绑定手机号
确认绑定









作者:绝密伏击
地址:https://zhuanlan.zhihu.com/p/2004595351189987521
经授权发布,如需转载请联系原作者
这段时间折腾了一下 EAGLE 推理加速的事情,在 GPT-OSS-120B 上取得了不错的加速效果,8 并发下加速 36% 左右。趁着春节临近,总结一下 EAGLE 的加速原理,顺便介绍近期刚出来的新方法 DFlash,号称加速效果是 EAGLE 的两倍。
01 EAGLE
EAGLE(Extrapolation Algorithm for Greater Language-model Efficiency) 最早由 2024 年论文 “EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty” 提出,核心聚焦于一种 无损(lossless)推理加速 的 speculative decoding 方法:在不改变目标模型输出分布的前提下,将单次 forward 能够“确认”的 token 数从 1 提升至 3~4 个甚至更多,从而显著降低推理延迟并提升整体吞吐。
EAGLE是一个用于 LLM 快速解码的新方法,并且在理论上可证明它在加速的同时能维持与普通(vanilla)解码一致的性能表现。EAGLE 的核心思路是:对 LLM 倒数第二层(second-top-layer)的上下文特征向量进行外推(extrapolation),从而显著提升生成效率。
总结来说,EAGLE 的特点是:
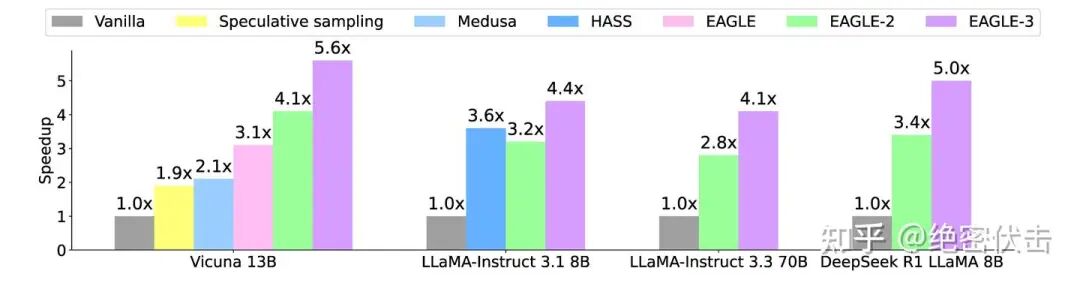
相比普通解码 快 3 倍(13B)。
比 Lookahead快 2 倍。
比 Medusa快 1.6 倍。
能可证明地保持与普通解码一致:生成文本的分布与 vanilla decoding 保持一致(即不改变输出分布的一致性)。
可训练、可复现:用 8×RTX 3090,大约 1–2 天就能训练并测试,所以即使 GPU 资源不多也负担得起。
易组合:可以和其他并行/加速技术叠加使用,例如 vLLM、DeepSpeed、Mamba、FlashAttention、量化以及各种硬件优化等。

1.1 EAGLE 简介
像 ChatGPT 这样的大语言模型(LLM)能力很强,也正在被广泛应用到各个领域。但它们的文本生成通常既昂贵又缓慢。造成低效的关键原因在于 自回归(auto-regressive)解码 的机制:每生成一个 token 都需要做一次 forward,而这次 forward 必须访问模型的全部参数——动辄几十亿、上百亿甚至数千亿参数。由于需要频繁读取海量参数,自回归解码在实践中往往受到 memory-bound(显存/内存带宽瓶颈) 的限制,因此速度难以提升。
speculative decoding:用小模型“先猜”,大模型“一次验”
加速自回归解码的一条常见路线是 speculative decoding(推测式解码)。它的基本做法是:
1. 用一个更小的 draft model(草稿模型) 按常规自回归方式先“猜”出接下来 个 token;
2. 再让原始的大模型(Original LLM)对这串猜测进行验证,验证只需要一次 forward。
如果草稿模型在这 γ 个 token 里有α 个 token 猜对了,那么原始大模型的一次 forward 就等价于“确认”了α 个 token,并且还能再生成 下一个 token,也就是 一次 forward 产出 α+1 个 token,从而达到加速效果。
speculative decoding 的痛点:小模型很难把“下一 token”猜得准
但 speculative decoding 有一个现实难题:
在这个框架里,草稿模型和原始大模型做的是同一件事——给定当前 token 序列,预测下一个 token。想用一个参数规模小很多的模型把这件事做好非常困难,往往导致效果不理想(命中率不够高、收益被稀释)。
另外,草稿模型是独立预测,并没有利用原始大模型在推理过程中已经抽取出来的、非常丰富的语义信息,这也会带来潜在的效率损失。
EAGLE 的动机:别让小模型“盲猜 token”,改为“外推特征”
这些限制启发了 EAGLE。EAGLE 核心想法是:直接利用原始大模型已经计算出来的上下文特征(contextual features)。具体来说,在原始模型预测下一个 token 的过程中,会自然产生倒数第二层(second-top layer)的输出特征向量——这些特征不需要额外计算,我们可以直接拿来用。
EAGLE 基于如下的“第一性原理”(First Principle):特征序列是可压缩的(compressible),因此根据已有特征去预测后续特征向量相对容易。
方法:训练一个轻量插件 Auto-regression Head 来预测“下一步特征”
训练一个非常轻量的插件,称为 Auto-regression Head(自回归头)。它与原始 LLM 的冻结 embedding 层配合工作,用来根据原始模型倒数第二层的特征序列预测下一个特征向量。
接着,使用原始 LLM 的 冻结分类头(classification head)把预测出来的特征映射回 token(即从 feature → token)。
所以整体流程可以概括为:EAGLE 在特征层面做外推:用小的自回归头预测未来特征序列,再用冻结的分类头把特征序列转成 token 序列。
1.2 EAGLE 引入特征 + shifted token
传统 autoregressive decoding 一次只生成一个 token,导致推理慢、成本高。
而 speculative sampling 的思路是用一个更快的 draft 阶段生成一段候选 token,再由 target LLM 并行“验证”这些 token,从而在一次 target 前向里验证多个 token,并且保持输出分布与原始 target 解码严格一致。这也是 EAGLE 的主要目标。
但是问题是:draft model 难找,尤其是小模型(比如 7B)。
speculative sampling 的关键前提是:要有一个输出足够像 target、但明显更快的 draft model。现有路线:降低 draft 开销,但准确率不够。
EAGLE 把提升 speculative sampling 的核心拆成两点:降低 draft 阶段的时间开销、提高 draft 被 target 接受的 acceptance rate。
EAGLE 的两个关键观察(作者认为是“需要重新思考”的点)
作者用两条观察引出 EAGLE:
观察 A:在“特征空间”做自回归比在 token 空间更容易
文中的 “features” 特指 target LLM 的 second-to-top-layer features(LM head 之前的隐向量)。
直觉是:token 序列是自然语言的离散表面形式,而特征序列更“规整”;因此“先预测特征、再用原 LM head 还原成 token”会比直接预测 token 更好。
观察 B:特征自回归会被“采样不确定性”卡住
生成时 target LLM 会从分布里采样 token,引入随机性;而特征是连续高维的,下一步特征取决于你刚刚采样到了哪个 token,因此仅凭当前特征很难确定“唯一正确的下一特征”。
作者用 “I” 后面可能采样到 “am” 或 “always” 来说明:不同 token 分支对应不同的特征轨迹,导致训练/预测目标变得含混。

EAGLE 的核心解法:把“采样结果”显式喂给 draft(shifted token)
为了解决上面的不确定性,EAGLE 在 draft 输入里加入 “shifted token”,从而让 draft 在预测下一特征时知道“刚刚实际采样了什么”。把“采样结果”显式喂给 draft(用 shifted token 作为条件),于是从 预测下一 feature 变成从 预测——例如用 预测,用 预测 。
作者声称这样能显著提高 speedup(能从 1.9x 提到 2.8x)。


1.3 EAGLE——加速 LLM 生成效率
整个 EAGLE 包含两阶段:Draft阶段(草稿生成) + Verification 阶段(目标模型一次前向并行验证)
Draft 阶段(草稿生成)
Target LLM:要被加速的那个大模型;Draft model:用来起草候选 token 的模型。
Feature:通常指 target LLM head 之前那层 hidden state。
记号:
1. token 用小写 ,embedding 用 ,feature 用 ,分布用 。
2. 序列用大写表示,例如 。
LLM 的标准前向链路:输入 token 序列
1. embedding (embedding layer)
2. feature
3. 用 LM head 把 映射为下一步分布 ,再从中采样得到
整个流程就是:
EAGLE 和其它 speculative decoding 最大的不同点在 draft(草稿)怎么生成:它不是直接预测 token,而是先预测 target LLM 的“倒数第二层特征”,再用 target LLM 自己的 LM head 把特征映射成 token 分布并采样 token。
关键 trick:shifted-token
EAGLE 预测下一步特征 时,输入不是仅有历史特征 ,还会额外输入“前移一位”的 token 序列 。
直觉:因为采样会导致“接下来走哪条分支”不确定;把已经采样出来的 token(即采样结果)喂给 draft,就等于把“分支选择”显式告诉了模型,从而让“下一特征”更可预测。
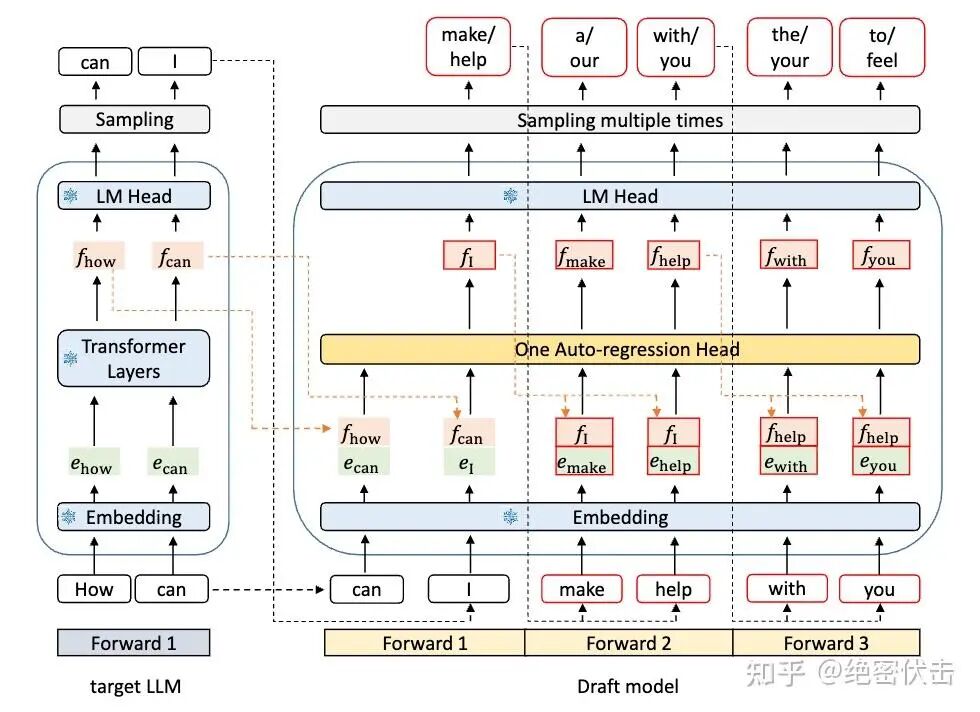
下图是 EAGLE 模型结构,EAGLE 的 draft model 由三块组成:Embedding layer、LM Head、Autoregression Head。Embedding layer 和 LM Head 直接复用 target LLM 参数,不需要训练;训练的主要是 Autoregression Head。
在原始大模型(Original LLM)执行一次 forward 的过程中,我们会收集它倒数第二层(second-top layer)输出的特征向量(features),构成特征序列:(bs, seq_len, hidden_dim) 。并结合这次 forward 由原始 LLM 生成的一个 token,构成shifted token 序列 :(bs, seq_len)。
将以上作为输入:特征序列 (bs, seq_len, hidden_dim) + shifted token 序列 (bs, seq_len)
将shifted token → embedding,然后与 feature 拼接成 (bs, seq_len, 2×hidden_dim)
接着,以这些特征为起点,FeatExtrapolator(特征外推器)开始进入“猜测(guessing)”阶段。
FeatExtrapolator 以自回归方式预测下一个特征向量。随后,我们使用原始模型中冻结的 LM head 来得到 token 的概率分布,并从该分布中进行采样生成 token。
通过多次重复:“预测特征 → LM head 得到 token 分布 → 采样 token”的过程,我们可以形成一种类似树状(tree-like)的生成过程,如下图所示。
在图中的示例里,FeatExtrapolator 只用了 3 次 forward,就“猜”出了一个包含 10 个 token 的树状候选序列。

Verification 阶段(目标模型一次前向并行验证)
用树状结构,让 target LLM 一次 forward 计算整棵 draft tree 上每个 token 的概率(这里会用到 tree attention);
在树上每个节点递归应用 speculative sampling 的接受/拒绝与分布修正,并记录被接受的 token 和对应 feature,供下一轮 drafting 用。
如果不考虑树结构,标准 speculative sampling 在“某一步”可以抽象成:
1. 先从 proposal 采样得到候选
2. 以接受概率 接受它并输出;
3. 若拒绝,则从 修正分布 采样输出。
为什么拒绝需要从修正分布采样?原因是:
直接接受并输出 的概率是
target 还缺的那部分就是 ,所以拒绝后从 补回来,正好凑成 。论文也明确说这等价于直接从 target LLM 采样。
上面是不考虑树结构,树结构下,同一个位置不是 1 个候选,而是 k 个候选 tokens。
链式:拒绝一个候选 → 立刻从修正分布采样结束
树状结构:拒绝第 1 个候选 → 不要结束,继续用算法上面的 speculative sampling 去尝试第 2 个候选;…;直到第 k 个
若 k 个全拒绝 → 才从修正分布采样结束
直觉:你有一组候选 ,你希望“能接受就接受”(省算力/更可能对),但又必须保证最终等价于从 采样。
具体流程如下:

1.4 EAGLE 训练
EAGLE 把“预测下一特征”当作回归任务:用 Smooth L1 做回归损失 :
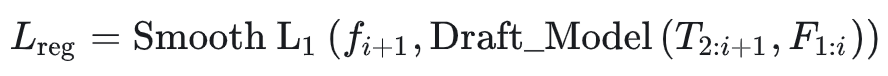
但最终目的是让 token 对,于是还加了一个 classification loss:用 target 的真实特征 和 draft 预测特征 经 LM head 得到两份 token 分布,做交叉熵 :

最后组合成:

实现细节里提到:因为数值尺度上分类损失通常比回归损失大一个量级,所以设 。
1.5 实验
Temperature 对加速的影响

作者发现 T=0(greedy)通常比 T=1(非贪心采样)更快。例如 LLaMA2-Chat 13B:
T=0 speedup 约 3.01×–3.76×
T=1 speedup 约 2.66×–2.89×
作者还指出 代码生成(HumanEval)加速最明显,原因是代码里模板/固定结构多,draft 更容易对。
1.6 MoE 加速效果下降
加速比 | 接受 token | 接受率 pos 0 | pos 1 | pos 2 | pos 3 | pos 4 |
|---|---|---|---|---|---|---|
1.5x | 3.25 | 0.67 | 0.62 | 0.61 | 0.64 | 0.63 |
在 Mixtral 8×7B Instruct 上,MT-bench (T=0) speedup 只有 1.50×,τ=3.25。加速效果下降的主要原因是:
MoE 正常逐 token 解码时,每个 token 通常只需要读取 两个 experts 的权重(top-2 gating)。
但 speculative 的验证阶段会在一次 forward 里处理 多个 token。这时这些 token 可能会被路由到不同的 experts,导致一次 forward 需要访问 超过两个 experts 的权重。
对比 dense decoder-only:dense 模型不管你一次 forward 里算 1 个还是多个 token,该层的所有权重本来就都要读,所以更容易把“多 token 并行”的收益吃满。
这段话其实点破了:speculative 的验证阶段把“每次 forward 处理多个 token”的优势建立在“同一套权重被更充分复用”之上;但 MoE 的权重是按 expert 选择性读取的,多 token 反而扩大了需要读取的 experts 集合,权重复用变差 → 内存/带宽压力上来 → speedup 被吃掉。
1.7 Batch size 影响
作者指出推理常是 memory-bound,speculative 的核心是更好利用算力;batch 越大,可用算力余量越小,所以 speedup 会下降。

02 EAGLE-2
和 EAGLE-1 比,EAGLE-2 的主要改进是把“固定形状的静态 draft tree”换成“基于上下文动态调整的 draft tree”,并取得了比 EAGLE-1 快 20% 以上的效果。

前面的 EAGLE-1 用了静态(固定形状)的 draft tree。这种做法隐含了一个假设:某个 draft token 会不会被接受,只取决于它在树里的位置。
但这和 speculative sampling 的直觉有冲突:既然“有些 token 更简单,小模型更容易预测对”,那同一位置在不同上下文下的“简单程度”也应当不同——树形结构不应该固定。
而通过实验发现:接受率不仅 position-dependent,还强烈 context-dependent,所以静态树有先天上限。
我们可以“根据接受率动态调整树形”,但接受率本身需要 original LLM 的 forward 才拿得到,这和 speculative sampling “减少大模型 forward 次数”的目标冲突。
作者发现 EAGLE 的 draft model 是 well-calibrated 的——draft 给出的 token 概率(confidence score)是接受率的一个很好近似,因此可以用它作为“低成本的接受率估计”,从而实现 context-dependent 的动态树。
于是提出 EAGLE-2:利用 draft 的置信度近似接受率,动态调整 draft tree,目标是“每轮验稿能接受更多 token”。
2.1 上下文相关的接受率
EAGLE 总是用固定(static)的 draft tree 形状;EAGLE-2 会根据上下文动态调整 draft tree 形状。比如下面的例子:
(A) Query = “10+2=”
当 query 是 “10+2=” 时,下一个 token 非常容易预测,很大概率就是 “1”(因为答案是 12)。
EAGLE(静态树)会怎么做?因为树形固定,它“无论上下文是否确定”都会在这个位置塞多个候选分支:除了正确候选 “1”,还会再加一个候选(图注举例是 “3”)。但在这种上下文里,“3” 成为正确下一个 token 的概率极低,所以这个额外分支基本是在浪费 compute / verify budget。
EAGLE-2(动态树)会怎么做?因为它会看上下文“有多确定”,对于这种简单 query,它只放一个候选 “1”,不再硬塞第二个分支。
(B) Query = “10+2”
当 query 变成 “10+2”(注意没有等号)时,下一个 token 变得难预测,因此 EAGLE-2 会在这里加 两个候选。

EAGLE-1 / 许多树状 speculative decoding 方法默认一个假设:草稿 token 的接受率(acceptance rate)主要由它在草稿树里的“位置”决定,所以用一个固定形状(静态)的草稿树就够了。EAGLE-2 要验证的是:
接受率真的“只”跟位置有关吗?如果不是,那静态树就会有先天上限,需要动态树。
为此,作者在 Alpaca 数据集 + Vicuna 7B 上,统计草稿树里不同位置的 token 接受率,如下图所示:
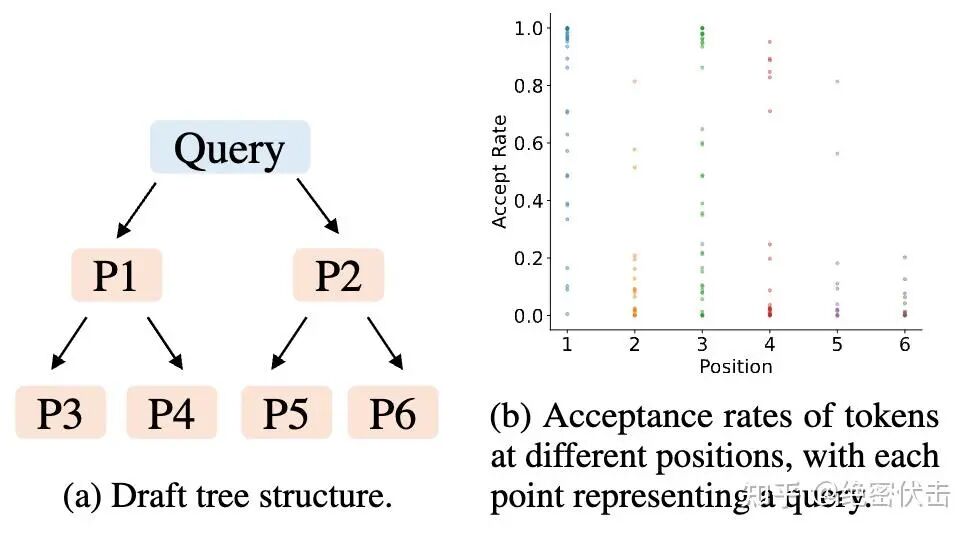
左图给出一个示意草稿树,并标了 P1–P6 六个位置(从“更靠近根、更靠左上”的位置,到“更深、更靠右下”的位置)。
右图横轴是位置(1–6 对应 P1–P6),纵轴是接受率;每一个点代表一个具体 query(上下文)在该位置上的接受率。
关键观察 1:接受率确实“位置相关”
P1 最高、P6 最低;也就是越靠左上(更浅、更早)的 token 越容易被 target LLM 接受,越靠右下(更深、更晚)的 token 越难被接受。 这也解释了为什么像 EAGLE / Medusa 这类静态树会倾向于“左上更密、右下更稀”:把算力花在更可能被接受的位置上。
关键观察 2:但同一位置的方差很大——接受率强烈“上下文相关”
更重要的是:即便固定在同一个位置(比如都在 P3),不同 query 的接受率也会差很多。论文明确说他们观察到了 significant variance,因此接受率“不仅与位置有关,也与上下文有关”。
静态草稿树只能利用“位置先验”,但无法利用“上下文难度差异”;而上下文差异很大,所以静态树存在天然上限,动态树有更大潜力。
这就是 EAGLE-2 后面要做的事:让草稿树结构随着上下文而变(context-aware dynamic draft tree),把 token/分支预算动态投到更可能被接受的地方。
2.2 用 draft 置信度当“接受率估计”
要做 动态草稿树,就得知道每个草稿 token “大概率会不会被 target LLM 接受”(acceptance rate)。但如果为了算接受率又去跑一次 target LLM forward,那就违背 speculative decoding 的初衷(本来就是要减少 target LLM 的 forward 次数)。因此论文提出需求:必须有一种不调用原始 LLM 的低成本接受率估计方法。
核心观察:draft 的置信度 ≈ token 的接受率(“校准良好”)
作者在 Alpaca 数据集上做实验,研究 draft model 的置信度分数(对某个 token 的输出概率)与该 token 的实际接受率之间的关系。
结论非常直接:两者 强正相关,而且几乎接近一条从 (0,0) 到 (1,1) 的线,如下图所示:

论文给了两个很有代表性的数值区间:
置信度 < 0.05 的 token,接受率大约 ≈ 0.04
置信度 > 0.95 的 token,接受率大约 ≈ 0.98
因此他们把这种性质称为 well-calibrated:draft 模型给出的概率在经验上可以很好地近似 token 的接受率。
直接推论:用 draft 置信度当“接受率估计”,几乎零额外开销
有了上面的现象,就可以在不额外调用 target LLM 的情况下,用 draft 的 confidence score 作为 acceptance rate 的 proxy,从而支持动态调整草稿树结构,且“无额外 overhead”。
作者还提到:类似的现象在其它方法的 draft 模型里也观察到(例如 GLIDE、CAPE)。
2.3 上下文感知草稿树
EAGLE-2 不改 draft model 的训练/推理方式,也不改 verification stage 的机制;改动只发生在“怎么构建 draft tree 以及给原模型验的时候喂哪些 token”。
把动态草稿树拆成两步:
Expansion phase(扩展):每一层只扩展“最有希望最终被接受”的少数节点,避免树指数爆炸。
Reranking phase(重排):扩展出来的节点未必是“全局最值得验”的,所以把所有草稿节点统一打分重排,挑出 top-m 组成最终要验的草稿“子树”,再 flatten 成 1D 输入给原模型,并配套改 attention mask。
Expansion Phase:怎么扩展下一层(只扩展 top-k)
即使有 tree attention,draft model 可以在一次 forward 里同时算一层所有节点的 next-token 概率,但一层节点太多会拖慢 forward,而且树层数一深会指数增长,所以必须“挑节点扩展”。
在 speculative 框架里,一个 token 最终能被接受,前提是路径上所有前缀都被接受。因此作者定义节点 的“全局接受概率”为整条路径接受率的乘积:
真实接受率用 表示,但拿到它要跑原模型
于是用 draft model 的 confidence score 近似 ,得到:
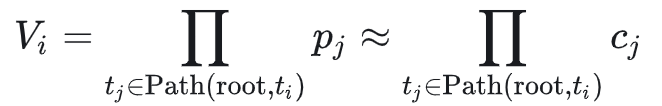
在“当前最后一层”里,选 value 最大的 top-k 节点作为下一次 draft model 的输入,把它们扩展出的新 token 接到树上。 下图是一个具体例子,边上的值代表draft model 的 confidence score,方块里括号的数字代表 value。
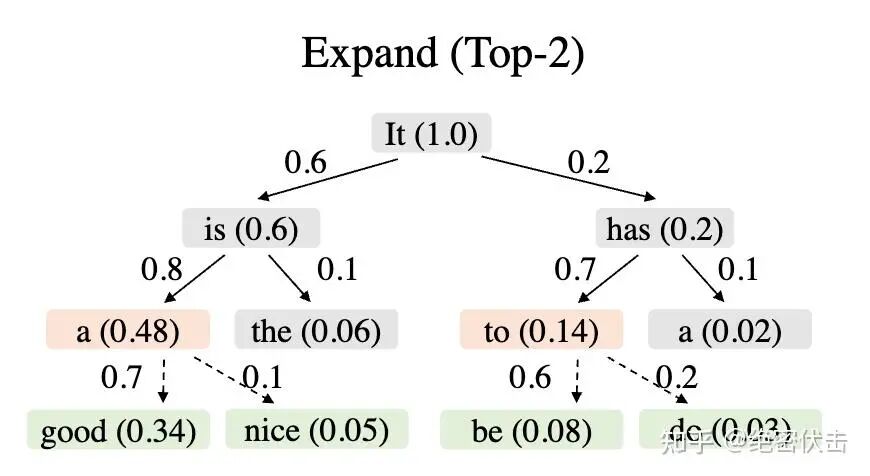
Reranking Phase:为什么还要重排、怎么选 top-m
扩展的目的是“把树加深”,但因为每多走一步乘一个 [0,1] 的数,更深的节点 value 往往更小。所以可能出现:某些“没被扩展的浅层节点”,其实 value 比“已经扩展出来的深层节点”更高。
因此不直接用扩展阶段选的节点当最终草稿,而是对所有草稿节点统一 rerank。
具体做法
在整棵草稿树的所有节点里,选 value 最高的 top-m 节点。
为了保证挑出来的仍然是一棵“连通的树”,作者利用一个性质:子节点的 value ≤ 父节点的 value;如果 value 相同,优先选更浅的节点,这样 top-m 仍会形成连通结构。
Flatten + Attention mask(非常关键)
选出 top-m 后,要把树“拍平”为 1D 序列喂给原模型做并行验证;但 attention mask 不能用普通因果三角阵:
不同分支的 token 不应该互相可见
每个 token 只能看到它在树上的祖先节点
所以要按树结构构造 attention mask,保证验证阶段与标准自回归分布一致(lossless)。

2.4 实验
指标:
Speedup Ratio:相对 vanilla AR 的真实加速比。
Average Acceptance Length τ:每个“draft→verify”循环平均能被接受的 token 数。
Q1:为什么不把 acceptance rate 当核心指标?
acceptance rate 只反映 draft model 本身;而 EAGLE-2 不改 draft model 结构/训练,所以 acceptance rate 与 EAGLE 一样,不能体现 EAGLE-2 的改进点。
Q2:EAGLE-2 两个关键设计到底值不值
1)用 “value” 排名扩展节点,而不是只看单点 confidence
作者指出:EAGLE 的 draft model 的 confidence 能近似 acceptance rate,但它是局部的,无法反映“某个节点最终被接受”的真实概率;因此 EAGLE-2 在选扩展节点时,用 value =(路径上各节点 confidence 的乘积)来做“全局接受概率”的代理,并在消融里比较 “按 value 扩展” vs “按单点 confidence 扩展”。结论是:按 value 扩展时 speedup 和 τ 都更高。
2)Reranking 是否必要
扩展阶段的目标是“加深树”,但深层节点的 value 往往更小,可能不如一些没被扩展的浅层节点;所以 EAGLE-2 在 reranking 阶段会把候选节点重新排序再选 top-m。作者在 MT-bench 与 GSM8K 上做了消融,结论是:reranking 会同时提升 τ 和 speedup。
03 EAGLE-3

维度 | EAGLE-1 | EAGLE-2 | EAGLE-3 |
|---|---|---|---|
核心目标 | 在无损的 speculative decoding 中,复用目标模型(target)的顶层特征来增强小型 draft,从而提升接受率 | 在 EAGLE-1 的树状草稿基础上,把“固定树”变成上下文相关的动态树,减少资源浪费 | 进一步提升可扩展性与稳定性:训练-推理一致(training-time test)+ 去掉特征预测约束 + 多层特征融合 |
Draft 的“生成单位” | feature-level autoregression:先自回归生成特征,再用 target 的 LM head 得到 draft token | 同 EAGLE-1(仍是 EAGLE 框架),但树结构生成策略改成动态 | 仍沿用 EAGLE 的 draft→verify 框架,但 draft 的输入与训练发生了显著变化:既可以使用来自 target 的特征 (g),也需要在多步场景下接收并利用自身生成的中间表示 (a)。 |
草稿结构 | 树状 draft(同一位置多 token),用 tree attention 并行验证 | 动态草稿树:用 draft 置信度近似接受率,按上下文动态生成并在末尾剪枝 | 沿用 EAGLE-2 的上下文动态树 |
训练目标 | 有 feature prediction 相关约束(论文中称 feature prediction loss l_fea)——这会限制“靠加数据继续提升”的空间 | 同 EAGLE-1(EAGLE-2 主要改树生成/剪枝策略) | 移除 feature prediction loss(l_fea),从而能更自由地用中间层特征、提升 scaling |
使用哪些 target 特征 | 主要复用 top-layer features(LM head 前一层) | 同 EAGLE-1(仍以 top-layer 复用为主) | 引入 多层特征融合(low/mid/high → concat → FC 得 g),不只依赖 top-layer |
推理阶段输入 | 主要是 target 的 top-layer 特征 + 上一步采样 token 信息 | 同 EAGLE-1 | Step 2/3 起,由于这些 token 尚未经过 target 验证,无法获得融合特征 (g_I / g_{do}),改用 draft 自身生成的中间表示 (a_I / a_{do}) 作为替代输入 |
效果总结(论文给的结论性说法) | 相对 vanilla AR 明显加速(具体数值取决于模型/任务) | 相比 EAGLE-1:通过动态树减少浪费、提升效率 | 相比 EAGLE-2:总体 20%–40% speedup 改善,并在多任务/多模型上达到更高 speedup 与平均接受长度 |
上面的表格描述了 EAGLE-3 和 EAGLE-2 和 EAGLE-1 的主要区别。
EAGLE-3 的两大关键改动
A)去掉特征预测约束:从“预测 feature”改为“直接预测 token”
在 EAGLE 的训练目标里,loss 由两部分组成:feature prediction loss 和 token loss 。其中 要求 draft 在特征空间拟合 target 的 top-layer feature,这在一定程度上帮助模型只训练 Step 1 也能泛化到 Step 2,但同时也带来了额外约束:如果最终目标是把 token 猜对,那么“先把输出拉回到特征形态再映射到 token”会限制 draft 的表达能力,使得仅靠扩大训练数据很难继续显著提升加速效果。

EAGLE-3 的第一个关键改动就是:直接移除 ,让 draft 不再必须拟合 target 的 top-layer feature,而是更直接地服务于“猜 token”,从而释放模型容量,让“加数据”真正能转化为更高的 Step 1 接受率。
如下图的左边所示,你会看到当训练数据规模增大时,第一个 draft token 的接受率(0-α)显著提升。
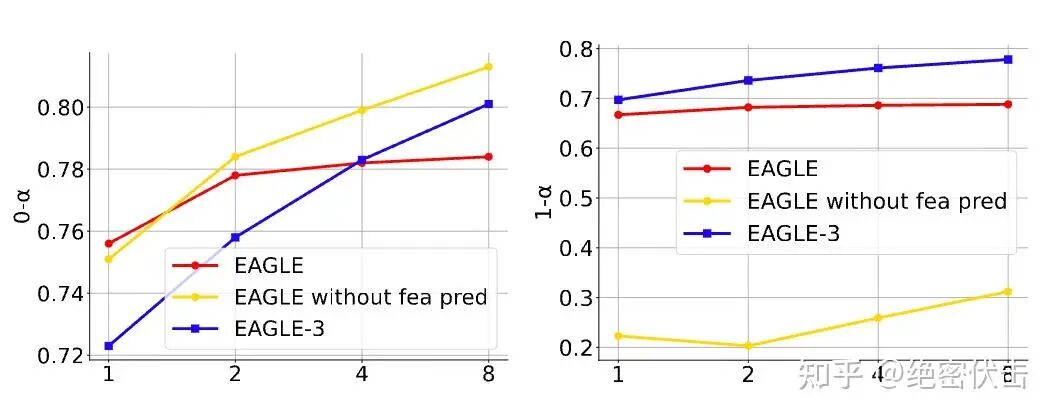
但这个改动会立刻引出一个新问题: 如果训练只覆盖“Step 1 的直接 token 预测”,那么到了 Step 2、Step 3,draft 的输入里会混入它自己前一步生成的中间输出(论文里用 表示),而这些自生成量与训练时看到的分布不一致,导致 distribution shift / 误差累积。下图是训练-推理示意图:

于是就出现了 图 3-2(右图) 的典型现象:0-α 上去了,但第二个 token 的接受率(1-α)反而会崩得很低——也就是说,只去掉特征约束会让“第一步更准”,却让“多步更不稳”。
B)Training-time test:训练时“模拟测试时的多步自回归”
为了解决上面这种“训练-推理不一致 / 多步误差累积”,EAGLE-3 引入 training-time test:训练时不再只训练 Step 1,而是在训练过程中显式执行“测试时会发生的步骤”。如下图所示:

把 Step 1 生成出来的中间量(记作 或 )回灌到后续 Step 2/Step 3,让模型在训练阶段就经历与推理一致的输入形态(即:输入里既包含来自 target 的特征,也包含 draft 自己生成的中间表示)。
它带来的直接效果是:当输入里包含越来越多“自预测量”时,EAGLE-3 依然能保持稳定的接受率,而不会像只做 Step 1 训练那样在后续步骤崩掉。
如图3-2(右图)所示,training-time test 让 1-α 不再随数据规模增大而恶化,反而能够随着训练数据增加一起改善;也就是说,EAGLE-3 同时实现了:
Step 1(0-α):受益于“去约束 + 加数据”,更容易猜对;
Step 2/3(1-α 及以后):受益于“训练时模拟推理”,输入分布对齐,误差不再累计,接受率不再明显下滑。
下面我们介绍下具体的实现细节。
3.1 Inference Pipeline
和标准 speculative sampling 一样,EAGLE-3 仍然是 draft→ verify(用 target 并行验收) 的交替框架。区别集中在 drafting 阶段:draft 模型不再“预测 target 的 feature”,而是围绕“更好地猜 token”重新设计了输入形态。
论文用一个例子说明 EAGLE-3 的 Inference Pipeline,如下图所示:

prefix 是 “How can”:
1)target 先做一次 forward:产出下一个 token + 多层特征
在 prefill 或上一轮 verification 里,target 会对当前前缀做 forward,生成下一个 token(例子里是 “I”)。同时把 target 的 低/中/高层特征序列都记录下来,分别记为 l, m, h。
2)把多层特征融合成 g(“给 draft 的条件信息”)
对前缀里每个位置(比如 how、can),取它在 l/m/h 里的 维向量拼接成 维,再过一层 FC 降回 k 维,得到融合后的特征 g(例子里就是 。这里 是 target 的 hidden size。
直觉:EAGLE/EAGLE-2 更依赖 top-layer feature;EAGLE-3 把“可用信息”扩展到 low/mid/high 多层,再压成一个统一的 (g),让 draft 在猜 token 时条件更强。
3)为什么还要喂 token embedding e(“让 draft 看见随机采样的结果”)
如果只把 给 draft,它其实看不见 target 采样出来的那个随机结果(例子里 target 采样到了 “I”)。论文说得很直接:只输入 g,draft “cannot access the random sampling process”,所以像 EAGLE 一样,把采样 token 的 embedding(这里是 )也引入。
4)draft 模型本体:单层 decoder 输出 a,再用 LM head 采样 token
做法是把(g 与 e 的)拼接向量再过一个 FC 压到 k 维,然后送进 单层 Transformer decoder layer,产出一个不受约束的向量 a。最后把 喂进 LM head 采样,得到 draft token(例子里采样到 “do”)。
图 3-5把 draft 过程拆成多步(①②③),关键规律是:
已经被 target “看过/验证过”的 token:你能拿到它的融合特征 g,就用 g。
还没被 target 验证的 token:你拿不到它的 g,就用上一 step 里 draft 自己产出的 a 去“顶替”。
把图 3-5的例子完整走一遍会更清楚:
Step 1(前缀 “How can”)
已知前缀 how、can 都来自 target 已处理过的上下文,所以直接复用 。
还需要把 target 刚采样出来的 “I” 的 embedding 加进来。
draft 产出 ,经 LM head 采样出 “do”。
Step 2(前缀变成 “How can I”)
理想情况当然是: 都能从 target 拿到。 但论文强调:拿不到 ,因为 token “I” 还没被 target check/verify,所以 target 没法给你它的融合特征。
于是 EAGLE-3 的做法是:用 Step 1 里 draft 自己产生的 来替代 。
并且这一步要把刚采样出来的 “do” 的 embedding 拼上。
Step 3(继续往后,比如要生成 “it”)
同理,到了 Step 3:你也拿不到 ,所以用 顶上,再拼上 作为下一步输入。
3.2 训练草稿模型
1) 训练目标:让草稿模型适应“混合输入分布”
在 EAGLE(含 EAGLE-2)里,draft model 的输入基本是 target model 的 top-layer feature(记为 )。而在 EAGLE-3 里,draft model 的输入会在推理时出现两类东西:
来自 target 的 fused features: (由 low/mid/high 特征融合得到的 (g))
来自 draft 自己的输出向量: (因为后续步拿不到 target 的 ,只能用自己上一步生成的 代替)
所以问题变成:训练时如果只喂 ,推理时一旦开始用 回灌(feedback),输入分布立刻 shift,后续 token 接受率会崩。EAGLE-3 需要解决:让 draft 学会在“ ”混合输入下也稳定工作。
2) 核心方法:Training-time test(训练时模拟Train/Test的多步回灌)
论文用一句话概括训练流程是:在训练中加入“test steps”:生成一次 ,再把 喂回去继续训下一步,让模型在训练阶段就经历推理时会遇到的“自回灌输入”。
这也是 EAGLE-3 相比 EAGLE-1/EAGLE-2 最关键的“训练-推理一致性”手段之一:它不是靠加一个 feature loss 去约束,而是 直接在 token 目标下,把推理闭环搬进训练。
3) Draft 模型结构:为何“只改 self-attention 就够”
EAGLE-3 的 draft model 核心是一个 Transformer decoder layer。论文强调:除了 self-attention,其他组件并不“读上下文结构”,因此训练/测试不需要额外改;真正需要动的是 self-attention 的 mask / 计算方式。
直观原因:training-time test 会把“序列”变成“树状依赖”,而标准 causal mask(下三角)只表达线性自回归,不表达“某个预测 token 的父节点是谁”。
4) Attention mask 怎么改:从“下三角”到“树状因果关系”

如图 3-6 所示:原始训练数据是长度 3 的序列 “How can I”,它的依赖是正常链式,所以 mask 是标准下三角(图 3-6 左上角)。
但在 training-time test 中,会出现这样的情况:模型在某一步输出了 “are / we / do”,这三个 token 在语义上分别挂到 “how / can / I” 这些位置上,形成 tree-like contextual relationship。所以当你把 “are we do” 作为下一轮输入时,它们各自允许看的“历史”不是简单的 0..t-1 全部,而是“沿着树的父链”去看。
5) 计算优化:为什么用 dot-product 而不是完整矩阵乘
如果你直接用标准 attention 的 矩阵乘法,在这些“几乎对角”的 mask 上会产生大量无用计算(大多数位置被 mask 掉)。因此论文建议:在这种结构下,用 vector dot products 只算“需要的那几对位置”的 attention score,会更省。
这点对工程实现很关键:training-time test 让训练步骤多了几轮“模拟推理”,如果 attention 不做稀疏化/按需计算,训练开销会被放大。
3.3 实验
和 EAGLE-2 和 EAGLE-1 相比,加速比有很大提升,如下图所示:

下图则显示了 EAGLE-3 没有出现误差累计:
EAGLE:随着输入里“来自 draft 自己的估计”变多,接受率明显下滑;
EAGLE-3:接受率几乎不变,说明 training-time test 的有效性。

此外,作者还做了两组消融实验:
1. 移除 feature prediction constraint(“remove fea con”)
2. 融合 low/mid/high 层特征(fused features),替代只用 top-layer features
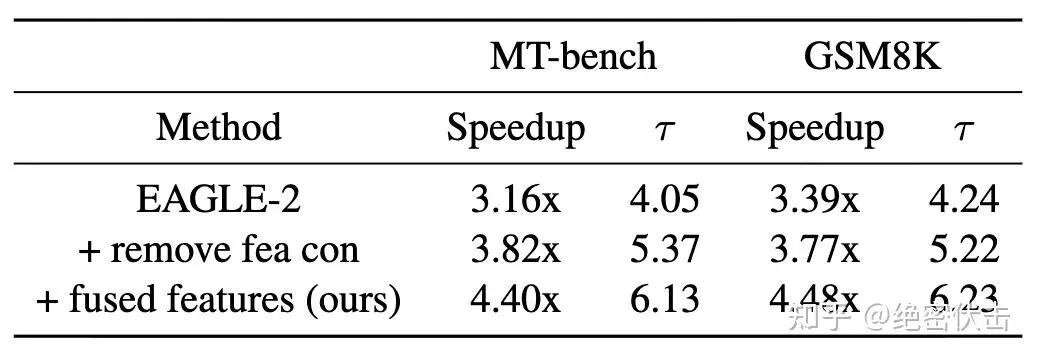
去掉 feature 约束先带来一大步(τ 明显上升),再做多层特征融合还能再推一截。
EAGLE-3 in SGLang:大 batch 下吞吐还能涨
作者先解释:speculative 的收益通常来自“memory-bound decoding 的冗余算力”,batch 越大这种冗余越少,所以大 batch 很难还有效;并且工业框架更优化,提升更难。
但 SGLang v0.4.4 的测试显示:
batch=64 时 EAGLE-3 仍有 1.38× 吞吐提升(+38%);而 EAGLE 在 batch=24 时就开始降低吞吐。

EAGLE-3 in vLLM:同样看大 batch 吞吐
作者也在 vLLM 上测了“大 batch 吞吐影响”,结果表明 EAGLE 的吞吐提升峰值出现在 batch=24,而 EAGLE-3 的峰值推迟到 batch=56。

3.4 代码实现
官方实现可以参考:https://github.com/SafeAILab/EAGLE 以及 https://github.com/sgl-project/SpecForge
但是官方给的代码对显存要求较高,在 8 *H800上训练gpt-oss-120b EAGLE3,最大长度不能超过16K。如果你想训练更长,可以参考下面的链接,可以训到 40K:https://github.com/juemifuji/eagle3-aimo3
04 DFlash
DFlash 是近期的一项工作:一种在投机解码(speculative decoding)中,用轻量级的块扩散模型(block diffusion model)来充当 draft(草稿)模型的方法。它能够实现高效且高质量的并行草稿生成,从而把投机解码的加速效果推到更高的上限。
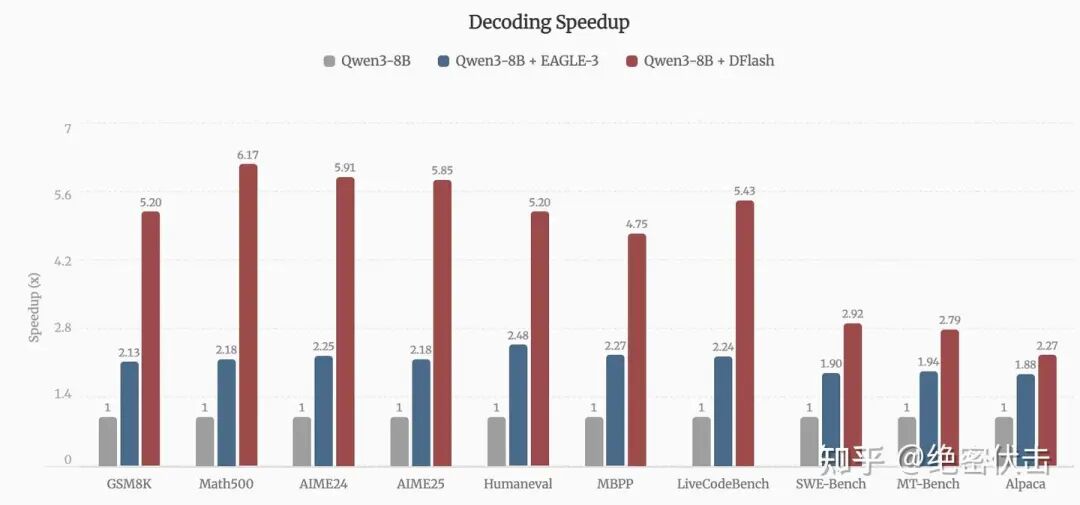
在实验中,DFlash 在 Qwen3-8B 上实现了最高 6.17× 的无损(lossless)加速;比前面的 EAGLE-3 快三到 2.5×。
4.1 为什么选择 DFlash
自回归的大语言模型(Autoregressive LLM,简称 AR LLM)已经重塑了 AI 领域,但它们的一个核心缺陷来自严格的序列生成机制:推理必须逐 token 生成,导致推理速度慢,同时也使得 GPU 计算资源经常无法被充分利用(算力“吃不满”)。
投机解码(speculative decoding)正是为了解决这一瓶颈:它先用一个更小的 draft(草稿)模型快速生成一段候选 token,然后由更大的 target(目标)模型对这些 token 进行并行验证。这一思路确实有效,但像 EAGLE-3 这类方法在草稿阶段依然采用自回归式的逐 token 起草。这种“串行起草”既效率不高,又容易产生误差累积,因此在 Qwen3 这类主流模型上,加速比往往被限制在大约 2–3× 左右。
相比之下,扩散式语言模型(Diffusion LLM,简称 dLLM)具备并行生成文本与双向上下文建模的能力,理论上是自回归生成的一个很有吸引力的替代方案。但现实是:当前 dLLM 的整体表现通常仍弱于同规模的自回归模型;并且为了保证生成质量,dLLM 往往需要较多的去噪迭代步数(denoising steps),这又限制了它们在推理阶段的“纯速度”优势。
因此这里出现了一个明确的权衡:
自回归模型更强、更准,但推理慢;
扩散模型可以并行生成、更快,但往往更不准(或质量更难稳定),而且迭代步数多会拖累速度。
那么,能否把两者的优点结合起来,同时规避各自的短板?
作者给出的自然思路是:用扩散模型做 drafting(利用并行性快速起草),再用自回归模型做 verification(利用其强能力做严格验证)。
4.2 DFlash 原理
用扩散模型来做 drafting(草稿生成)并不是一件容易的事,主要有两个现实障碍:
1) 现有的“扩散投机器(Diffusion Speculator)”不实用
像 DiffuSpec 和 SpecDiff-2 这类方法,往往依赖非常大的草稿模型(例如 7B 参数级别)。 这会带来两个直接问题:
显存占用高,线上部署(serving)成本非常大,很多场景根本扛不住;
即使这样,整体加速也往往只有 约 3–4×,并不能把投机解码的上限真正推高。
2) “小扩散模型”直接缩小并不好用
既然 7B 太大,是否可以把扩散 drafter 变小?但结果是简单缩小会失败。 作者做了一组实验:
从零训练了一个轻量级的 5 层块扩散模型(block diffusion model),block size = 16;
训练数据来自 Qwen3-4B 生成的数据;
然后在一些数学任务上,用它来给 Qwen3-4B 做 speculative decoding。
结论是:如果不引入额外机制(作者说的“additional help”),这个小模型的推理能力不够。如下图所示,小模型很难和目标模型对齐,导致 acceptance(接受率)不高,最终 speedup(加速)也很有限。

那么我们能不能做出一个 drafter:既足够小(意味着快、便宜、好部署),又足够准(意味着高接受率、能带来大加速)?
这一问基本就是 DFlash 接下来要解决的核心矛盾:“小而准”的扩散草稿模型如何可能。
作者发现:大规模自回归目标模型(AR target)在其隐藏层特征(hidden features)里,隐式地包含了关于未来 token 的信息。
换句话说:目标模型在处理当前上下文时,内部表征里其实已经“带着一些对后续会生成什么的倾向/线索”,只是这些信息通常不会被直接拿出来用。
DFlash 的做法:别让小模型从零推理
与其让一个很小的扩散模型“从零开始推理、自己对齐目标模型”,DFlash 选择的路线是:
先从目标模型里提取上下文特征(context features)
让草稿扩散模型在这些特征条件(conditioning)下生成草稿 token
这样做的效果是把两种模型的优势“拼起来”:
大目标模型:提供强推理能力与更可靠的语义/逻辑线索(通过 hidden features 传递)
小扩散 drafter:利用扩散模型的并行生成能力,快速一次性起草多个 token
作者把这个视为一种“融合”:用大模型的深度推理能力给小扩散模型指路,再用小扩散模型的并行生成把速度拉满。
下图展示了 DFlash 的整体系统设计:

核心流程可以拆成四步:
1) 特征融合(Feature Fusion)
在 prefill(首次前向、建立上下文)或 verification(目标模型验证草稿)之后,我们从目标模型(target)中提取隐藏层特征(hidden features),并对这些特征进行融合处理(fuse)。
直观理解:目标模型刚算完一轮,它内部“已经理解了上下文并形成了高质量表征”,DFlash 直接把这份“理解”提取出来作为草稿生成的强条件信息。
2) 条件注入(Conditioning)
这些融合后的特征会被直接送入草稿模型各层的 Key/Value 投影(K,V projections)里,并缓存到草稿模型的 KV cache 中。
这句话非常关键:
不是简单把特征拼到输入 embedding 上;
而是更“注意力机制友好”的注入方式:直接影响 draft 模型注意力的 K/V(也就是“它该关注什么、如何组织上下文信息”)。
这样 draft 在生成时就能以目标模型的表征为“导航”。
3) 并行起草(Parallel Drafting)
在上述“富上下文条件”(rich context)以及最后一个已验证 token 的条件约束下,草稿模型用扩散方式并行预测下一段 token block(比如一次预测一个 block)。
你可以把它理解为:
自回归 drafter:下一 token、再下一 token……串行写草稿;
DFlash drafter:一次性把“下一段”草稿并行写出来,然后交给 target 去验收。
4) 降低开销的工程策略(Minimize overhead)
为了把额外开销压到最低,DFlash 做了两个很实用的设计:
1. 草稿模型复用目标模型的 embedding 层和 LM head(输出头)
embedding:把 token 映射到向量空间的那层
LM head:把隐状态映射回词表 logits 的那层 这样能省参数、减显存、也减少训练/部署复杂度。
2. 只训练中间层(intermediate layers)也就是说,draft 模型主要学的是“怎么在注入了 target 特征后,快速把中间表征变成可用的下一段 token 分布”。
作者最终把 draft 的层数设为 5 层,理由是:在“草稿质量(接受率)”和“生成速度(drafter 成本)”之间取得一个折中。
4.3 实验
将 DFlash 与当前 EAGLE-3 进行了对比评测。
DFlash 的配置
drafting 的 block size = 16(一次并行起草 16 个 token 的块)
扩散去噪步数(denoising steps)设为 1(非常激进地追求低开销)
EAGLE-3 的配置
speculation length(一次起草长度)设为 7
实验设置
上下文长度为 2048
所有测试都关闭 Qwen3 的 “thinking” 模式
下面是对比结果:

参考
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
DFlash: Block Diffusion for Flash Speculative Decoding










