绑定手机号
确认绑定









作者:小波基
地址:
https://zhuanlan.zhihu.com/p/1930244241625449814
https://zhuanlan.zhihu.com/p/1933259599953232589
经授权发布,如需转载请联系原作者
01 前言
随着OpenAI o1以及DeepSeek R1的爆火,后训练(Post-Training)在大模型端到端训练过程中的占比也逐渐提升。大家发现强化学习不仅能使模型与人类社会价值观对齐,还能提高模型的逻辑推理(Reasoning)能力。而且其自我迭代的训练范式在一定程度上也解决了困扰预训练(Pre-Training)进一步扩展的数据困境,因此受到了格外关注。
LLM强化学习后训练框架大致可以分为共置式(Task-Collocated)与分离式(Task-Separated)两类。共置框架下,各个计算任务部署在整个集群上串行执行,构成一个时分复用的系统;而分离框架则允许部分或全部计算任务布放在不同的设备,构成一个空分复用的系统。


我简单统计了一下近几年的部分相关工作,发现从今年开始,分离式架构逐渐成为了主流(其实很多共置式框架也支持把诸如Reference Inference等计算分离部署,但这里我们主要关注Actor Rollout和Actor Update是否分离)。
框架 | 发布时间 | 架构 |
|---|---|---|
DeepSpeed-Chat | 2023 | Task-Collocated |
NeMo-Aligner | 2024 | Task-Collocated |
RLHFuse | 2024 | Task-Collocated |
verl | 2024 | Task-Collocated |
OpenRLHF | 2024 | Task-Separated |
K1.5 | 2025 | Task-Collocated |
SeedThinking-1.5 | 2025 | Task-Separated |
StreamRL | 2025 | Task-Separated |
AReal | 2025 | Task-Separated |
slime | 2025 | Task-Separated/Collocated |
siiRL | 2025 | Task-Separated |
那么这背后的原因到底是什么呢?总结下来可以分为两个主要原因:提高效率与降低成本。
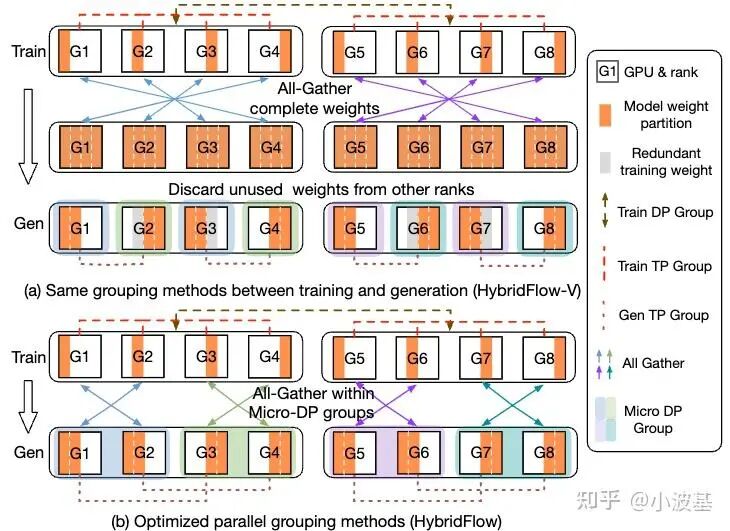
首先从效率上说,训练与推理的计算负载特性明显不同,训练是计算密集型任务,而推理Decode阶段则是访存密集型任务。从下图可以看出,训练推理任务的Scaling Law有显著区别,并且二者之间的差距会随着集群规模的扩大与序列长度的增加而更加显著。而实际上一个后训练系统所需要推理和训练的Token总量是很接近的(只有训练Prompt部分有差异),因此对于强行绑定了训推资源的共置式架构而言,其Scaling效率会显著受限,导致其在大规模后训练中的效率可能并不尽如人意。
另外,共置式架构下存在大量不可掩盖开销。每一个计算任务结束后,都需要进行模型的On-Load或Off-Load,而且对于Actor Rollout与Actor Update而言,往往还需要进行Resharding(训推模型最优切分不一致),这部分时间会随着模型的增大与并行策略的愈发复杂,成为端到端时间中不可忽视的部分。
而从成本角度上说,分离式架构有可能将RL框架作为一个顶层的调度模块,从而复用已有训推集群,并利用异构计算资源进行后训练,从而降低开销。
进一步从业务角度思考,后训练接下来必然会引入Multi-Agent、Tool Calling等更多组件。此时若还是采用串行的计算流程,整个系统的端到端吞吐会变得很难看。
因此在这里给出一个观点:未来的强化学习后训练框架,很可能是分离式架构的天下。
02 分离式架构中的挑战
既然分离式架构这么好,为什么之前大家用得并不多呢?这就和分离式架构先天的缺点有关了。
前面提到,强化学习算法里有多个计算任务,其中计算任务之间有很复杂的数据依赖。对于共置式框架,一次只进行一个任务,数据只需要保存在主控进程里就可以。但对于分离式框架,多个计算任务并行执行,那么它们之间的数据管理就成了一个难题。如果还是像往常一样,对整个Global Batch数据进行操作,那么部署在不同设备上的计算任务之间就会有很长时间的等待,造成计算资源闲置,从而严重影响系统吞吐。因此,我们需要细化数据管理的粒度,按照Micro-Batch甚至Sample粒度来管理数据。
另外,各个计算任务之间的数据依赖具有动态性。强化学习中的Response是动态生成的,我们很难在一开始就精确预测每个Sample的Token总量。因此,如果我们在训练开始的时候按照Sample数在各路DP之间切分数据,会造成负载不均,影响训练效率。以OpenRLHF为例,其在训练开始时就分配好各个计算任务之间每组DP的数据依赖关系,每组数据依赖链路内按照Sample平分训练Prompt,数据链路之间无法动态分摊样本,如果出现快慢卡或长尾样本,则各个链路之间就会相互等待,降低吞吐。因此,我们需要动态灵活的数据路由机制,让计算任务之间实现“能者多劳,按劳分配”。
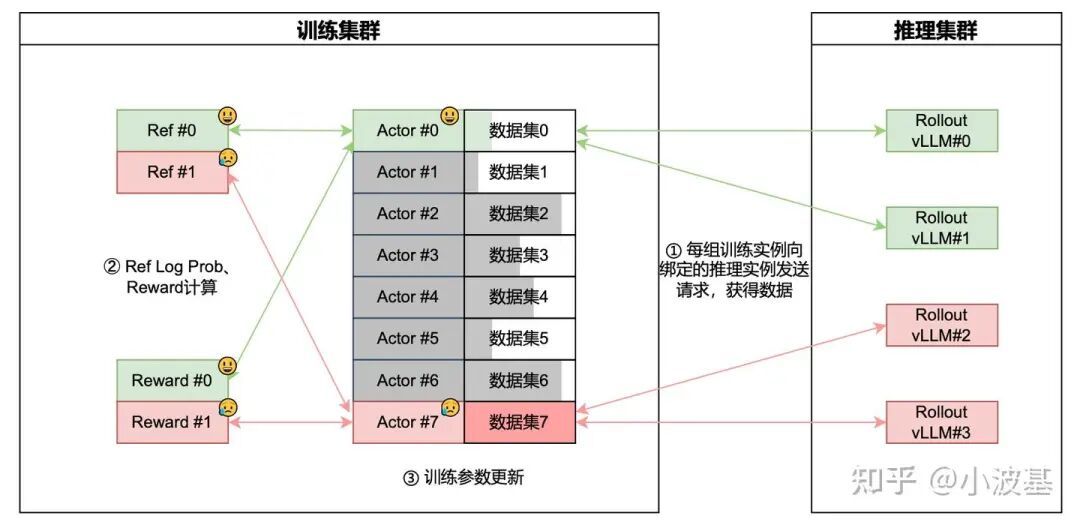
分离式框架中的另一个问题是RL算法带来的。传统的On-Policy算法要求训练和推理采用相同版本的模型,那么在分离式架构下,推理生成一个Global Batch的数据后就只能干等训练任务完成,并把新的模型参数加载好之后才能进行下一个Global Batch的推理,从而在Iteration之间造成大量空泡。
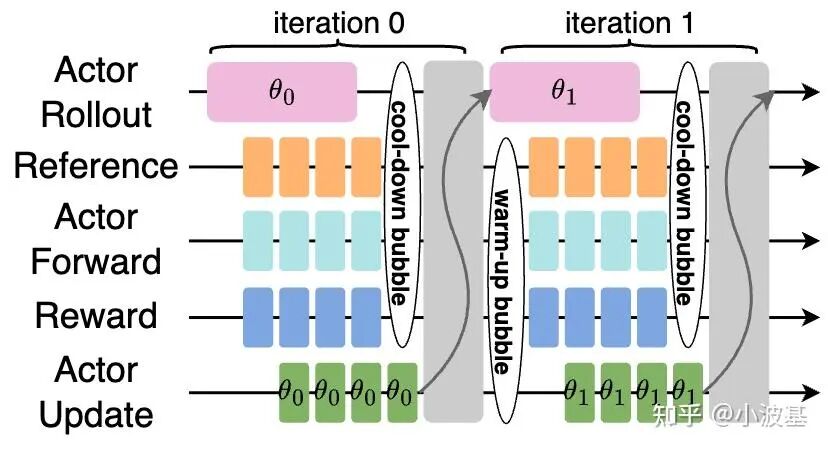
时势造英雄,随着后训练规模的扩大,共置式架构的缺点愈发明显,大家不得不啃下这两块硬骨头。好在,这两个问题都是有解的!我们会在后面的章节中逐一介绍。
03 分离式架构中的数据系统设计
数据系统的设计在很大程度上决定了计算系统。根据前文所挖掘出的系统挑战,我们提出了一个具有全景视角、流式调度能力的数据系统TransferQueue来实现后训练系统中数据的高效流转。
既然后训练里数据依赖关系那么复杂,我们就不妨设计一个数据的“转运港口“,管理整个系统中的数据流动。数据的上游生产者将处理好的数据”装箱“发送至TransferQueue,TransferQueue将这些数据“拆箱”并保存起来,并在下游消费者请求数据时,重新”打包“并发送过去,实现计算任务间数据的动态路由。
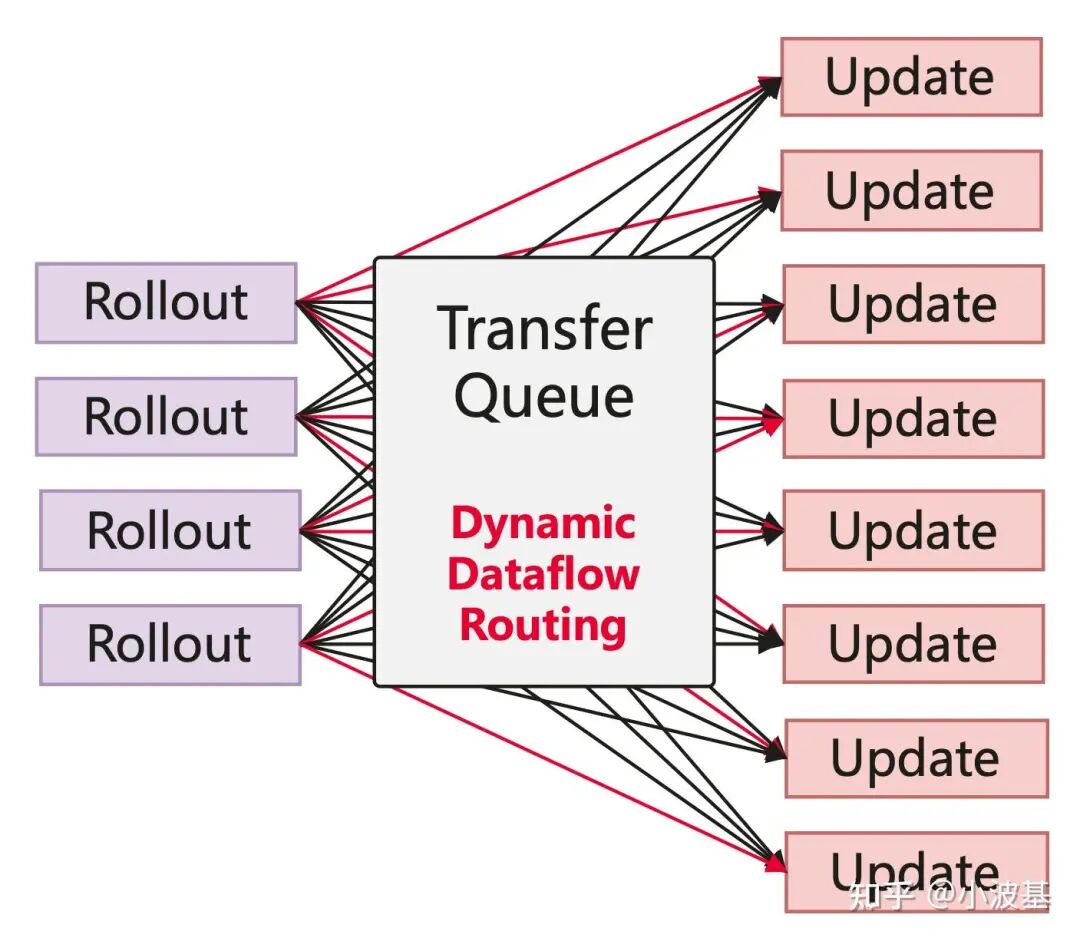
这样的设计有三个好处。首先,各个计算任务之间不再有显式的数据依赖关系。TransferQueue作为一个中心化的数据组件,把各个计算任务分离开,我们就不再需要手动编排各个计算任务之间的输入输出,也无需在时间轴上调优每个任务的开始和结束,在分离式架构下可以自动实现任务编排,可以轻易扩展至更多任务。其次,数据的调度粒度变得更精细。TransferQueue在“拆箱”与“装箱”的过程中,实现了Sample粒度的数据管理。只要系统里凑够了一个Micro Batch的数据,不管之前是由哪个生产者实例生成的,都可以及时调度给下游的消费者实例,实现了细粒度调度,有助于缓解快慢卡问题,减少了任务之间的等待。最后,TransferQueue具有整个Global Batch的全景视角,在上述重组调度过程中可以便捷地实现多种负载均衡算法,进一步增加系统吞吐。
1. TransferQueue架构设计
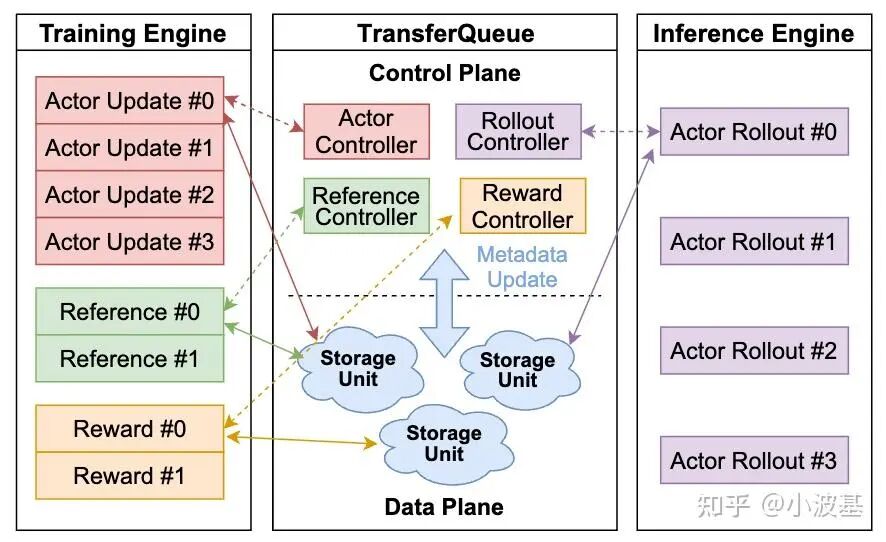
下图展示了TransferQueue的整体架构。我们将TransferQueue分为了控制平面与数据平面两个部分。控制平面用于管理训练数据的全局调度,而数据平面则以分布式的方式,存储真正的训练数据并进行高效传输。
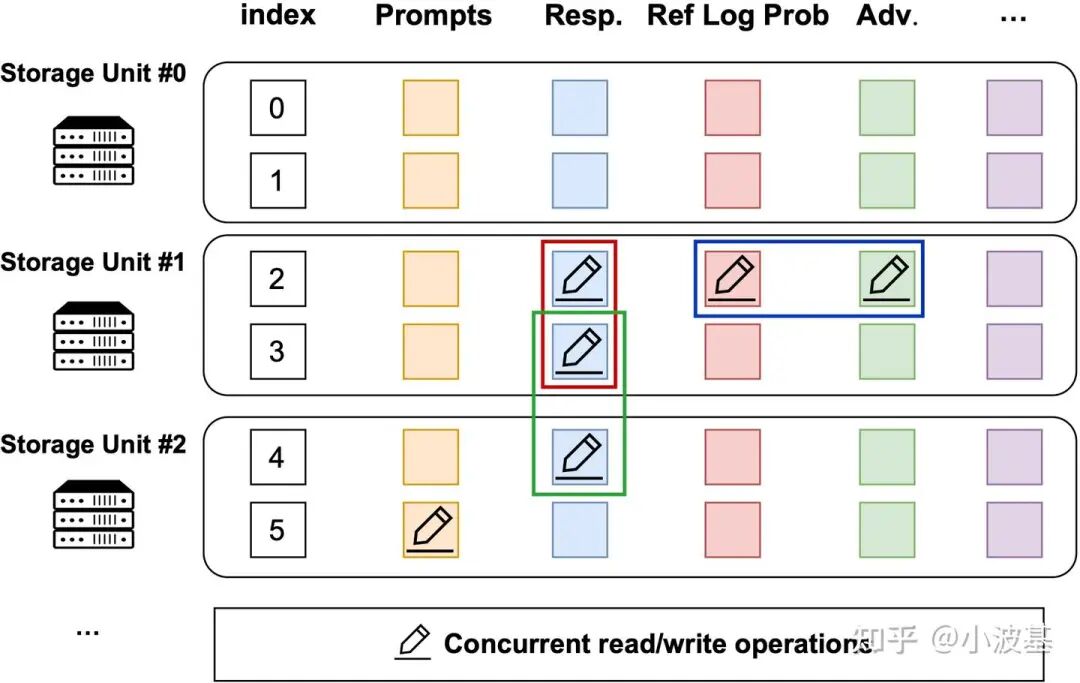
为了实现流式、细粒度的数据管理,TransferQueue采用了一种二维数据结构:
每行代表一个训练样本,并分配一个Index以表明其在对应Global Batch中的序号
每列代表对应RL任务的输入输出,如Prompts、Responses、Reference Log Prob等
这样的数据结构设计源自RL任务的计算特性,即每个训练样本是由各个计算任务接力生成的。通过这种方式,我们可以通过Index与列名精确寻址最细粒度的数据,实现数据的流式拆分,实现数据的高并发读写。
而在控制平面,我们通过一系列Metadata记录每条样本在各个阶段的生产消费情况。对于不同计算任务(如Actor Rollout、Reference Log Prob),我们初始化了不同控制节点实例,每个实例记录其所需的输入数据Metadata。如下图所示,Reference对应的Controller只需记录Prompt、Response的生产情况,而Actor Update则需额外记录更多内容。
当上游计算任务完成并将相应数据写入到TransferQueue之后,Controller所记录的Metadata将会更新。当一行数据里每一列的Metadata都为✅后,该条数据即可被对应的任务消费。同时,Controller还将根据自身记录的历史数据消费情况,避免数据被多个DP重复读取。
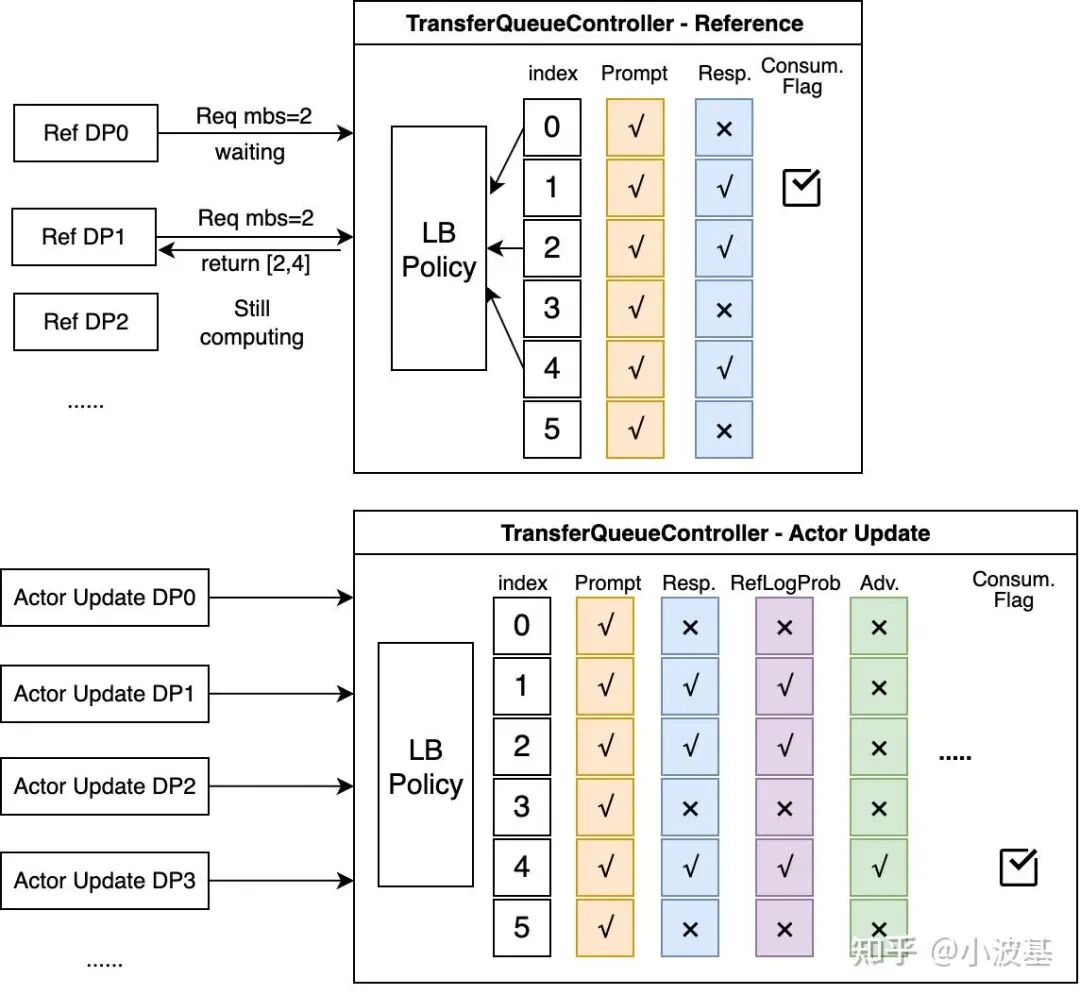
以数据读取过程为例,我们介绍TransferQueue系统的交互流程:
1. 某路DP完成计算任务,向这个任务对应的TransferQueue Controller发起数据读取请求;
2. TransferQueue Controller扫描自身所存储的生产消费状态,筛选出可被这次数据读取请求消费的样本(行),并且基于负载均衡策略,动态组织成一个Micro-Batch,将对应的Metadata返回给数据消费者;
3. 数据消费者根据Metadata,向分布式存储平面发起数据读取请求,获取实际数据。
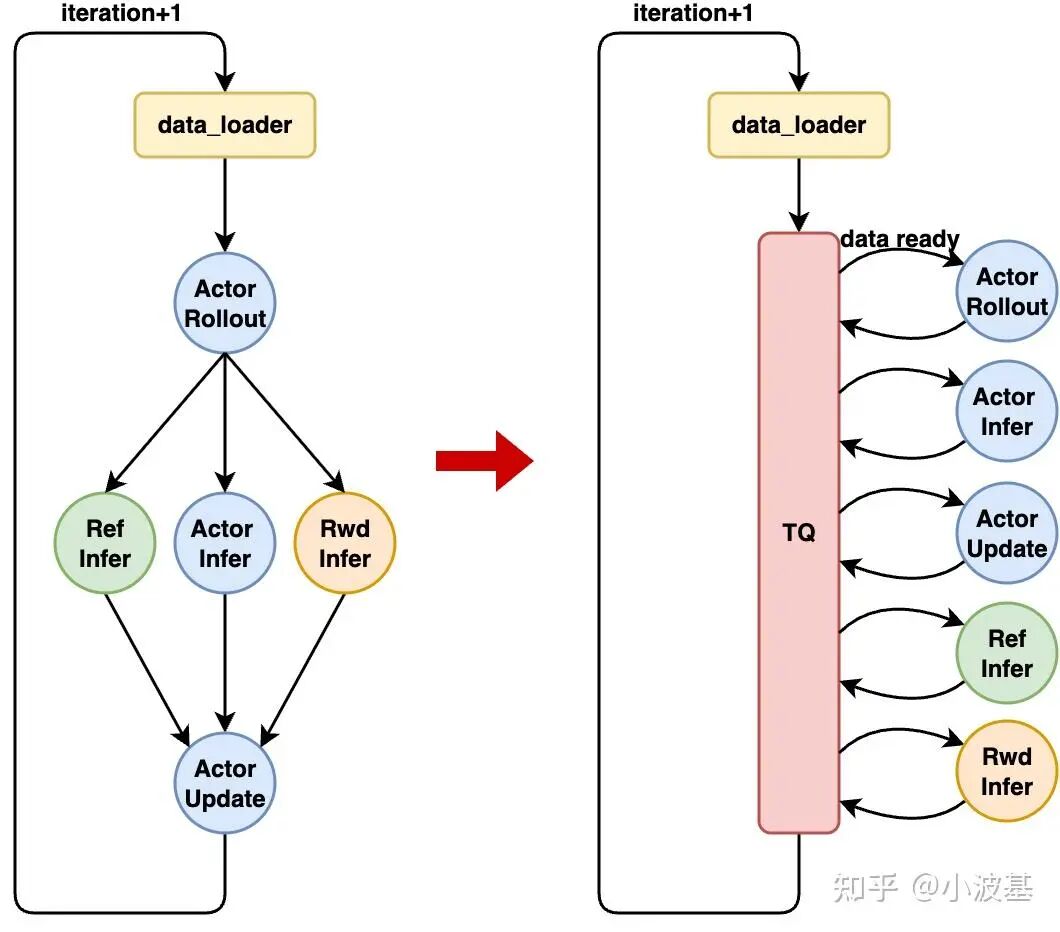
2. 算法主控流程简化
上述模块设计很好地将计算任务之间的数据依赖隔离开,从而大大简化了RL算法主控流程的设计。基于TransferQueue这类集中式数据管理组件,算法主控可以采用一种Dataflow范式:
1. 异步启动各个RL计算任务,这些任务将根据自身的计算情况决定是否从TransferQueue中读取数据;
2. 将第一个Global Batch数据(Prompts)送入TransferQueue系统;
3. 各个RL任务从TransferQueue中成功获取其所需的输入数据并开始计算;各个任务之间的数据依赖被TransferQueue自动处理,无需手动编排各个计算任务;
4. 算法主控检测到当前Global Batch已全部训练结束,记录Metric、逐出TransferQueue中的旧数据并将新Prompts放入系统,开启下一个Iteration。
class RayGRPOTrainer():
def fit(self,data_iters):
iteration=0
# 1. Start all the RL tasks. Each task tries to pull data from TransferQueue by themselves.
# generate sequences
self.rollout_worker.start(iteration,self.train_iters)
# compute reference log_prob
self.ref_worker.start(iteration,self.train_iters)
# compute rm scores.
rule_reward=[]
for reward_workerinself.reward_list:
if isinstance(reward_worker,RayActorGroup):
reward_worker.start(iteration,self.train_iters)
else:
rule_reward.append(reward_worker.start.remote(iteration,self.train_iters))
# compute advantage
for advantage in self.advantage_list:
advantage.start.remote(iteration,self.train_iters)
# compute old log_prob
if self.actor_fwd_worker:
self.actor_fwd_worker.start(iteration,self.train_iters)
# update actor
self.actor_worker.start(iteration,self.train_iters)
# 2. Put the first global batch of prompts into TransferQueue
start_iter_time=time.time()
for_in range(self.staleness_threshold):
batch=next(data_iters)
put_prompts(batch,self.n_samples_per_prompt,total_data_rows)
# 3. Iteration control
while True:
train_iteration=self.iteration_record.get()# iteration_record can be a Queue
# Do metric update
...
# Clear the corresponding TransferQueue
self.clear_tq_controllers(train_iteration,indexes)
# Put new prompts into TransferQueue
if data_loader_index<self.train_iters:
batch=next(data_iters)
put_prompts(self.metrics_tq,batch,self.n_samples_per_prompt,self.dataset_additional_keys,indexes[0])
data_loader_index+=1
iteration+=1
# Stop training
if iteration>=self.train_iters:
logger.info(f"The threshold of train iteration:{self.train_iters} is reached, stop putting prompt to TQ")
ray.shutdown()
break流式数据调度这一思路其实在StreamRL、AReal中也可以看到一些端倪,不过这些工作往往只停留在推理产生的数据基于流式方法传输至训练集群,并没有进一步扩展至训练集群内的各个计算任务上,因此无法像TransferQueue一样做到一个完全基于Dataflow的算法主控。
3. 交互逻辑
为了便于编程使用,我们当前在TransferQueue系统上进行了一层易用性封装,将其抽象为一个Pytorch Dataloader,从而可以将其作为一个迭代器使用,而无需感知其内部的实现逻辑。
以Actor Rollout为例,我们只需定义好自身的计算任务与所需数据,并基于此创建一个StreamDataLoader,将其作为迭代器使用即可从TransferQueue中获取其所需的数据。
而对于训练任务,这一DataLoader可以直接送至Megatron后端中的forward_backward_func中,实现与现有训推后端的无缝结合。
class RolloutWorker(BaseWorker):
def generate_sequences(self):
experience_consumer = 'actor_rollout'
experience_columns = ['prompts', 'prompt_length']
experience_count = self.rl_config.rollout_dispatch_size # can be set to MBS
data_loader = self.create_stream_data_loader(
experience_consumer=experience_consumer,
experience_columns=experience_columns,
experience_count=experience_count,
order_preserving_flag=self.rl_config.guarantee_order
)
data_iter = iter(data_loader)
for batch_data, index in data_iter:
indexes = list(range(0, experience_count, self.rl_config.n_samples_per_prompt))
prompts_data = batch_data['prompts'][indexes]
# Do Inference
responses = self.rollout.generate_sequences(prompts_data)[0]
# Prepare Output
input_ids_list = []
for prompt, response in zip(prompts_data, responses):
input_ids_list.append(torch.cat((prompt, response), dim=0))
outputs = {
'responses': responses,
'input_ids': input_ids_list,
}
# write results back to TransferQueue
self.collect_transfer_queue_data(outputs, index)
class BaseWorker:
def collect_transfer_queue_data(self, output, index):
if is_pipeline_last_stage(self.parallel_state) and get_tensor_model_parallel_rank(self.parallel_state) == 0:
output = {key: value.cpu() if not isinstance(value, List) else value for key, value in output.items()}
# Write results back to TransferQueue. This is a utility function that encapsulates
# the logic of putting data into the TransferQueue. In the future, we may propose a dedicated
# client interface for this.
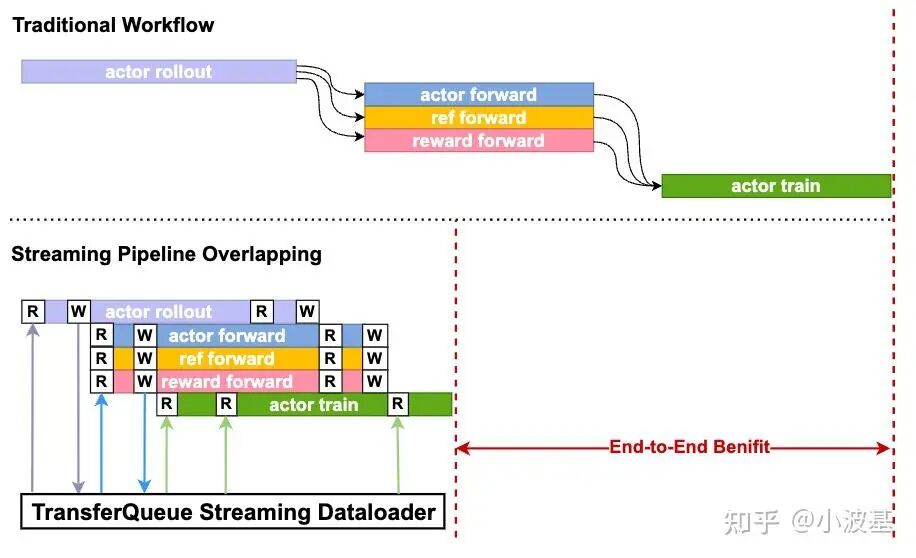
put_experience(self.tq_controller, data_dict=output, indexes=index)基于TransferQueue提供的细粒度数据调度能力与自动流水编排能力,我们可以实现如下图所示的效果,将每个Global Batch中的流水空泡降低至几个Micro Batch的水平。当然这里没有提到的一点是还需要对训练引擎进行一些小改动,让它能实现Micro Batch的计算。这属于分离式架构后训练所引发的对训练引擎的新需求,相信后面很快就有PR跟上了。
4. TransferQueue内部实现一瞥
当前TransferQueue的实现基于Ray这一框架。Ray的编程框架好写是好写,但性能调优实在是个大坑(省去1w字吐槽)。现在我们正在进行重构,因此这里的实现仅作为参考。
首先我们来看数据写入过程。put_experience函数包装了前面所说的三个过程:
1. 将Batch数据拆分为Sample粒度;
2. 向该任务对应的Controller发送请求,获取Metadata;
3. 根据Metadata,将实际数据写入到底层分布式存储引擎中。
def put_experience(controller_handler: ray.actor.ActorHandle,
data_dict: Dict[str, Union[Tensor, List[Tensor]]],
indexes: List[int]) -> None:
# split the batch block into samples
experience_columns, experience = trans_input_into_experience(data_dict)
# get metadata from TransferQueue controller
metadata_list = ray.get(controller_handler.get_metadata_on_writing.remote(indexes))
if metadata_list is None:
logger.warning("put experience return None.")
return
# write actural data into distributed storage node
experience_data = transfer_to_tensor_dict(experience_columns, experience)
# for simplicity, we use ray to conduct data transfer. In the future, we will
# integrate with a more efficient data transfer mechanism and supports more
# data storage backends.
ray.get([metadata.handler.put_data.remote(
experience_data, metadata.experience_offset, metadata.indexes)
for metadata in metadata_list])而在Controller中,我们提供了一个负载均衡接口,在读请求到来时可以根据所指定的负载均衡策略来提高训练效率。例如,verl中就实现了一个DP负载均衡,通过平衡每路DP上所拿到的Token总数来避免相互等待。
class TransferQueueController:
def get_metadata_on_reading(self, consumer: str, experience_count: int, policy='DP_balance'):
meta_data = self.sample_batch_metadata(consumer, experience_count, policy)
return meta_data
def sample_batch_metadata(self, consumer, experience_count, policy):
# 1. scan all the samples that are ready to be consumed
ready_index = self.get_ready_sample_index()
# 2. use load balance sampler to sample a batch of metadata
batch_meta = self.load_balance_sampler(ready_index, consumer, experience_count, policy)
return batch_meta为了适应未来更加复杂的后训练数据,我们期望将TransferQueue的读写语义向通用存储靠拢,通过简单通用的put/get抽象来减少定制化操作。未来TransferQueue将会包含以下三个抽象:
TransferQueueClient:部署在每个Worker进程上,管理与TransferQueue系统的通信过程。Client后续会支持多种通信库(如ZMQ、TransferEngine等)来适应文本、多模态等不同场景;
TransferQueueController:一个集中式的流式数据调度模块,管理后训练过程中每条数据的生产消费情况来实现数据的灵活调度与路由(与当前设计相同);
TransferQueueStorage:一个通用的存储抽象层,将通用的put/get语义翻译为各个存储后端的具体实现,从而支持如Redis、MoonCake等不同存储后端的接入。
04 算法编排
1. 由On-Policy迈向Off-Policy
传统的On-Policy算法要求训练、推理模型基于完全相同的一套参数。在共置式(Task-Collocated)框架中,这一要求并不会带来严重的资源浪费。因为一个iteration的样本推理结束后,马上要将推理模型释放掉再切换至后续其他RL任务。
而对于分离式框架,这将会导致推理任务所在的计算实例在完成当前iteration后只能白白等待,从而在iteration之间造成大量空泡。
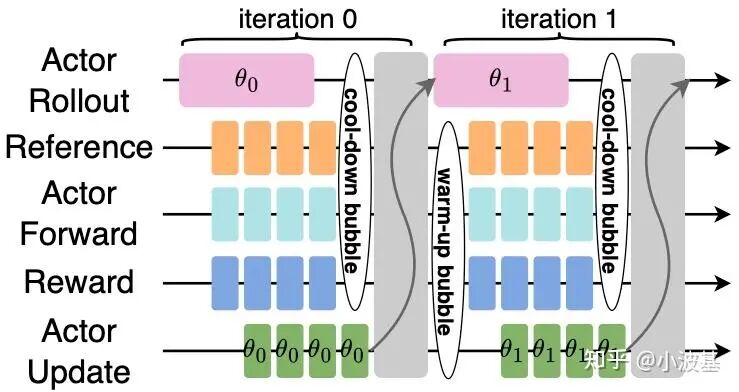
近年来,越来越多的研究者从实践角度发现,大模型强化学习训练中并不一定需要严格保证这一约束。Kimi在k1.5中引入了Partial Rollout技术,将超长Response进行截断,并混入后续iteration来提高推理阶段的吞吐。这导致长尾样本实际是由不同版本的模型所产生的,从而突破了On-Policy算法的限制。AReaL在此基础上还提出了Decoupled PPO Objective,从算法上修正了训推模型参数不同导致的收敛性问题。类似地,Seed1.5-Thinking中也提到了Streaming Rollout System的概念,通过调控训练数据中On-Policy和Off-Policy样本的比例来平衡模型收敛性与系统吞吐。

此外,ICLR25的一篇文章和来自阶跃星辰的StreamRL进一步验证了“一步异步”的RL算法一般不会对模型的收敛性有显著影响,为解决分离式架构的流水空泡指明了方向。
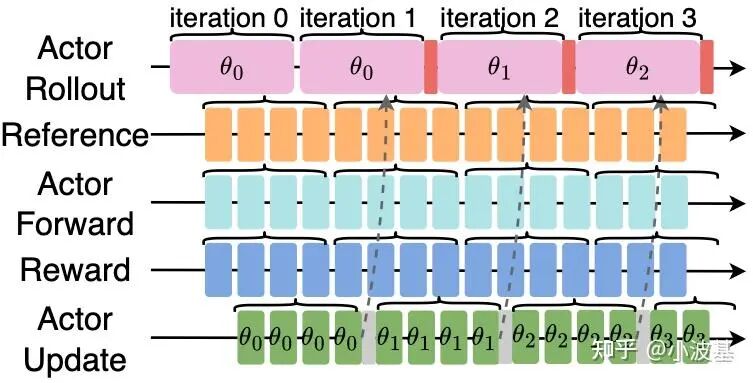
2. 参数延迟更新的一步异步Off-Policy算法
所谓“一步异步”,指的是训练和推理模型最多只差一个版本。更准确地说,是训练最新模型时的输入数据,是由上一个版本的推理模型所产生的。
实现这样的异步,最简单的方式就是调整Batch Size。通过令推理阶段的Global Batch为训练的 K 倍,即可实现 K-1 步的Off-Policy算法。然而由于算法收敛性的限制,我们不能无限增大 K ,从而导致空泡占比无法进一步缩小。
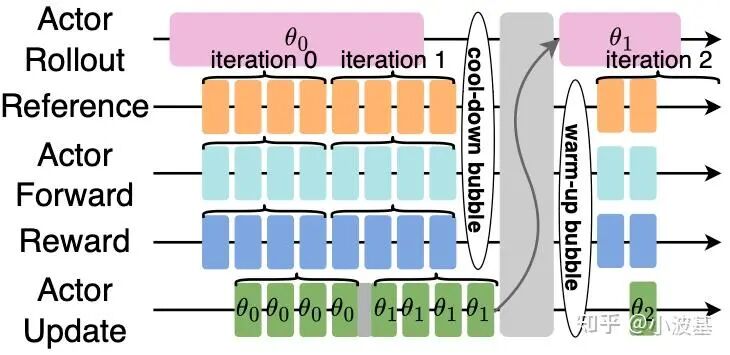
聪明的你一定想到了,我们可以让训练与推理始终只差一步,这样就可以无限地将稳态流水线延长下去,从而令空泡占比持续缩小。与AReaL不同的是,我们在这里并未选择在权重更新时令推理中断,而是实现了一套异步参数传输过程。
具体地,当训练集群进行参数更新后,会异步向推理集群发送最新版本的模型参数;此时推理正常进行,并将最新的模型参数暂存在CPU侧内存中(并做好相关Resharding准备)。当整个Global Batch推理任务结束后,触发一次H2D操作,将新模型加载至显卡上。相比于网络传输的带宽,机内H2D带宽往往更高。通过这种方式,可以有效将训推参数同步的开销进行掩盖,发挥分离式架构的优势。如果大家感兴趣的话,后面我们会再结合具体的实现展开介绍。
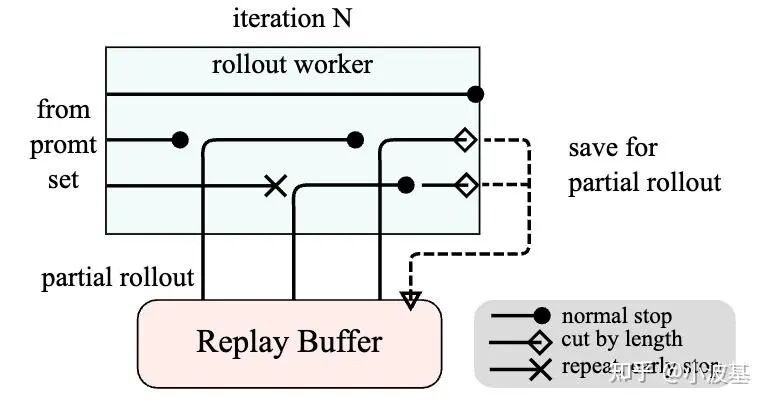
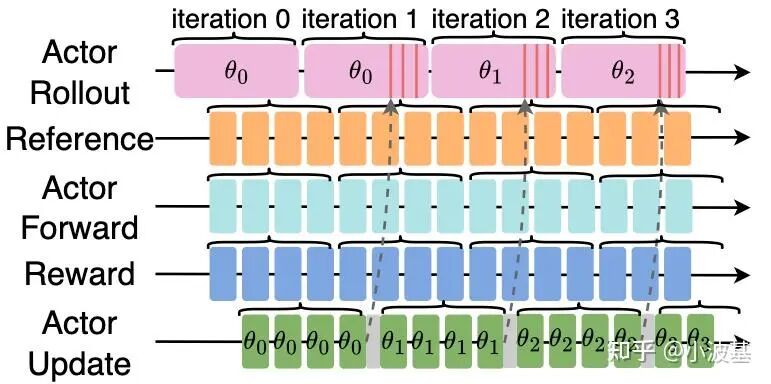
3. One More Thing:如何实现“半步异步”的Off-Policy算法?
“一步异步”看似已经把Off-Policy对收敛性的影响降到最低了,但事实真的如此吗?
在前面我们提到,训练产生的最新模型参数将异步传输至CPU侧内存,并等待推理任务完全结束后再进行参数加载。而在实际训练中,为了保证流水线正常运转,需要满足推理总吞吐≥训练总吞吐。这就意味着,我们有机会让一小部分推理实例轮流更新最新权重,而让其他推理实例基于旧权重继续推理,维持训练流水不中断。
这样做会带来两个好处。首先,这时一个训练的Global Batch中的样本,一部分是最新模型权重产生的,另一部分是由上个版本的旧权重产生的。相比于一步异步算法中整个Global Batch都是由旧权重产生,这种“半步异步”算法有助于降低Off-Policy对模型收敛性的影响,提高模型的效果。其次,由于不同推理实例的参数更新时机不同,参数加载的H2D时间也可以被掩盖,从而提高训练效率。受限于时间精力,我们暂时还没有实现这个策略,只是先画了一个大饼,期待和大家进一步讨论~
4. 流水掩盖效果
通过结合流式数据架构与一步异步的RL算法编排,我们最终实现了不错的掩盖效果。我们用GRPO算法在512卡集群上训练Qwen2.5-32B模型,并把前3个iteration的时序图展示如下。可以看出,各个计算任务之间实现了很好的掩盖,随着iteration的增加,最终暴露在外的流水空泡将收敛至整个训练开始时的Warm Up和训练结束的Cool Down阶段,很好地解决了分离式架构下的资源闲置问题。
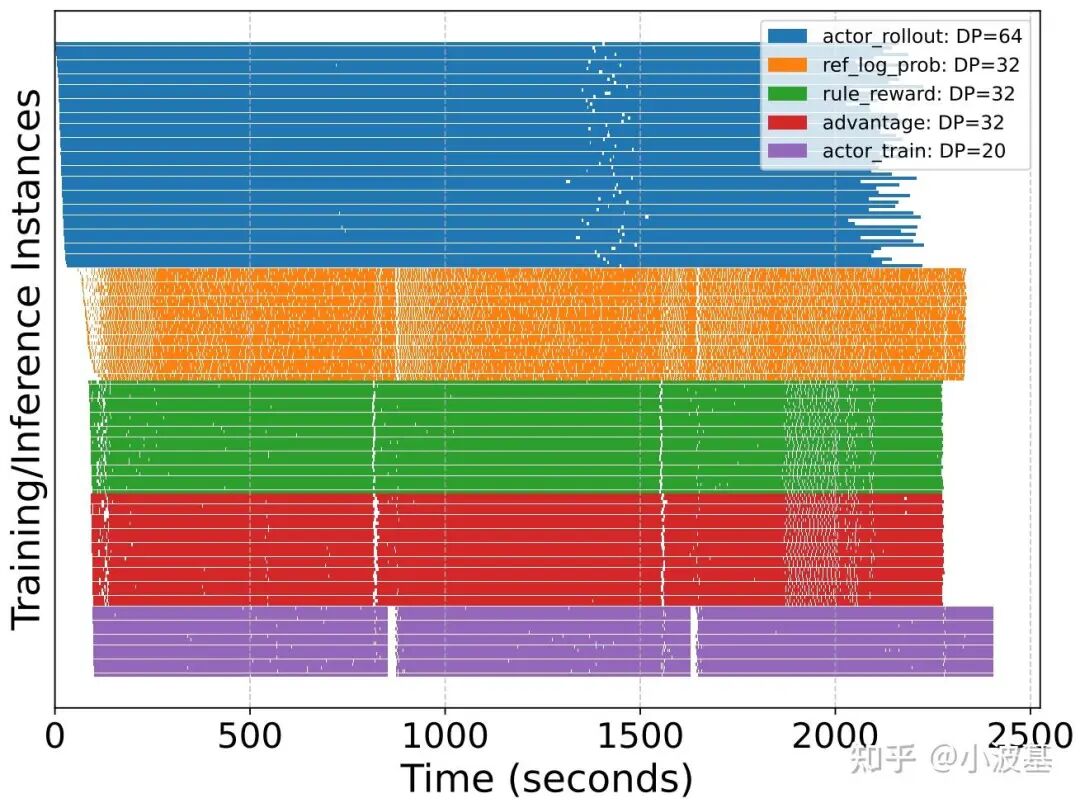
这里我们测试的序列长度相对较需要注意的是短。随着训练的进行,Response的平均长度将显著提高,长尾样本可能会导致掩盖效果的下降。所以,像Partial Rollout这类技术还是有很大空间的——毕竟都已经Off-Policy了,截断一部分Response放在后续推理也就没那么难以接受了。
另外,分离式架构下的资源配比是个大难题。我们需要配置每个RL任务的资源,来提高整个系统的吞吐,这实际上产生了一个组合优化问题。此外,传统的仿真建模只能得到单一任务的完成时间,分离式架构下的各种掩盖策略大大增加了精准仿真的难度,从而让这个问题变得更加难解。所以,我们在实践过程中结合了仿真建模和手工调优,整理出了一个通过Log打点绘制上述时序图的小工具来人工优化这个问题。
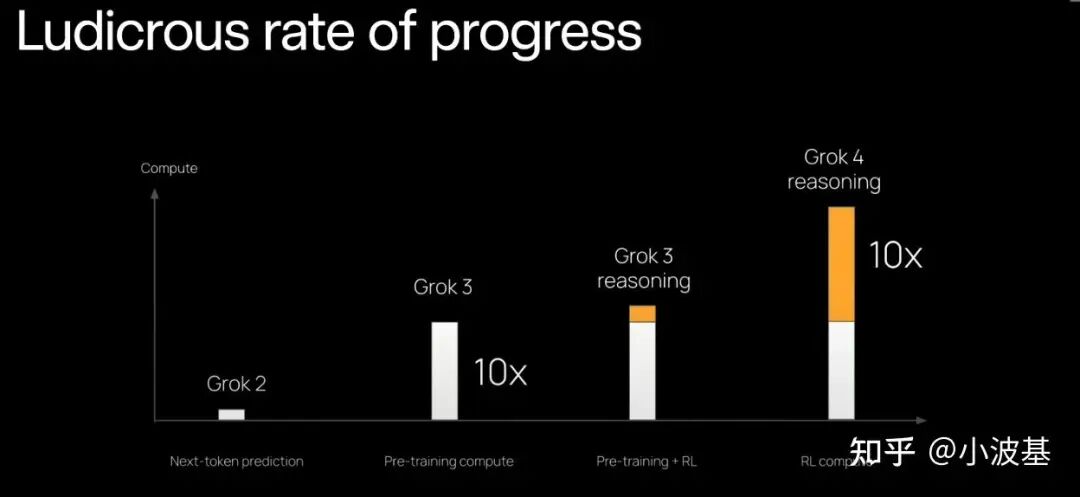
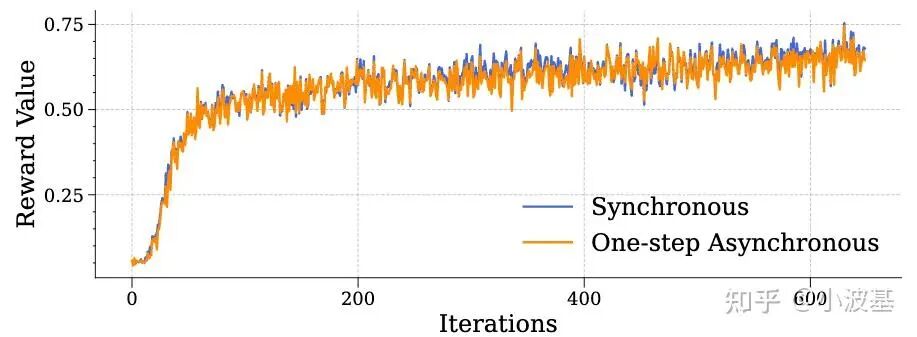
5. 收敛性评估
我们最后也对一步异步算法的收敛性进行了验证。整体测试下来,Acc Reward与On-Policy场景没有显著的区别,而Response Length最终收敛的结果也比较相似。