绑定手机号
确认绑定









作者:王云鹤,华为诺亚方舟实验室高级研究员
地址:https://zhuanlan.zhihu.com/p/1999518489149449111
经授权发布,如需转载请联系原作者
01 谈谈Global Diffusion 与 Local (Block) Diffusion
从原理上来说,现在的离散DLLM(DIffusion Large Language Model)应该是一种极具表达力的范式。离散DLLM=全局上下文+任意位置生成,而这里的“任意”位置生成显然也包括从左到右顺序生成,也就是传统的Autoregressive。某种程度上,这就可以说现有的各种SOTA AR模型全都是离散DLLM的一种特例。那么,一个自然的想法就是,作为AR模型的“超集”,离散DLLM理应展现出远超现有AR模型的performance。然而我们知道现实绝非如此。即便是现有最好的离散DLLM,其各种基测表现也逊于(或是将将持平)AR模型,并没有让我们见到一种(至少是performance上)全面更优的新LM范式。这里的gap可以有各种解释,例如训练方法不够完善,NELBO作为objective不够有约束力等等等等,研究依然道阻且长。
无论如何,上面的分析给了我们一种信念:离散DLLM是非常有潜力的。
然而,现在的主流DLLM研究正在往Semi-AR的方向走,也就是Local或者Block Diffusion。这种方法最主要的贡献是在宏观上为离散扩散引入了AR bias,也就是常说的块内扩散,块间AR。整体上看,一个block可以看作一个AR的metatoken,可以进一步抽象为带有MTP层的AR模型。这么一来,AR的各种好处统统都可以套在这个上面,如KV Cache,动态长度扩增等等。
在Block Diffusion的paper中,作者展示了当blocksize从1k(full context length)逐步减小趋近于1时,模型从一开始的纯Full Diffusion逐渐变为semi-AR Block Diffusion,最终变为纯AR,而这个过程中模型的ppl是单调递减的。这里弥补Diffusion与AR之间性能gap的方式就是引入越来越多的AR bias,使得宏观上执行AR操作的metatoken越来越小;最后metatoken变为real token,semi-AR变为纯AR。得到一个“越多把Diffusion消融掉效果越好”的实验结论。
Diffusion之所以为Diffusion,关键就在于其每个token都具有全局视野,而非AR的单向历史视野。然而随着Block Diffusion的block size变小,Diffusion可以操作的双向context也从global变得非常local。这从根本上限制了Diffusion的性能上界。我们从这里着手,试图在保留现有的Block Diffusion成果的基础上重新把Global Diffusion带回来,为其解开更多的可能性。
论文地址:https://arxiv.org/abs/2601.13599
项目主页:https://noah-dllm.github.io/
02 核心黑科技:Diffusion in Diffusion

利用扩散模型独有的infilling能力,我们的方法相当直观:首先利用small block diffusion与semi-AR快速生成草稿,再使用global diffusion定点修改其中不合适的内容。这样既能利用AR bias与KV Cache高效产出不错的初稿,还能利用global diffusion的全局视野修正其中前后不一致或不够“整体”的内容。既避免了全部使用semi-AR的全局性丧失,又避免了全部使用global diffusion的低效性与缺乏AR bias的现实因素。
也就是说,常规AR的概率建模:
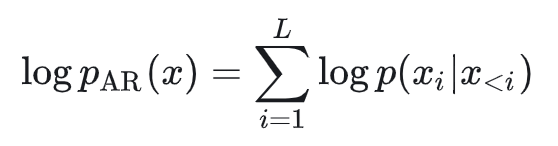
Block Diffusion的概率建模:
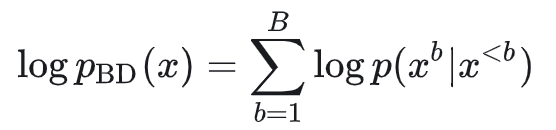
而Diffusion in Diffusion的概率建模:
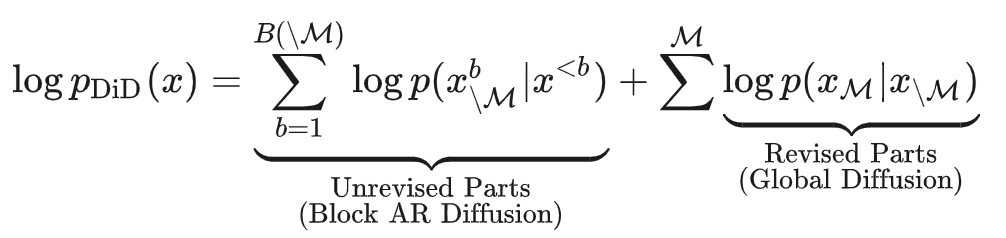
从结果上来说,DiD的两阶段采样设计还是有效果的:
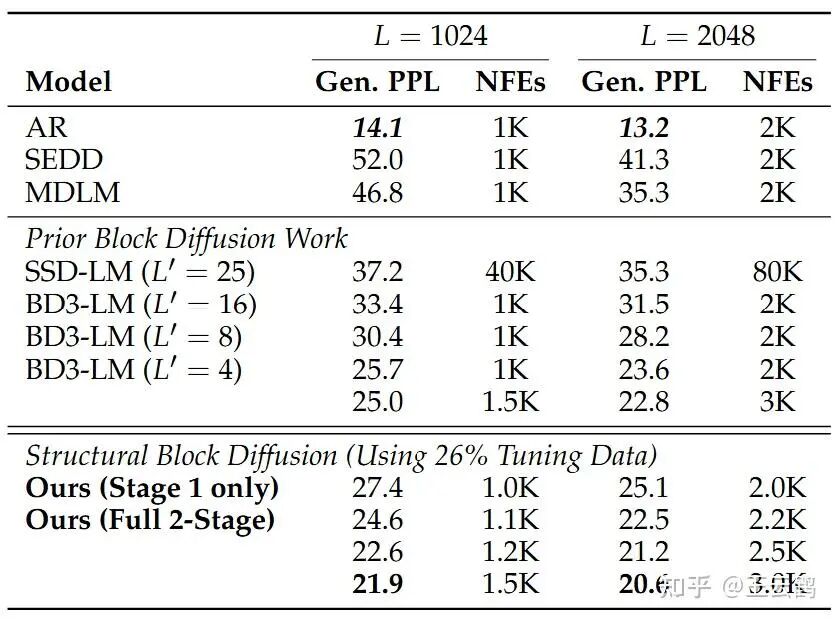
我们使用BD3-LM作为baseline,我们的结果只使用了baseline四分之一的训练数据,因此在仅使用一阶段时(等价于BD3-LM L’=4)ppl比对应baseline的25.7要高不少。然而只要加上DiD的第二个大blocksize revise阶段,效果立竿见影,通过逐步增加额外投入的计算量(NFEs),ppl可以稳步下降。在增加20%计算量时即可低至22.6,最低可到21.9,大幅低于baseline的25.7。当提供相对应的计算量给baseline时,其也只能略微降低至25,还是落后于DiD。
03 其他一些细节
选择需要修改的内容: 如何选择需要修改的内容是DiD的关键。我们希望精准找出一阶段生成中最不好的位置。这里有许多可能性,我们采用了一种没有额外成本的方法,即将每步去噪时被选中的token的confidence一起保留下来,后续再根据这份confidence trajectory去将模型最不自信的位置变回mask token,进行第二阶段的全局重新生成。这里的选择机制可以随意更换,甚至变成可学的,有待更多尝试。
修改时的context length: 我们还尝试在二阶段使用其他blocksize的block diffusion,结果很有趣:只有使用够大的context才能够有正向作用;若是在一阶段blocksize为4的生成基础上挑出一部分remask掉再做一次blocksize为4或16的生成反而会使文本变差。推测可能是这些“难例”已经无法采用当前的小context解决。同时,确实是context越大效果越好。
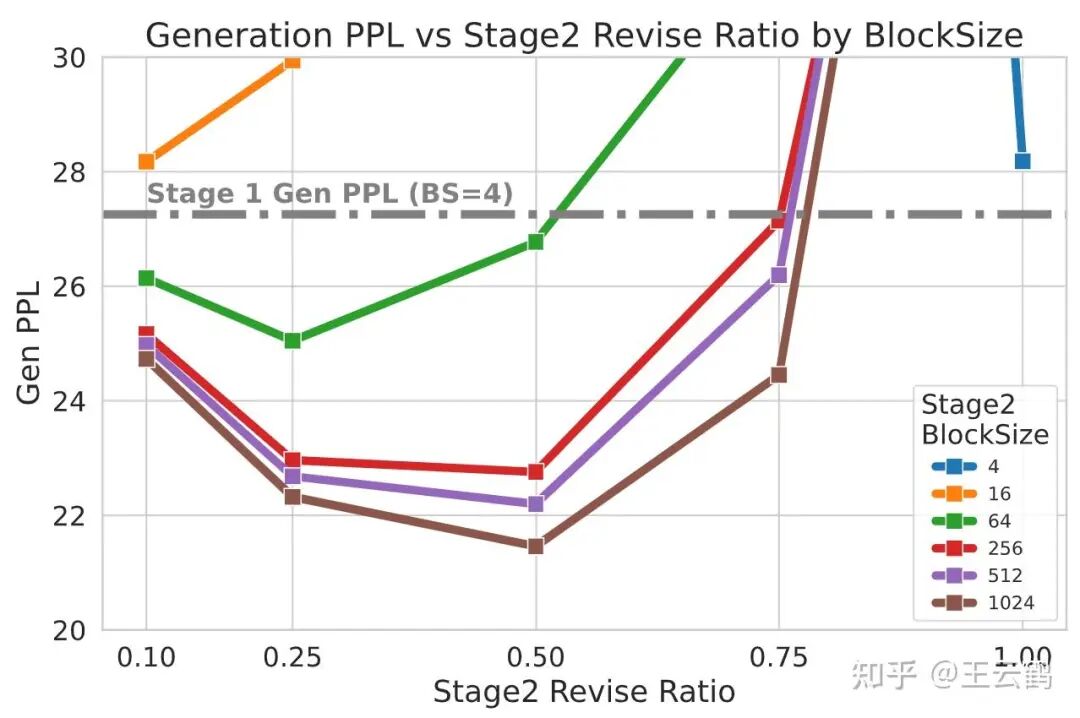
修改力度: 当修改比例越大时修改力度就越大,当前该设定与remasking策略绑定。比例过小时等于没用;比例过大时,DiD退化为大blocksize的单独扩散生成,失去全部AR prior效果变差,与先前的Block Diffusion结论一致。只有比例中等时才最为平衡。
训练相关: 理想情况下,DiD是一个无需训练的即插即用采样优化方法。我们现在的训练目的是补全当前模型全局扩散性能的短板。由于我们发现经过Block Diffusion训练出来的模型只在一种blocksize上最有效,同时几乎完全失去了global diffusion的能力。因此我们采用了自己的混合尺度训练来替换原有的单一尺度训练,从而使模型同时具备small-block与global两种能力:
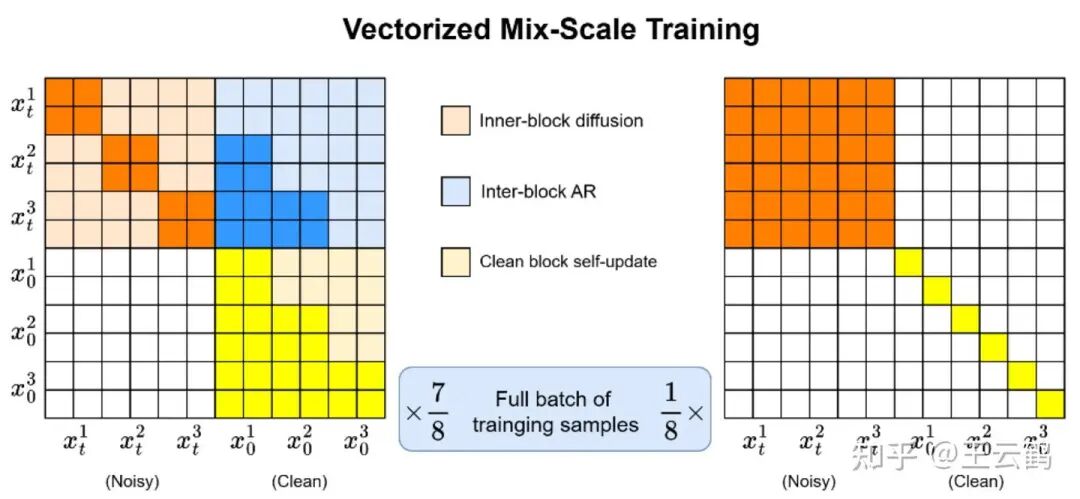
当基座模型的参数量提升,原始预训练更加robust之后,我们认为其大概率自然地具备small-block与global两种能力,因此便很可能不再需要这一段训练。
04 后续
接下来我们会把DiD从当前的110M小模型scale到1B甚至7B+的大模型,确认其在各种参数量上都有效。我们还会在remasking token selection方案上做更多探索。除此之外,将修改位置在二次扩散时赋予动态长度也是一个非常有趣的方向。










