,为免训练 RL 带来更多的可能。

让模型自进化一直是 RL 里的经典方向(Reflexion、Self-Distillation RL、TTT、TTRL),与我们提到的 Self-Evaluation 紧密相关。Reflexion 框架为 Self-Evolving Agent 打下了地基:通过 self-reflection 和 memory 让模型从错误经验里学习。

而严格意义上讲,Self-Evolving和 TTS 是两个不同的路线,TTS 是并行,而 Self-Evolving 是串行。Self-Evolving 需要进行多轮的 rollout recompute,同时进行更新(prompt、memory、model),其本质是外层嵌套了一个 Sequential Scaling(CoT)的 Agent Workflow,由若干个小的 TTS 串起来;相反,狭义的 TTS 是不会 recompute 的,生成的 response 就是最后的答案。Self-Evolving 利用了模型 post-train 时本身就是在学 reflexion 这一特性(self-play)来做 Self-Distillation RL,如果在 rollout 后更新了梯度 / LoRA,那么就是 Test-Time RL / Training-Free GRPO;如果没更新梯度而是更新了 prompt / memory,那就是 Reflexion。

传统的 Self-Evolving 使用 Self-Evaluation 来作为单轮 TTS rollout 的 Reward,主要依赖 Majority-Voting 选取出 knowledge。

对于更大、更前沿的模型,使用 api 调用时便很难获取到除了 Majority 以外的信息,于是也可以让模型自己(或者更小的 reward model)来当 verifier。RSE 使用 Self-Guided Experience Distillation 来让模型自己判断这条 trajectory 的有效信息,加入到后续 rollout 轮次的 prompt 中。

传统的 TTS 现在作为一个 Self-Evolving 的组成部分促成模型的自进化,它们各有各的优化方向:
1. 对于 TTS,需要探索更优、结构更轻量、推理速度更快。传统的 Best-of-N w/ Majority-Voting 和 Beam Search 无法达到较优的效果,最新提出的 Power Sampling 和 ETS 具有更好的表现,可以作为一个即插即用的组成部分,也可以优化底层的 Infra 结构来加速。
2. 对于 Self-Evolving,现有工作也做了一些 pruning、memory 的优化,其核心目标也是在保留高准确率的同时尽量优化 computational cost(FLOPs、tokens)。
对于 TTS 的架构还有很多的研究可能,未来 TTS 只会更频繁出现在前沿模型的 Infra 中,Qwen3-Max-Thinking 不会是终点。
笔者写的时候没注意到 Power Sampling 已经出 v2 了(没想到卷的这么快):
Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening。大体是用了一个 look-ahead 的 guide 来近似原版 MCMC,这样可以不用重采样而是自回归生成,使用 vllm 后比原版加速了 10x。这其实很像我们的 ETS,但是从 token-level 的 motivation 硬加速到 block-level 太 heuristic(虽然实验结果很不错),缺乏一些 bound,并且对于 post-train 过的 model 提升有限。其实这里就能看到后续加速的一些大概方向了,诸君共勉。
1. Self-Distillation:
TTRL: Test-Time Reinforcement Learning
Reinforcement Learning via Self-Distillation
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-Distillation Enables Continual Learning
2. Reflexion:
Reflexion: Language Agents with Verbal Reinforcement Learning
Test-time Recursive Thinking: Self-Improvement without External Feedback
Do Not Waste Your Rollouts: Recycling Search Experience for Efficient Test-Time Scaling
3. 综述:A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well
4. Power Sampling:Reasoning with Sampling: Your Base Model is Smarter Than You Think
5. Diffusion 上的 TTS 工作:Inference-Time Scaling of Diffusion Language Models with Particle Gibbs Sampling
6. Self-Evaluation:Co-rewarding: Stable Self-supervised RL for Eliciting Reasoning in Large Language Models










