绑定手机号
获取验证码
确认绑定
提问
0/255
提问
订阅开课提醒需关注服务号
×
首页
直播
合辑
专场
智东西
回答成功
知道了
扫码关注智猩猩服务号登录
请使用微信扫描二维码
扫描二维码分享给微信好友
您已订阅成功,有新课程,我们将第一时间提醒您。
知道了
发送提问成功
回答可在
“我的——我的提问”中查看
知道了
失败
欢迎来智东西
登录
免费注册
关注我们
智东西
车东西
芯东西
智猩猩
智东西
车东西
芯东西
智猩猩
智猩猩
智猩猩官网
智猩猩小程序
线下大会
预告
公开课
讲座
AI技术解析
全部干货
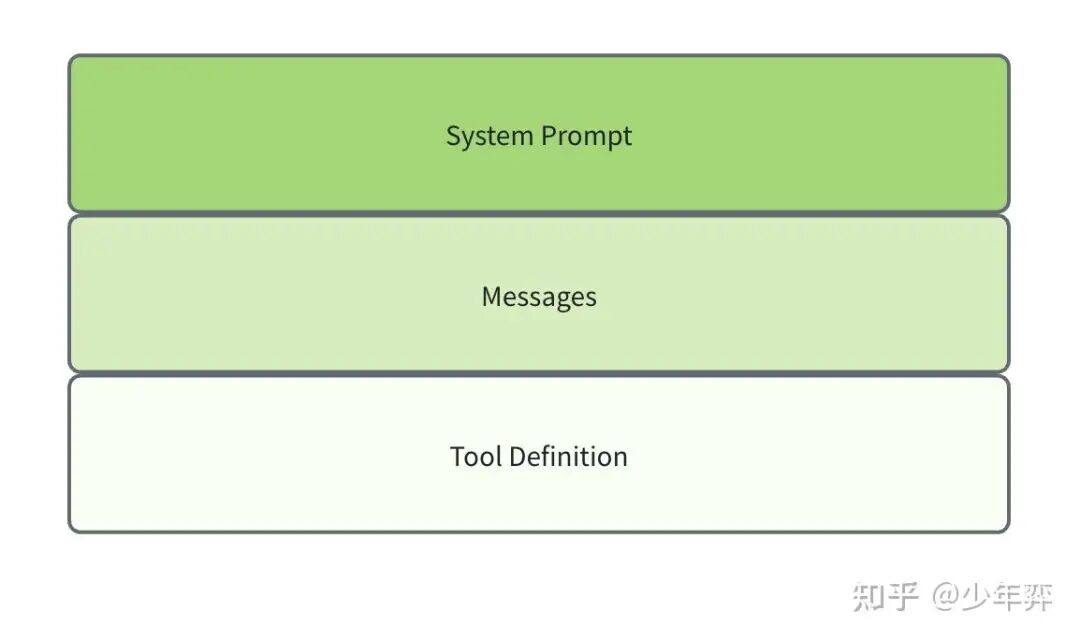
GRPO 踩坑实录第二弹:从单步到多步的奖励函数升级
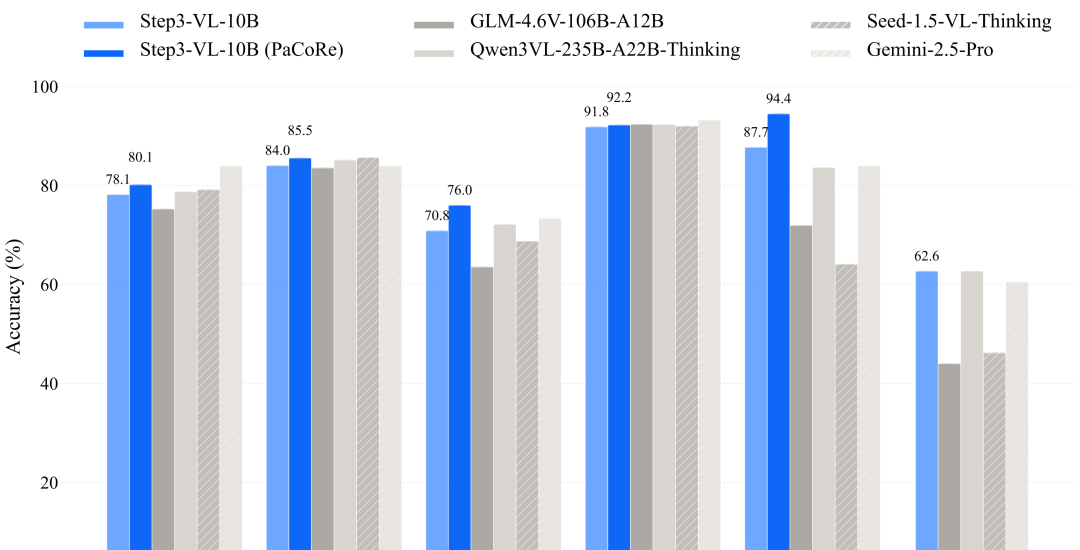
为什么用Rust从头开始写一个推理引擎
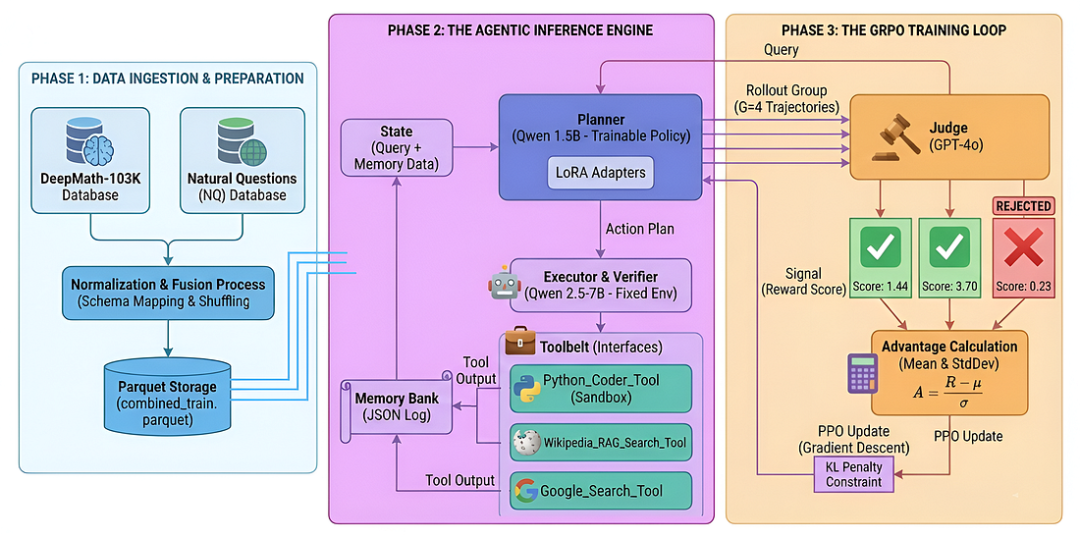
从Minimax-ForgeRL到Kimi-Seer,聊聊Agentic RL Infra优化方向
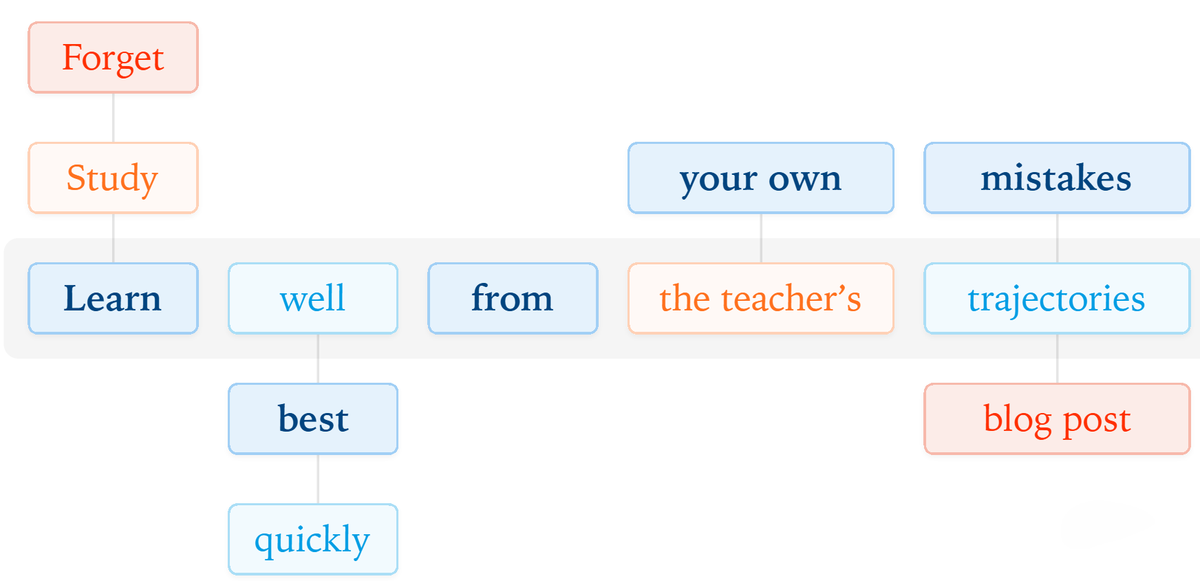
Vibe Coding 一年后的 Bitter Lesson
浅谈 Test-Time Scaling 与免训练 RL
从零开始构建自进化智能体的心路历程
大模型推理加速:从EAGLE 到DFlash
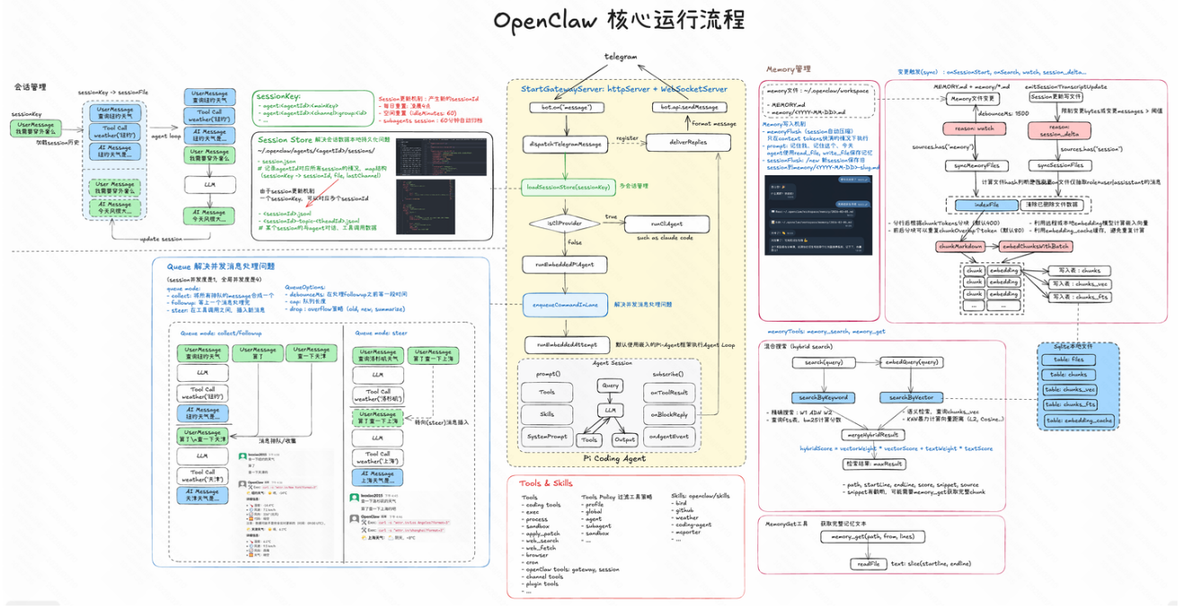
深度解析:一张图拆解OpenClaw的Agent核心设计
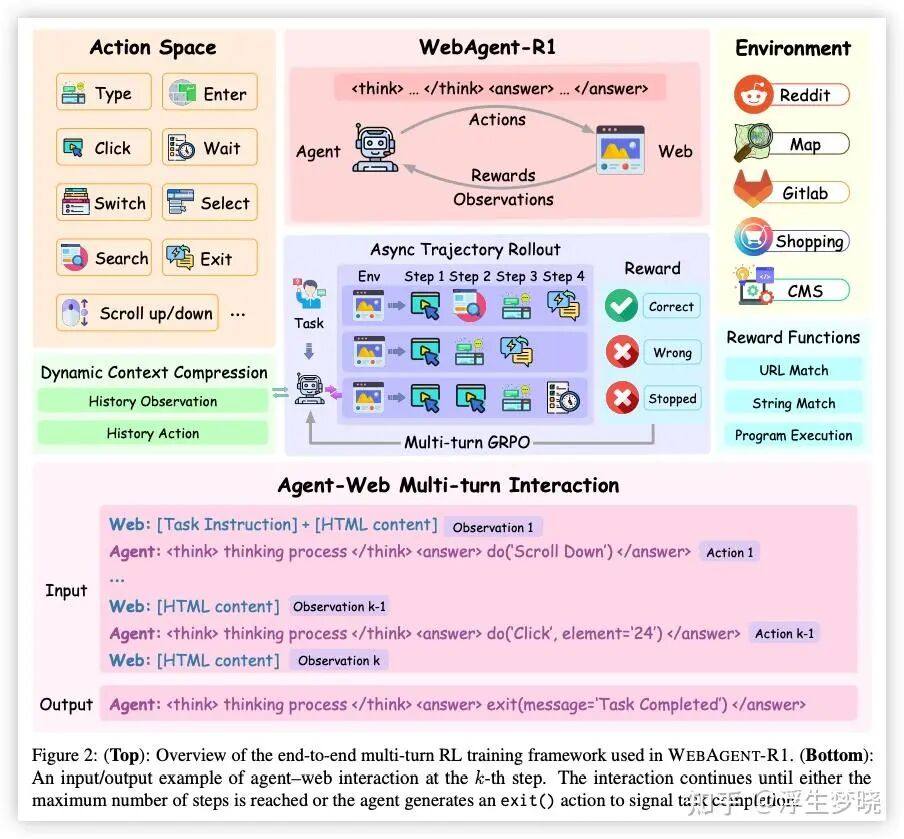
GUI智能体强化学习训练高知名度论文总结:从WEB AGENT-R1到InfiGUI-R1
从梯度角度看SFT、Off-Policy Distillation、RL、On-Policy Distillation
在GPU团队自研推理引擎的这两年
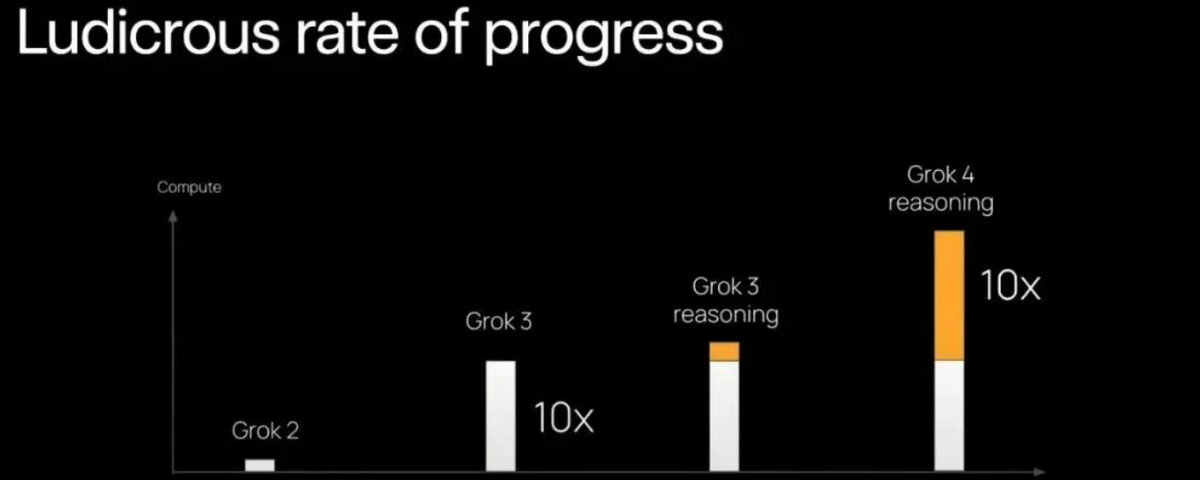
下一个范式:Meta Foundation Model
聊聊OpenClaw的AgentLoop
历时两个月的GRPO 训练踩坑实录:63% -> 96% tool selection
不是结束,是开始的结束:写在 Step 3.5 Flash 发布与我在阶跃的一年半
聊聊理想中的大模型强化学习后训练系统
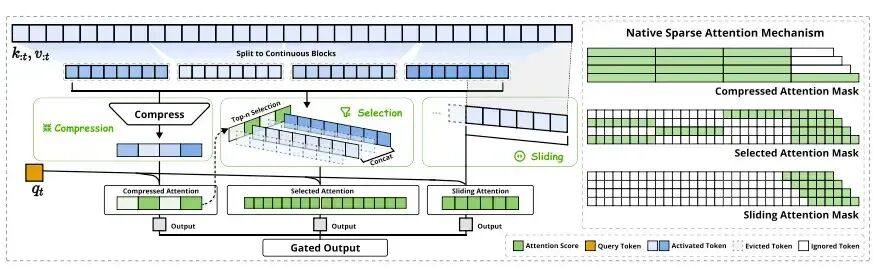
后注意力时代:Sparse is all you need
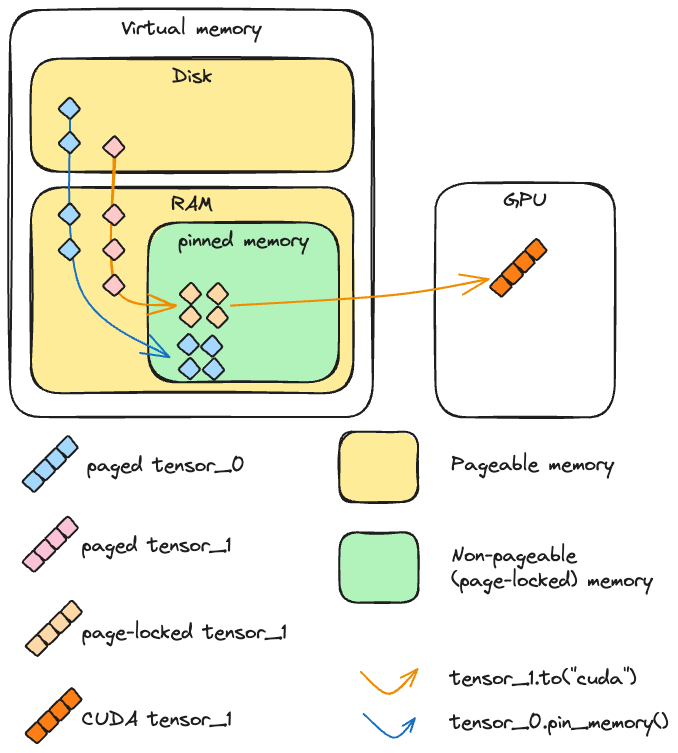
AI Infra:PyTorch Offload技术优化实践
华为王云鹤:谈谈扩散语言模型的“草稿-修订”新范式Diffusion in Diffusion
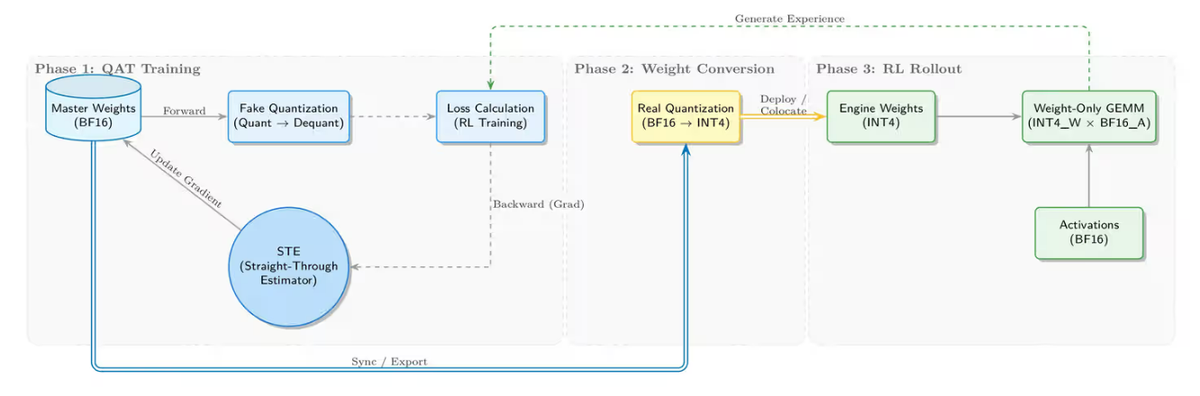
致敬 Kimi K2:基于 slime 的全流程 INT4 量化感知训练
上一页
1
2
3
下一页

















 上一页
上一页
