绑定手机号
确认绑定









作者:赵晨阳,SGLang RL Lead
地址:https://zhuanlan.zhihu.com/p/1999403679393014924
经授权发布,如需转载请联系原作者
TL;DR
受 Kimi K2 团队启发,SGLang RL 团队成功落地了 INT4 量化感知训练(QAT) 流程方案。通过“训练端伪量化 + 推理端真实量化(W4A16)”的方案组合,我们实现了媲美 BF16 全精度训练的稳定性与训推一致性,同时 INT4 极致压缩也将 1TB 级超大模型的采样任务容纳于单机 H200 (141G) 显存内,消除了跨机通信瓶颈,显著提高了 Rollout 效率,为社区提供了兼顾高性能与低成本的开源参考。
https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/rlhf/slime/int4/readme.md
近期,SGLang RL 团队在强化学习的训练稳定性,训练效率与适用场景方面取得了重要进展,具体包括:
INT4 QAT 全流程训练:我们实现了从训练到推理的完整 QAT INT4 闭环的方案,并提供了详细的技术方案,显著提升了 Rollout 的效率与稳定性。
Unified multi-turn VLM/LLM 多轮采样范式:我们提供了 VLM 多轮采样范式的实现 blog,开发者只需编写一套定制化的 rollout 函数,即可像训练 LLM 一样,轻松开启 VLM 的多轮强化学习。
Rollout Router Replay:我们实现了 Rollout Router Replay 机制,显著提升了 MoE 模型在 RL 训练过程中的稳定性。
FP8 全流程训练:我们在 RL 场景中成功实现了 全流程 FP8 训练与采样,进一步释放了硬件性能。
投机采样:我们在 RL 场景中成功实践了 投机采样,实现了大规模训练的无损加速。
在此基础上,我们更进一步,在 slime 框架上成功复现并落地了 INT4 量化感知训练(QAT) 全流程方案。该方案深受 Kimi 团队 K2-Thinking 技术报告中关于 W4A16 QAT (Quantization-Aware Training) 实践的启发。为了致敬先行者并回馈社区,本文将详细剖析我们在开源生态中打通全流程的技术细节,旨在为社区提供一份兼顾稳定性与性能的可落地参考。
核心收益概览:
突破显存瓶颈:通过权重压缩与低比特量化,使 1TB 级别的 K2 类模型能缩容至单机 H200 (141G) 显存内,避免了跨机通信瓶颈。
训推一致:训练端利用 QAT 确保权重符合 INT4 分布,推理端执行 W4A16 (Weights INT4, activations BF16 ) 计算;二者均通过 BF16 Tensor Core 进行运算,实现了媲美 BF16 全精度的训推一致性。
单机效率倍增:在超大模型场景下,INT4 策略大幅降低了显存与带宽压力,Rollout 效率显著超越 W8A8 (Weights FP8 , Activations FP8)。
本项目由 SGLang RL 团队、 InfiXAI 团队、蚂蚁集团 Asystem & 阿福 Infra 团队,slime 团队与 RadixArk 团队联合完成。相关功能与 recipe 已经同步到了 slime 与 Miles 社区,欢迎大家试用与贡献。我们也在更进一步向 MXFP8 与 NVFP4 发起挑战。同时,由衷感谢 Verda Cloud 为本工作提供的计算资源。
01 技术方案概览
1. 总体流程
我们实现了从训练到推理的完整 QAT INT4 闭环的方案,如下图所示:
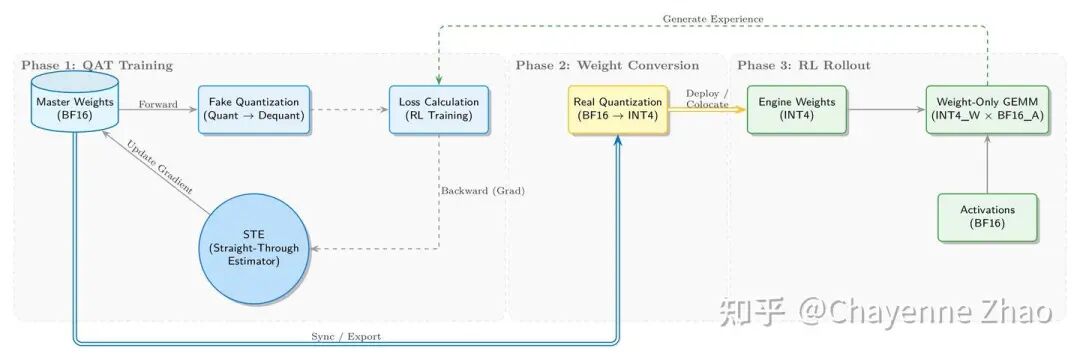
在 QAT 训练阶段,训练侧在维护 BF16 主权重(Master Weights)的基础上,前向传播通过伪量化(Fake Quantization) 引入量化噪声。所谓 “伪”,是指该步骤并未真正将 BF16 数据类型转换为低精度的 INT4,而是保持浮点计算路径不变,通过插入 量化再反量化(Quant-Dequant) 操作来模拟低精度的计算。具体而言,高精度权重在经过“离散化映射到INT4”后被立即还原,虽然其物理存储格式仍为浮点,但数值精度已实质性降低。这种原值与还原值之间的差异引入了量化误差,在数学上等效于向网络注入了噪声,迫使模型在训练阶段就通过梯度更新去适应这种精度损失。
反向传播则利用 STE (Straight-Through Estimator) 技术跳过了量化算子的不可导特性。量化过程的核心操作是“取整(Rounding)”,其数学形态为阶梯函数,导数在几乎所有位置均为 0。这意味着在标准反向传播过程中,梯度信号传导至此处会因“梯度消失”而彻底中断,导致底层的主权重无法获得更新。对此,STE 采用了 “梯度透传” 策略:在反向传播计算时,将取整函数的导数定义为 1(即视为恒等映射)。这一机制相当于在不可导的“断崖”上架设了一座桥梁,让梯度能够越过取整层,有效回传至高精度的浮点权重,确保 QAT 训练链路的闭环。
在权重转换阶段,我们将训练收敛的 BF16 权重导出并执行真实量化(Real Quantization),将其转换为推理引擎适配的 INT4 格式(如 Marlin)。
进入 RL Rollout 阶段,由 SGLang 加载 INT4 Weights 并执行高效的 W4A16(INT4 权重 x BF16 激活)推理,生成的经验数据(Experience)将回流至第一阶段用于下一轮 RL 训练,从而构成一个自洽的迭代闭环。
2. 核心策略选择
在量化格式上,我们参考 Kimi-K2-Thinking 选用了 INT4 (W4A16) 方案。这主要考虑到相比 FP4,INT4 在现有硬件(Pre-Blackwell 架构)上的支持更加广泛,并且业界已有成熟高效的 Marlin Kernel 实现。实验表明,在 1×32 量化 Scale 粒度下,INT4 动态范围充足、精度稳定,其性能与生态链路均已高度优化。作为工业界“足够好(Good Enough)”的量化标准,INT4 在性能、风险与维护成本间实现理性平衡。当然,我们后续也计划在 NVIDIA Blackwell 系列硬件上进一步展开 FP4 RL 的探索。
在训练方法方面,我们采用了 Fake Quantization 配合 STE 的经典组合。通过维护 BF16 主权重,在前向计算中模拟量化噪声,并在反向传播时直通梯度,这种方式最大程度地保证了低精度训练的收敛性与稳定性。
02 训练侧:Megatron-LM 的伪量化改造
1. Fake Quantization 与 STE 实现
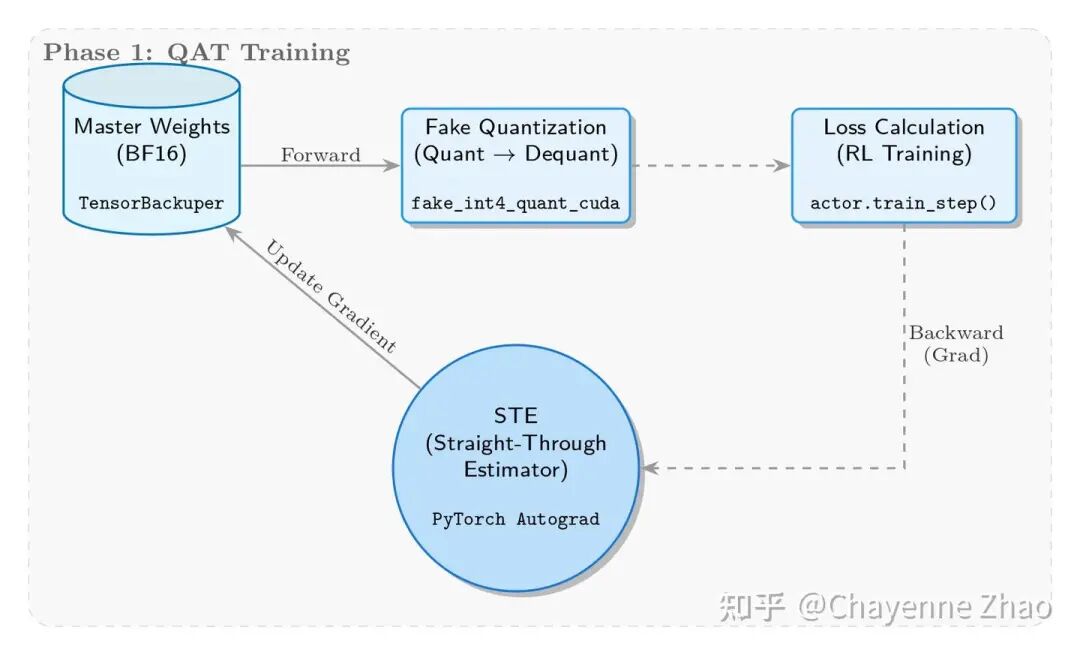
这一阶段的核心目标是在训练过程中实时模拟量化误差,迫使模型“学会”适应低精度表示。为此,我们采用了 Fake Quantization 机制:尽管权重在存储和更新时仍保持高精度的 BF16 格式,但在前向传播的实际计算中,会被暂时映射到 INT4 的精度范围参与运算。
具体实现上,我们在 megatron/core/extensions/transformer_engine.py 中的 _FakeInt4QuantizationSTE 类构建了核心逻辑。基于分组最大绝对值进行动态量化(Dynamic Quantization),模拟 INT4 的 [-7, 7] 数值范围及截断操作,但在计算时仍使用 BF16 类型,仅引入量化误差。而在关键的反向传播环节,我们引入了 STE 机制,确保梯度能够直接穿透量化层,不经修改地回传以更新主权重,从而保证训练的连续性。
2. Fake Quantization 对比实验
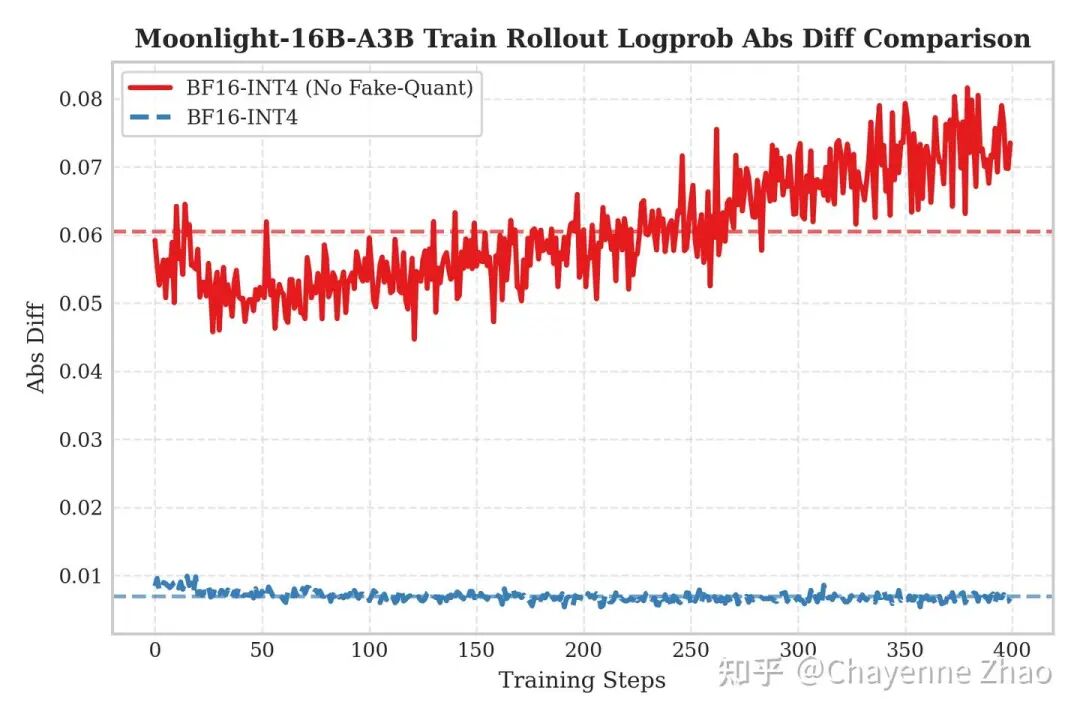
为了验证 QAT 方案的必要性,并探究训练与推理精度不匹配带来的具体影响,我们设计了一组消融实验,分别在“开启 QAT INT4 训练,BF16 Rollout”和“关闭 QAT 训练,直接进行 INT4 Rollout”两种非对称场景下进行了测试,并以对数概率绝对差值(Logprob Abs Diff)作为训推不一致的观测指标。
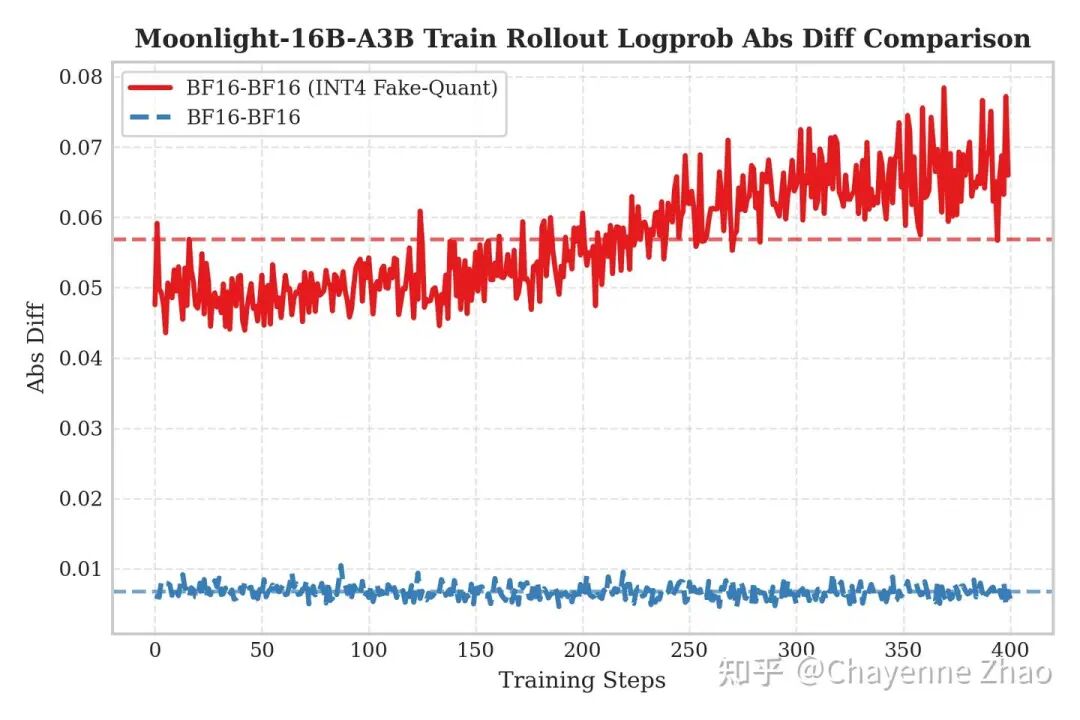
左图展示了“开启 QAT INT4 训练,BF16 Rollout”的场景(即红线部分)。可以看到,即使我们使用了高精度的 BF16 进行推理,误差依然显著偏高。这是因为在 QAT 过程中,模型权重已经针对 INT4 的量化噪声进行了“适应性调整”或补偿;推理时若移除量化步骤,这种补偿反而成为扰动,导致特性分布偏移(Distribution Shift)。
右图则展示了“关闭 QAT 训练,直接进行 INT4 Rollout”的场景(即红线部分)。这对应了传统的训练后量化(PTQ)模式。由于模型在训练阶段从未接触过量化噪声,直接将权重压缩至 INT4 不仅造成信息的剧烈丢失,更导致推理时的特征分布与训练时产生偏移,致使误差随着训练步数呈现震荡上升的趋势。
结论:实验有力地证明,训练端的 Fake Quantization 与推理端的 Real Quantization 必须协同开启。只有当训练时的模拟噪声与推理时的真实量化精度严格对齐,才能有效抑制训推不一致,避免分布偏移,将误差控制在接近基线的水平,从而真正打通低精度 RL 训练的全流程。
03 权重更新阶段
1. 权重流转与动态格式适配
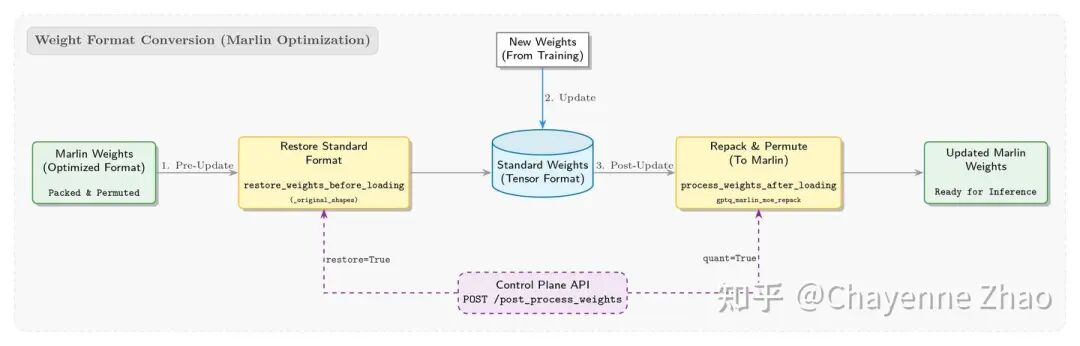
为了复用 SGLang 在推理端已有的优化,我们直接采用了其内置的 Marlin Kernel 作为 INT4 的推理方案。然而,这在工程落地时我们遇到了显著的“格式鸿沟”:QAT 训练产出的是类似 Hugging face 上的标准格式权重,而 SGLang 推理引擎的 Marlin Kernel 则强制要求权重必须经过特定的打包(Pack)与重排(Permute)处理,方能被 Kernel 高效读取。
面对 RL 训练中频繁的权重更新需求,首先需要解决格式兼容性问题。为此,我们设计了一套逆向的 restore_weights_before_loading 保护机制。该机制利用缓存的 _original_shapes 元数据,能够在权重更新动作发生前,强制将当前内存中的 Marlin 权重格式还原(Resize)回原始形状。这一设计有效防止了因维度不匹配导致的运行时错误,确保模型能够在标准权重格式与 Marlin 权重格式之间平滑切换。此外,我们还在系统层面新增了 post_process_weights API,允许控制平面根据训练节奏显式触发这一流程。
而针对权重加载完成后的格式适配挑战,我们在 compressed_tensors_moe.py 中实现了一套动态权重管理机制。在模型权重加载结束阶段,系统会自动触发 process_weights_after_loading 流程,底层调用 gptq_marlin_moe_repack 与 marlin_moe_permute_scales 等算子,在内存中即时将标准权重转换为高度优化的 Marlin 权重格式,从而最大化推理时的访存与计算效率。
2. 权重更新时的量化

进入核心的 Real Quantization 环节。不同于训练时的 Fake Quantization,这一步通过代码中的 int4_block_quantize 函数执行不可逆的精度压缩操作:基于设定的 Group Size,计算每组权重的缩放因子(Scale),并将高精度浮点数映射到 [-7, 7] 的 INT4 整数域。
为了最大化显存利用率,接着执行 位宽打包(Packing) 操作。由于 PyTorch 缺乏原生的 INT4 数据类型,我们通过 pack_int4_to_int32 函数利用位运算技巧,将 8 个 INT4 数值紧凑地“压缩”进1个 INT32 整数中(即 8 × 4 bits = 32 bits)。最终,这些经过压缩的 Packed Weights 连同 Scale 因子被传输至推理引擎,完成了从“训练格式”到“推理格式”的转换。
04 推理阶段
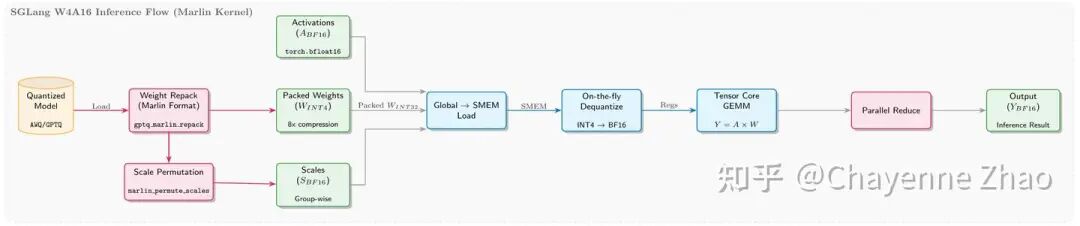
1. 极简打包与零开销解包
在 RL 训练的 Rollout 阶段,我们直接复用了 SGLang 优化成熟的 W4A16 量化方案。SGLang 使用紧凑的 INT4 格式,将两个 4-bit 权重打包进一个字节,相比 BF16 节省了 75% 的内存。在推理时,Triton kernel 通过高效的位移和掩码操作(>> 4 和 & 0xF)快速解包,得益于计算与 IO 的并行覆盖,该过程几乎实现了零额外延迟。
2. MoE 算子深度融合
显存优化:SGLang 引入动态的 moe_align_block_size,根据当前 Token 数量和 Expert 分布自动选择block_size,将同一 Expert 的 Token 聚集并对齐,提升显存带宽利用率。
计算融合:SGLang 引擎除集成了高效的 Marlin INT4 实现、还将 gating 部分 fuse 成一个高性能的 kernel,避免了反复启动 kernel 和读写中间结果。同时,该INT4推理方案兼容 GPTQ 和 AWQ 等主流量化格式,以及支持对称与非对称两种模式。
05 INT4 QAT RL 实验效果
1. 训练效果
训练侧
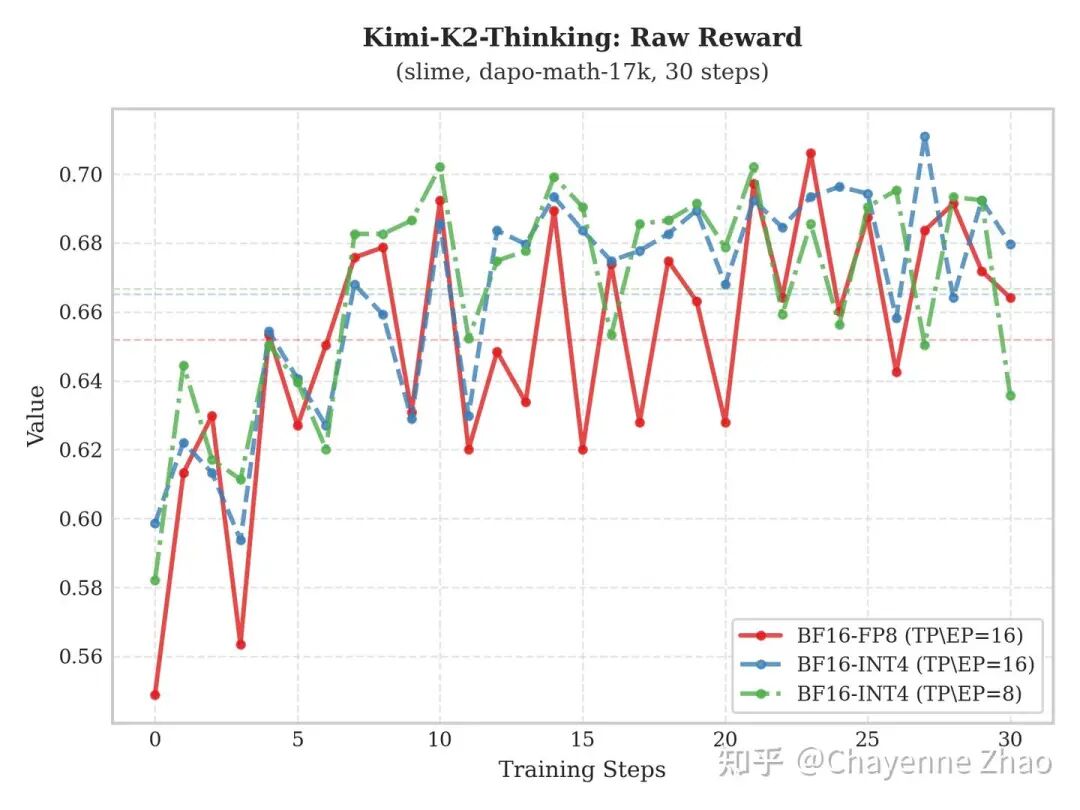
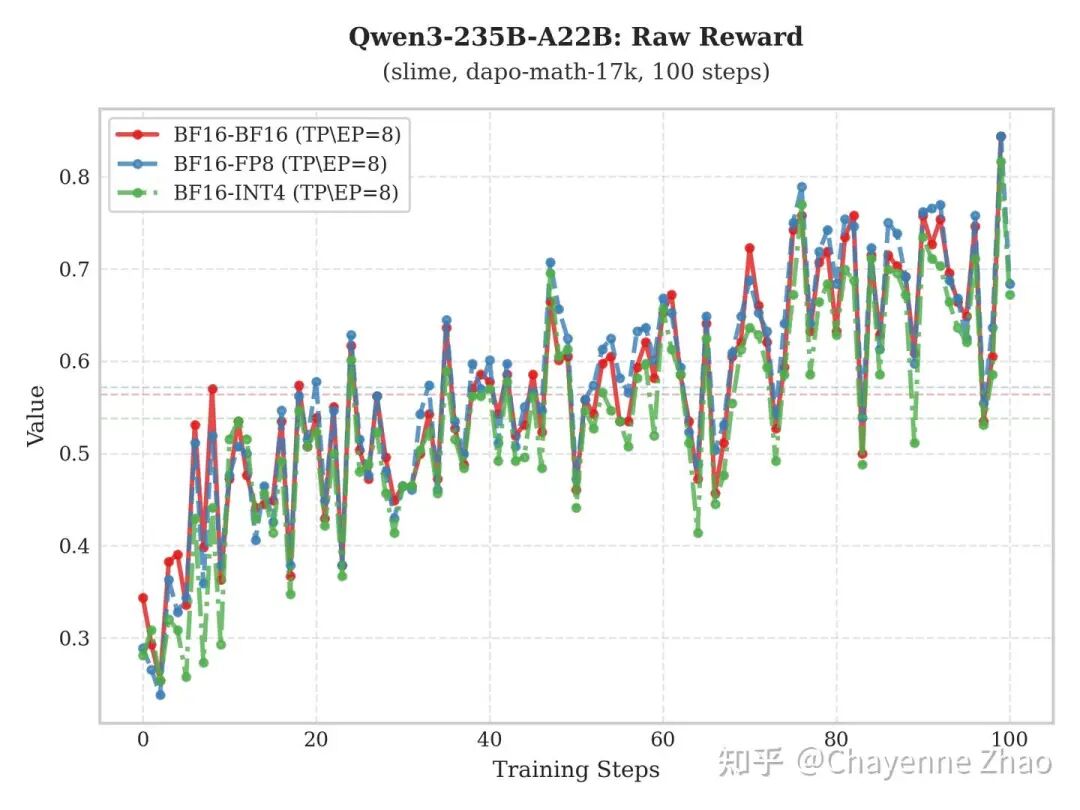
上图展示了基于 slime 框架,Qwen3-235B-A22B 与 Kimi-K2-Thinking 模型在 dapo-math-17k 数据集上的训练表现。通过对比实验发现,相较于 “BF16训-BF16推” 及 “BF16训-FP8推”,“BF16训-INT4推” 配置下的 Raw-Reward 仍能保持稳健增长,且其增长趋势与前两者基本一致,证明了该方案在训练过程中的有效性。
评估侧
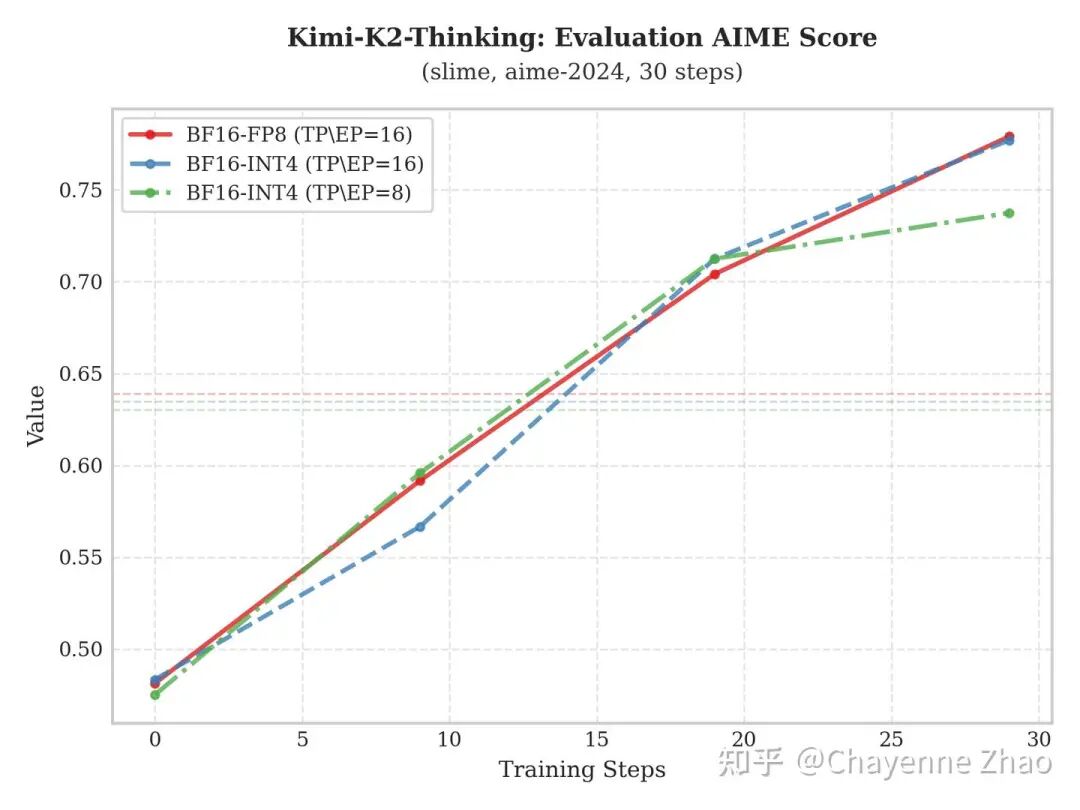
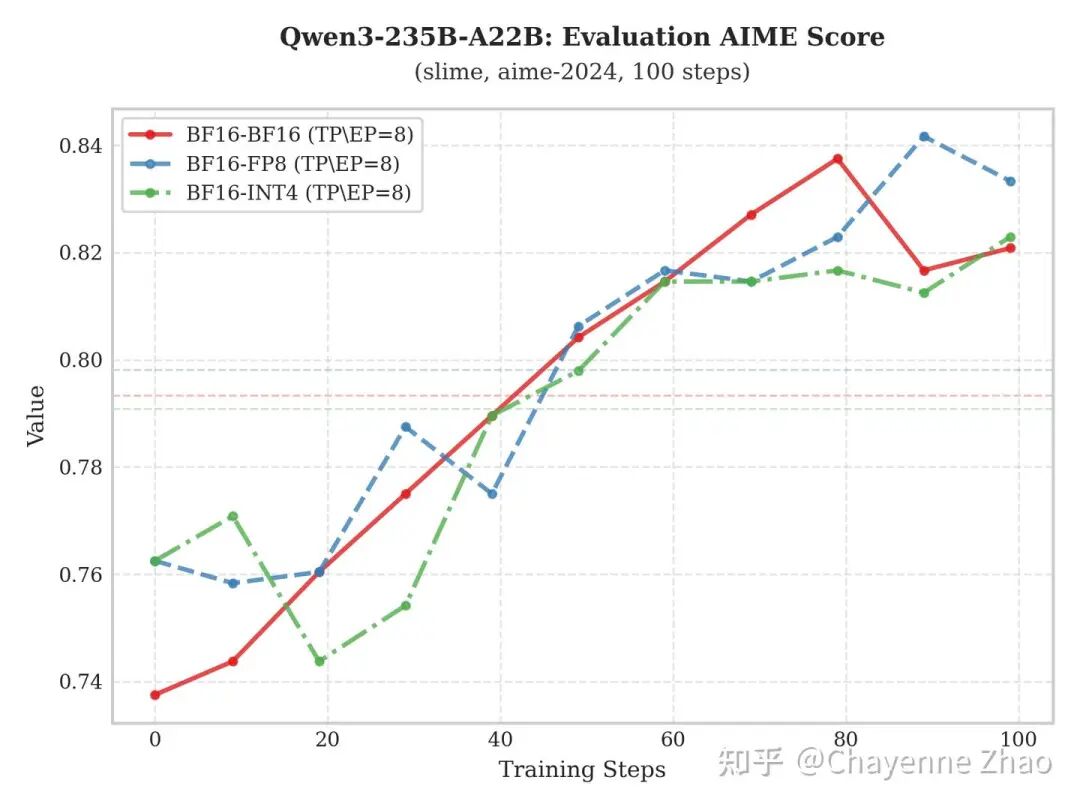
为了更加严谨地评估模型能力的演进,我们每隔 10 个训练步长就在 aime-2024 基准测试集上进行一次评估。上图给出了 Qwen3-235B-A22B 与 Kimi-K2-Thinking 在不同 RL 训练配置下的模型评分增长轨迹。
实验表明:“BF16训-INT4推” 方案不仅在评估分数上呈现出稳健的上升态势,且其性能提升的斜率与最终达到的峰值,均与 “BF16训-BF16推” 和 “BF16训-FP8推” 方案保持了较高的重合度。这种高度的一致性有力地证明了模型在经过低比特量化后,其核心表示能力并未受损,保证了在大幅降低计算开销的同时,依然能够实现与全精度推理相媲美甚至完全看齐的泛化表现。
2. 训推差异
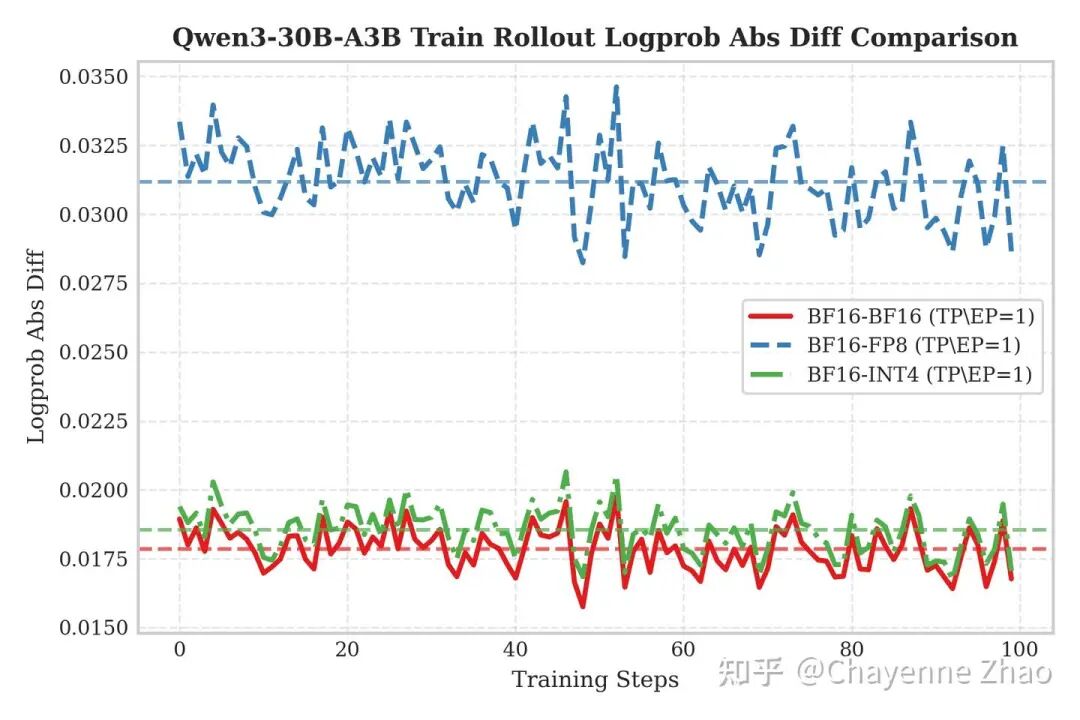
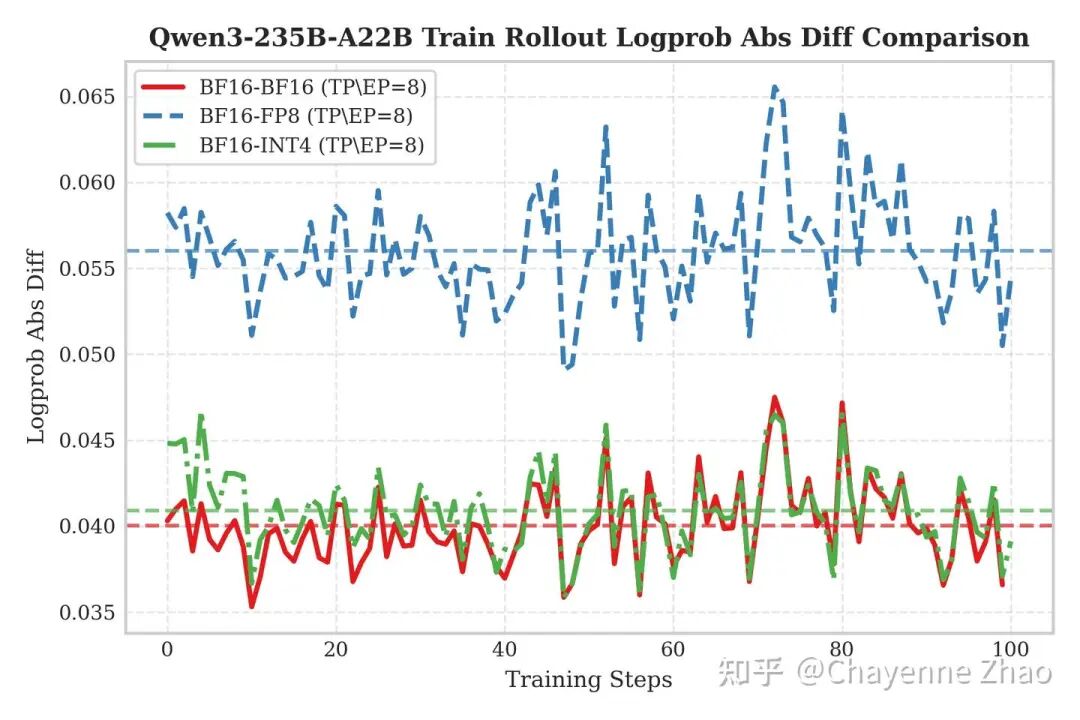
为了直观评估方案效果,我们在 Qwen3-30B 与 Qwen3-235B 模型上进行了的 QAT RL 训练验证。图中 Y 轴反映了训练侧与推理侧输出的 Logprob 绝对差值,数值越低意味一致性越强。实验结果显示,INT4(绿色虚线)与BF16 基准(红色实线)呈现出惊人的重合度,且显著低于表现出较高误差水平的 FP8(蓝色虚线)。这证实了 INT4 QAT 策略能有效规避 “BF16训-FP8 推” 模式下的精度损失,实现与全精度无异的训推表现。
这种一致性背后的原因我们推测为两点:
截断误差抑制:训练侧的 Fake Quantization 将权重限制在 INT4 值域内。这种数值范围的约束,有效降低了矩阵乘法中 Accumulator 累加时因并行计算顺序不确定性引发的浮点舍入误差(Floating-point Rounding Error),即改善了所谓的“大数加小数”精度丢失问题。reference
高精度计算:推理侧采用 W4A16 模式,其核心计算全程基于 BF16 Tensor Core 进行,确保了运算精度与训练阶段的高度对齐。
3. Rollout 加速
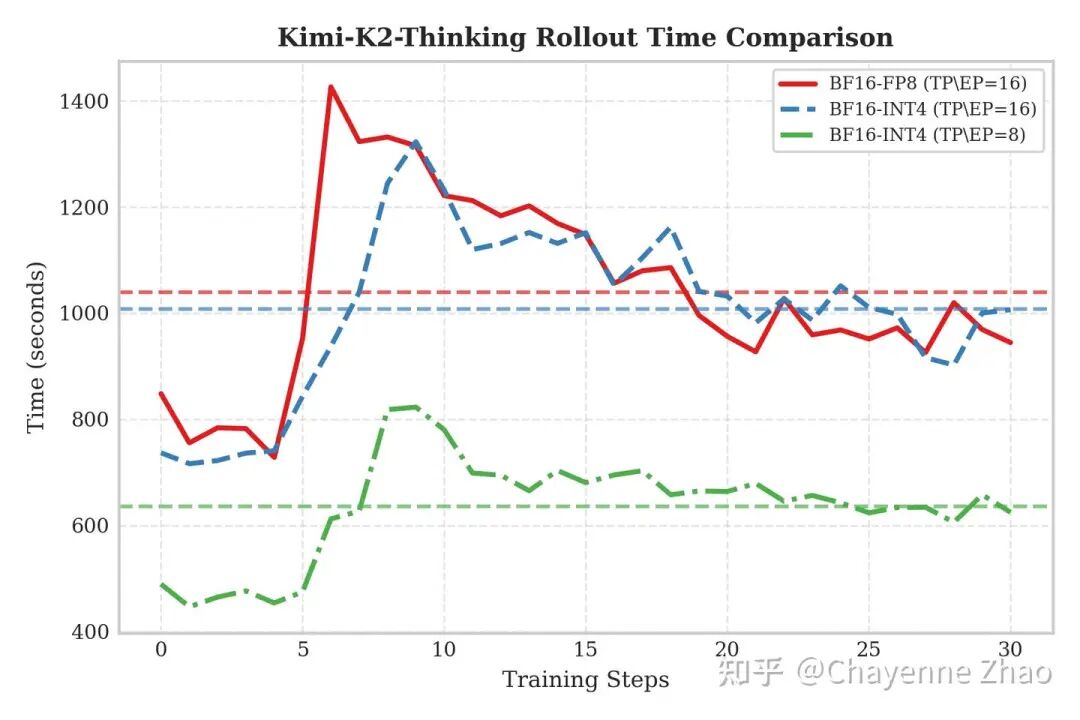
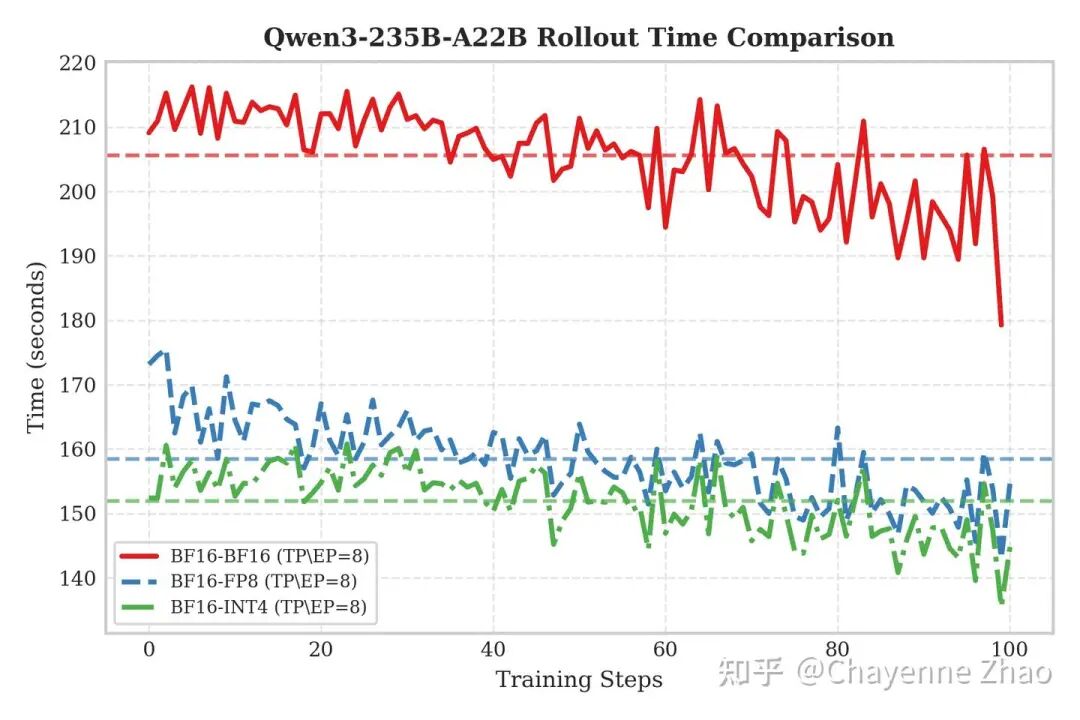
从 Qwen3-235B 的 Rollout 性能对比图中可以直观看到,虽然 INT4(绿色点划线)与 FP8(蓝色虚线)均较 BF16 基线(红色实线)实现了显著加速,但两者彼此之间并未拉开巨大的性能鸿沟。这一现象主要受限于当前的硬件特性:由于 NVIDIA H 系列 GPU 没有原生的 INT4 Tensor Core, W4A16 方案本质上利用的还是 BF16 Tensor Core 进行计算,虽然大幅降低了显存带宽压力,但在吞吐上无法像 W8A8 一样利用原生 FP8 Tensor Core 进行加速从而获得计算增益。因此,在单步推理耗时上,INT4 仅表现出微弱的优势,与 FP8 基本处于同一性能梯队。
对于 Kimi-K2-Thinking Rollout 性能的对比,首先观察双节点场景下的通信瓶颈:图中 FP8(红线)与 INT4(蓝线)呈现出相似的水平。因为 H 系列 GPU 缺乏原生的 INT4 计算单元,INT4 无法在计算层面提供加速,因此整体性能依然受限于跨节点的通信带宽。
然而,绿线所代表的单节点表现揭示了 INT4 的真正价值——显存压缩。通过将模型体积减半,我们成功将 1TB 级别的超大模型完整加载至单机显存中。这直接消除了昂贵的跨机通信开销,将 Rollout 耗时大幅缩减。这有力地证明,在当前硬件环境下,INT4 QAT 的核心收益在于通过压缩显存,解锁了高效的单机部署 Rollout 方案。
06 总结与未来工作
通过在开源框架上的复现,我们验证了 Kimi 团队所提出的 INT4 QAT 方案的有效性:
精度复现:在 slime 的复现实验中,我们同样观察到了 INT4 QAT 的精度优势,实现了与 BF16 基线一致的效果。
效率提升:RL Rollout 阶段的吞吐提升显著,验证了低比特量化在 RL 场景下的巨大价值。
未来工作:
训练端效率优化:目前,由于在训练过程中引入了 QAT Fake Quantization 计算,带来了较大的额外性能开销,导致训练速度明显低于 BF16 模式。这在一定程度上折损了 Rollout 阶段带来的端到端性能收益。我们后续计划提出一套全新的优化方案,旨在解决这一训练侧的效率瓶颈,实现全链路的加速。
推理侧 FP4: 随着 NVIDIA Blackwell 架构的逐步普及,我们将积极探索 FP4 精度在 RL 训练与推理中的应用可行性,以期进一步挖掘硬件潜力。
我们在 QAT INT4 的尝试不仅证明了在开源生态中复现工业界前沿方案的可行性,也为超大规模模型的低成本训练探索了新的路径。我们期望这套方案能够助力更多开发者深入理解 QAT 技术,并推动其在 RL 场景下的实际落地与广泛应用。
致谢
1. SGLang RL Team:Ji Li, Yefei Chen, Xi Chen, BBuf, Chenyang Zhao
2. InfiXAI Team:Mingfa Feng, Congkai Xie, Shuo Cai
3. 蚂蚁集团 Asystem & 阿福 Infra 团队:Yanan Gao, Zhiling Ye, Yuan Wang, Xingliang Shi
4. slime Team: Zilin Zhu, Lei Li, Haisha Zhao










