绑定手机号
确认绑定









作者:浮生梦晓
地址:https://zhuanlan.zhihu.com/p/1924055664327656954
经授权发布,如需转载请联系原作者
强化学习智能体训练的论文中都广泛提到的一个思想:SFT极度依赖数据质量及数据多样性,PPO 系列算法(DAPO、GRPO、RENFORCE++、RLOO)是 online 的 rl 方式,每个状态步从环境中采样数据,需要的原始数据远低于 SFT。但目前为止,智能体的强化学习训练并没有出现效果很出彩的方案,归结于 base model 策略决策能力不足也好,还是真实环境过于复杂也好,目前的智能体强化学习训练还处于探索时期,在简单环境中表现出彩,如单机游戏等环境状态有限的场景,GUI 任务上目前的方案还是 SFT 为主,本文将 25 年以来知名度较高的几篇 GUI 强化学习训练的论文做了个小总结。
LLM 的 RL 训练(RLHF,RLVR)一般是单步的(这句话可以理解为虽然每个 token 可以视为 1 个 动作,但整体模型自回归后的输出是视为 1 步,如解决数学问题),使用 RM 或 Rule Base Reward,来提供 这一步的奖励值,但智能体 RL 是需要与环境交互,是需要有完整轨迹的多步 RL 训练,相对来说会存在一系列共性问题:
trainer 与 rollout 的同步异步问题(环境的调用耗时不一,可能高于单次批推理);
不同任务 trajectory 的 steps 不同,同一任务在环境中存在多种实现方案,如何部署实现批次RL 训练;
奖励函数设计,训练过程可以预料的不稳定;
不同 RL 算法与不同 Agent 任务的适用性,典型 GRPO/DAPO 算法如果用在 GUI 任务上,多步任务情况下组内每个任务都可能失败,对训练提升无意义;
…可能还有一些
部分 Agent 多步轨迹 RL 的论文中发现的特性:
(RAGEN\TooLRL)智能体 RL 训练会出现一种反复出现的“回声陷阱”模式,奖励方差出现断崖式下降,梯度出现峰值,而动态奖励有助于模型长轨迹训练。
(RAGEN)多样化的初始状态、中等交互粒度和更多的响应有利于 RL 训练。
(RAGEN\ToolRL\GIGPO)需要有细粒度的奖励信号,否则 agent RL 训练后会出现幻觉。
(Nemotron-Research-Tool-N1)轻量级奖励函数(function call 格式及参数正确性过滤)后进行强化学习训练会提升最终效果(提升泛化性及输出function call 结构正确性)。
异步 Rl 训练:
当前主流RL 框架( verl,openrlhf,AReal,slime)都开始支持不同程度的异步 RL训练,整体会分为训练(trainer)和推理(rollout)两个部分,一般训练采用(FSDP/FSDP2/DeepSpeed/Megatron),推理采用(sglang/vllm)。
下图来自 AReal强化学习训练框架论文:
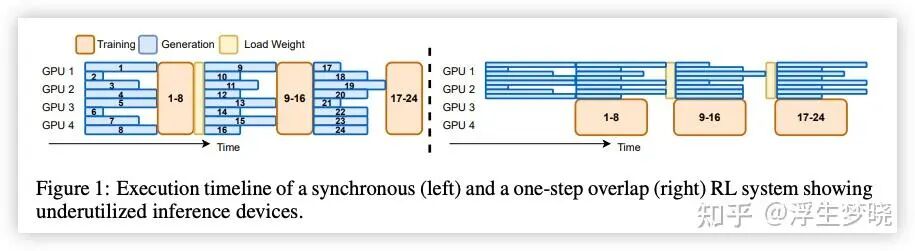
上图中左图为同步RL流程,具体缺点:
对于批处理来说,每次 rollout 时每个任务执行长短不一,但训练前需要等待这批任务中所有任务rollout完成才能开始,这样会导致任务执行时间较短的 GPU 处于闲置。
如果 trainer 与 rollout 所占用的 GPU 不同(trainer 是 1 个 GPU 集群,rollout 是另一个 GPU 集群)则会造成在二者在运行过程中必然会存在一个集群闲置。
上图右图是初级异步 RL 流程:
当 rollout 的 GPU 集群使用当前策略完成了这批任务后,立即使用当前策略来处理下一批任务,trainer 集群会同步进行训练,训练完成后会将更新后策略广播给 rollout 集群,这种轻微 offpolice 训练方案样会消除 trainer 与 rollout 的 GPU 集群在运行中必然有一方闲置的问题。
AReaL 提出了消除 rollout 内部气泡的方案,这里不再展开,只是介绍同步异步的概念,后面研究了不同 RL 训练框架后再展开讨论不同的框架是如何进行异步强化学习训练的。
下面是一些 GUI 智能体强化学习训练的论文,有强化学习训练用于多步轨迹的,也有强化学习训练用于单步预测。
01 WEB AGENT-R1: Training Web Agents via End-to-End Multi-Turn
Reinforcement Learning
https://arxiv.org/pdf/2503.21620
Web任务的挑战:动态的任务(区别于 SFT 训练的行为克隆)以及多种解决方案(同一种结果存在多种实现方案)
行为克隆方案的缺陷:限制了智能体探索多种解决方案以及在试错中学习的能力;
当前智能体RL方案的不足:主要是 offline 或者 off-police 的 RL 训练方案,没有端到端的让智能体与环境交互,训练后的智能体泛化性差。
on-police 的 RL 训练优势:消除训练与真实环境的 gap,节省存储 offline 轨迹的开销。另外 on-police 保证了任务直接的依赖性(如先修改当前页面再关闭当前页面,离线数据可能存在依赖倒置)。
介绍几个 RL 基本概念:online(智能体中真实环境中训练),offline (智能体不是中真实环境中训练);on-police(智能体使用自己产生的轨迹来提升自己的策略能力),off-police(智能体用其他来源的轨迹来提升自己的策略能力)。
1. 本文贡献
RL 训练中每个状态包含 web 页面的 HTML 内容,token 过长,提出了一种动态上下文压缩方案,同时使用异步轨迹展开来提升训练效率。
当前 LLM 的 RL 算法不适合多步智能体,提出了 M-GRPO 算法,并在WebArena-Lite benchmark上取得了 sota。
通过实验分析证明了行为克隆的关键作用,验证了思维链的有效性,提出了长思维链的见解。

2. 总览示意图
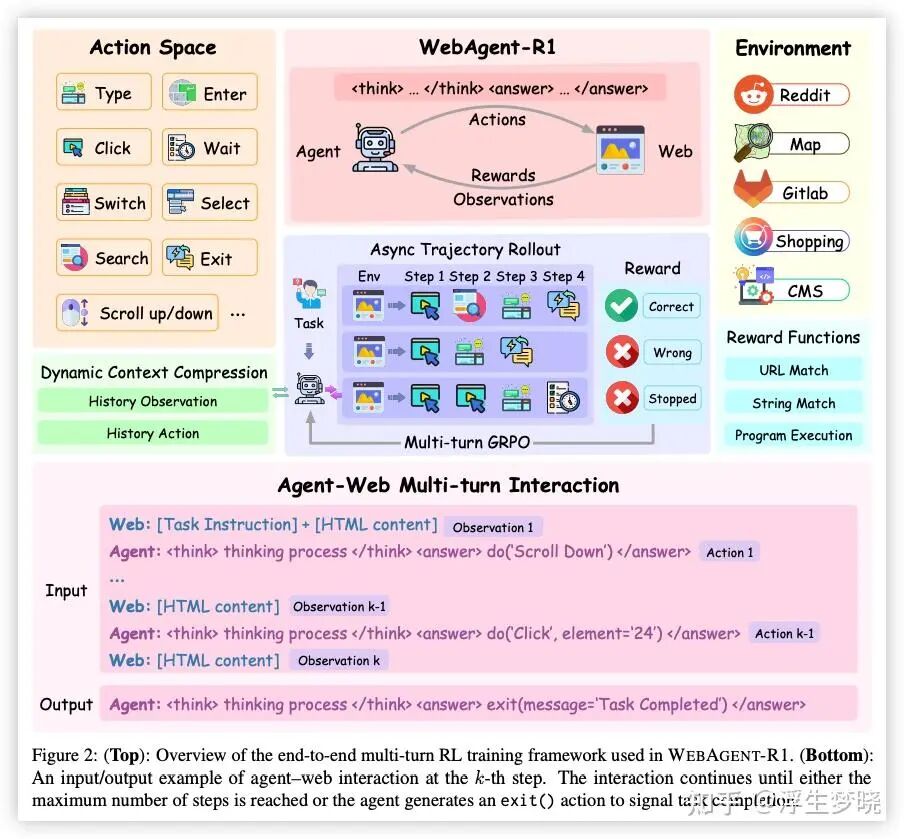
行为克隆(BC)
Loss:

端到端的多轮 RL 训练
Reward:二元结果奖励「0, 1」
动态上下文压缩:
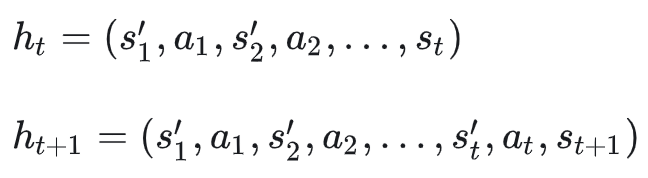
每次状态更新会将之前的状态的 Observation (html)简化为简单内容:“Simplified HTML”
多轮 GRPO

GRPO 公式(GRPO的原理不再展开,本身是 PPO 算法的优化,展开又很大篇幅,PPO 可以阅读我之前的文章):
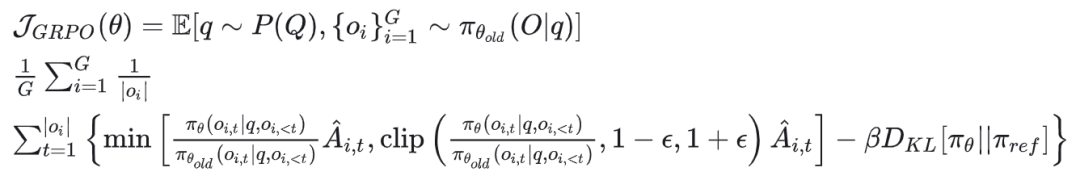
M_GRPO 公式:

字符介绍:
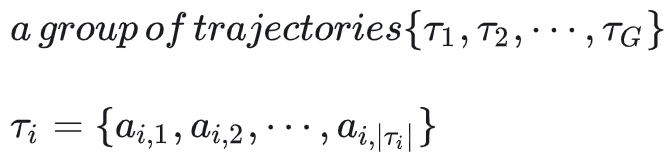
:当前轨迹 i 中的第 j 个动作
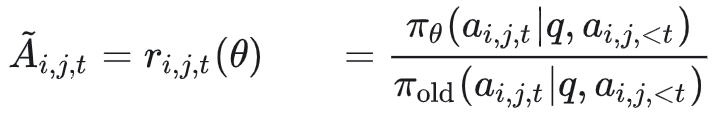
:轨迹 i 中第 j 个动作对应的第 t 个 token

:重要性采样
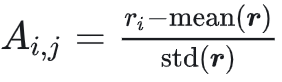
:组内相对优势
异步轨迹 Rollout
生成一组轨迹需要与环境频繁交互,耗时很长,因此需要异步进行。需要有多个独立的环境实例, 每个实例有独立的上下文轨迹。对于每个任务,每个环境实例从相同的状态开始,根据执行动作的不同会产生不同的历史轨迹。
奖励设计:基于规则的结果奖励,成功为 1,失败为 0.
3. 实验部分
论文是 web 任务,配置的 web 环境及测试 benchmark 不再详细赘述。
实验结论:
论文是使用的 html 做文本输入llm,没有使用 vlm。第一个结论是当前的 LLM 如果进行微调是不足以完成智能体任务。

第二个结论是思维模型更适合做 web 智能体。
第三个结论是强化学习训练(先 BC)可以大幅度提升 web 智能体表现(仅行为克隆与 RL 的对比)。
动态实验
训练过程中奖励值、轨迹长度(总 token)、轨迹中 step 个数变化情况,将整体训练过程分为了三个阶段,分别是:初始、测评提升、策略稳定阶段。曲线均符合强化学习训练的预期,先初始技能获取,再策略优化探索,最后稳定。

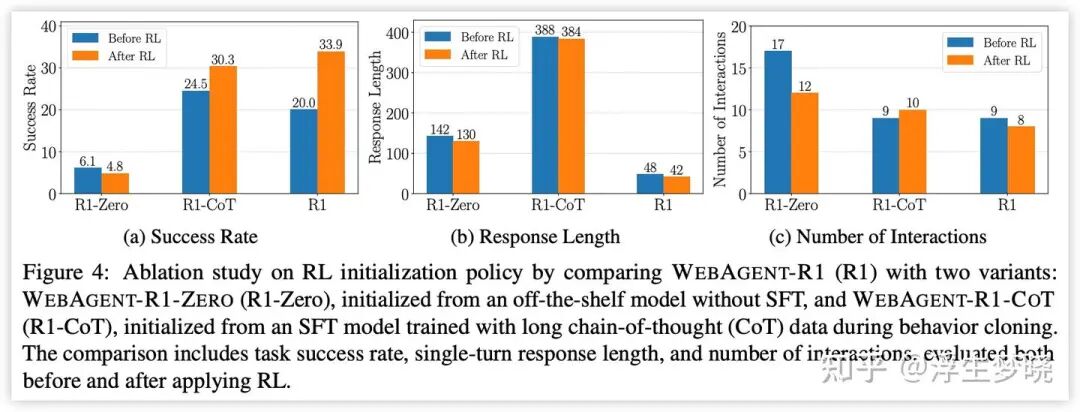
消融实验
目的是看 BC(行为克隆,SFT)的作用,设计了两种对照实验,分别是:WEBAGENT-R1-ZERO 和 WEBAGENT-R1-COT,前者是不经过 BC,直接进行 RL,后者是在长思维链上进行 BC,再进行 RL。
结论曲线:
4. 结论
BC 对于 web 智能体 RL 训练十分重要。
长思维链的 BC 再进行 RL 效果更好。
RL 训练对于长思维链的 BC 提升有限。
论文中其他内容参考意义不大,本文是对 LLM 做为 agent 的实验结果,对 MLLM 做为 agent 参考价值有限。
02 UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning
https://arxiv.org/pdf/2503.21620
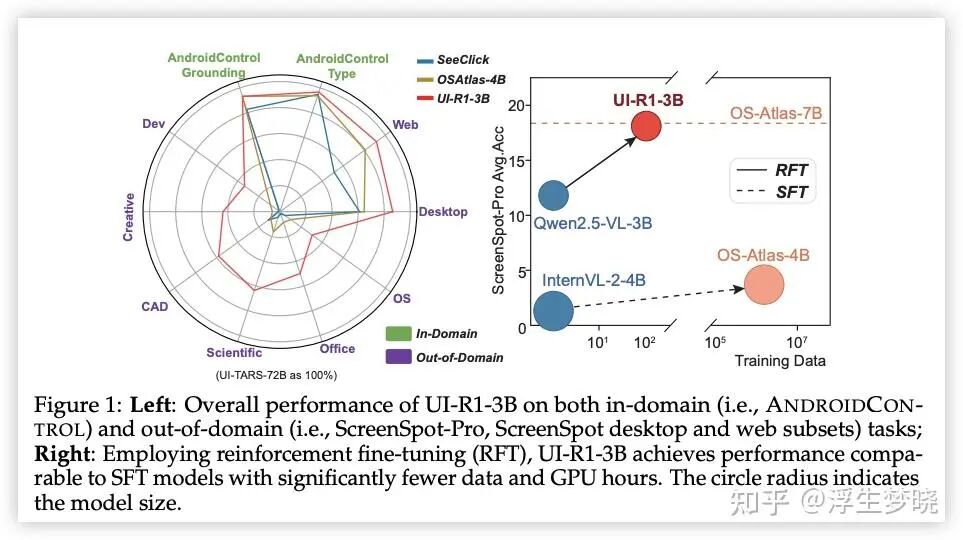
一句话总结:基于规则奖励的GUI任务MLLM 的强化学习训练,使用更小模型,更少的训练样本,更少的训练时间达到 benchmark 较高的准确率。本论文不是多步轨迹智能体的 RL 训练,而是单步 grounding 定位及 Action的RL训练。
1. 本文贡献
提出了 UI-R1,这是首个通过 DeepSeek R1 风格的强化学习,在图形用户界面(GUI)动作预测任务上提升多模态大语言模型(MLLM)推理能力的框架。
计了一个基于规则的动作奖励函数,该函数能有效地与常见图形用户界面(GUI)任务的目标保持一致,有助于策略模型的自我完善和迭代优化。通过消融实验验证了该奖励函数的有效性。
仅使用 130+高质量数据就在 OOD 任务上取得很好的效果(指的是测评 benchmark)。
开源了模型: UI-R1-E-3B。

相关工作:
提到很多GUI工作都依赖SFT,如 UITars这需要大量任务导向的标注数据集,且泛化性较差。
提到基于规则奖励函数的强化学习训练。
提到模型回复长度的奖惩 RL 训练,让模型回复内容正确且简洁。
2. 实现方案
UI-R1-3B的 RL 训练方案还是 GRPO:
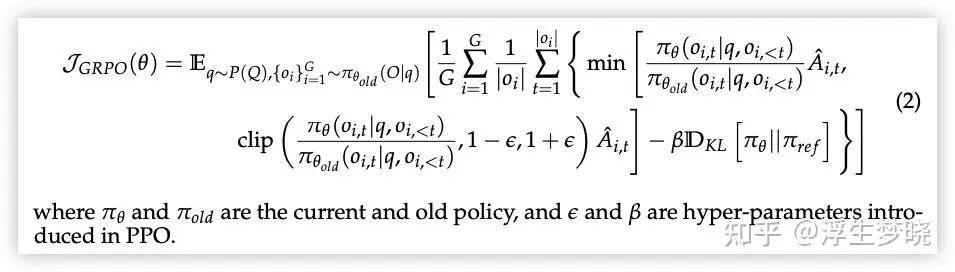
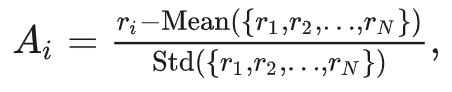
UI-R1-3B的初始定义的规则 Action 奖励函数设计

第一个代表动作类型奖励(click,scroll 等),二元奖励[0,1]
第二个代表动作坐标奖励,命中 grounding 奖励,二元奖励[0,1]
第三个代表模型回复格式奖励,论文没有提到奖励值如何计算。
UI-R1-E-3B 增加的两训练阶段
两阶段训练,DAST 训练阶段和NOTHINK训练阶段,每个阶段 4 个 epochs。
DAST 训练
token 长度预算:(使用 GRPO 让模型根据一个问题生成多个回答)
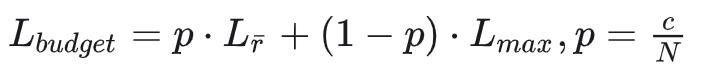
:某个问题得到的正确回答的数量
:某个问题得到的全部回答数量
:正确回答的平均token数量
:最长回答的token数量

长度奖励函数的定义理解:如果一个回答正确,但是长度超过了预算长度,如果过大会使得λ大于 1,则整体奖励值减小到 0.1,如果长度趋近预算长度,则λ约为 0,则整体奖励值为 0.5。错误回答同理。
将长度奖励函数加入到 Action 奖励函数中:

NOTHINGK 训练
去除掉标签,在任务回答中去除显示思考。
通过消融实验得出结论:
数据选择
前置信息:与监督微调(SFT)相比,基于规则的强化学习已证明,仅使用有限数量的训练样本,就能在数学和视觉相关任务上取得相当甚至更优的性能。
数据选择要素:质量、难度(保留困难样本)、多样性。最终选择了 136 个样本来进行训练。
3. 实验结果
实验分为GUI Grounding Capability和Action Prediction Capability。
GUI Grounding Capability


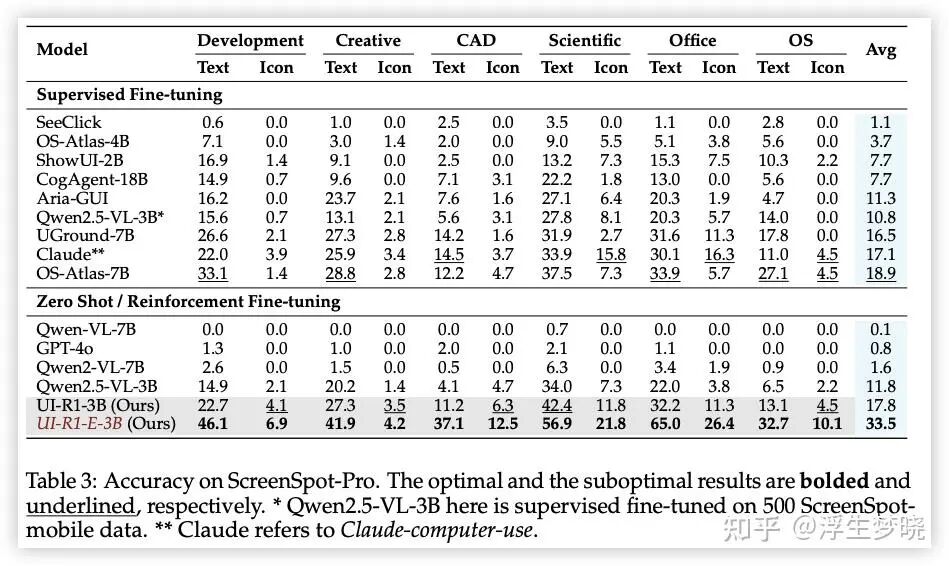
再声明:UI-R1-E-3B 是在UI-R1-3B基础上增加的两阶段训练,即去除了思考过程以及约束了模型输出长度,各项指标反而大幅度高于UI-R1-3B,印证作者之前提到的(只对纯 Grounding 有效):
Action Prediction Capability(这里是单步的动作预测)

结论:UI-R1-3B 在 136 个样本上进行强化学习,效果大幅度高于 Qwen2.5-VL(Zero Shot)
消融实验
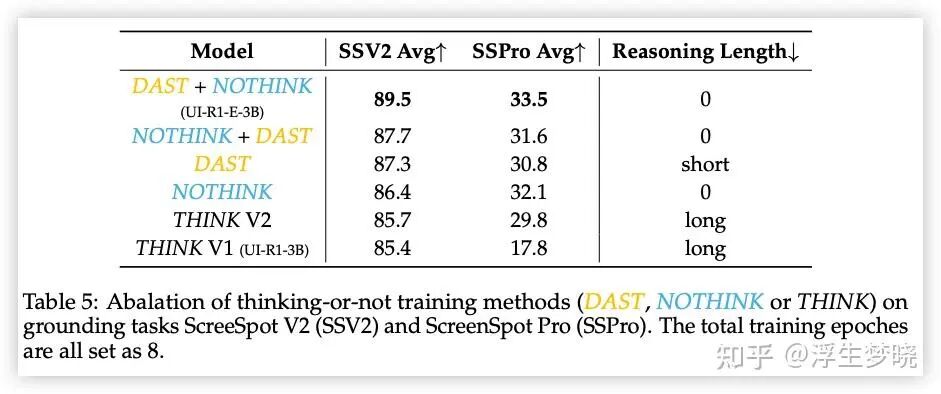
Grounding 任务上,先约束模型回复长度再去掉思考过程的训练方式最优。
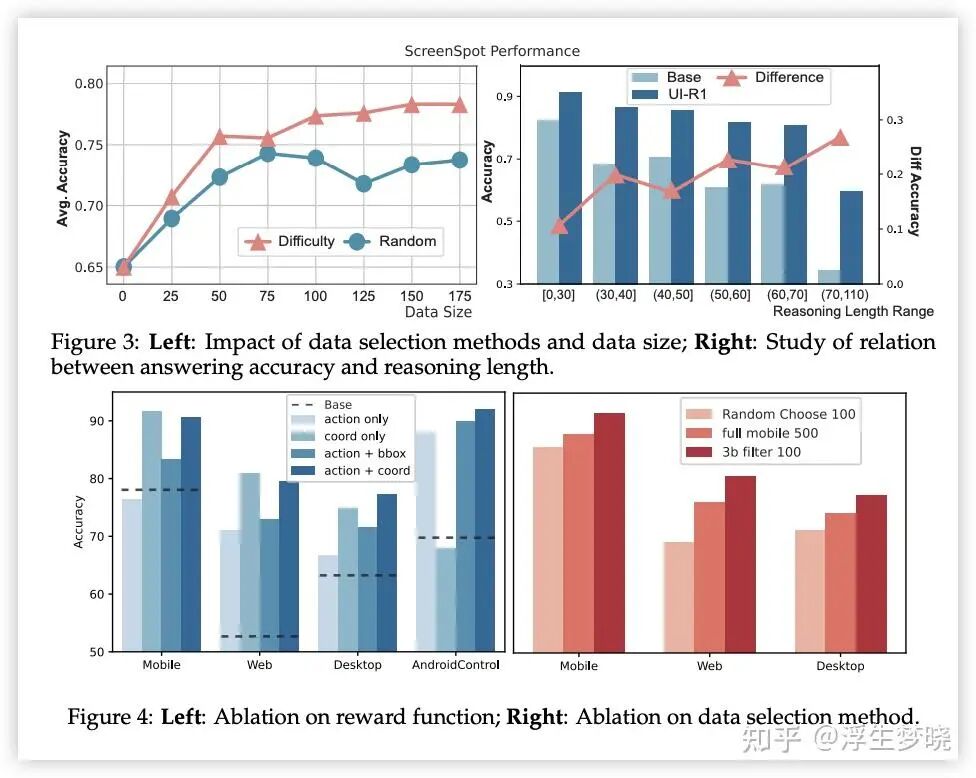
选择困难样本效果优于随机选择;
模型思考长度增加反而会使得正确率降低;
动作执行像素点的奖励值最好不使用 IOU 形式,直接使用命中率;
质量、困难性、多样性选择RL 训练样本的方式更优。
本文结论有待商榷验证,测评结果倾向性太明显。
03 GUI-R1: A Generalist R1-Style Vision-Language
Action Model For GUI Agents
https://arxiv.org/pdf/2504.10458
一句话总结:当前GUI 的 SFT 的训练方案对 OOD 场景泛化性太差,本论文方案使用 GRPO 进行强化学习训练,只需要少量高质量数据(3000 个)就达到非常效果,验证了强化学习训练在 GUI 任务上的重要性。

效果总览,Low-level指令简单,如打开桌面上谷歌浏览器;High-level 任务指令运行复杂,如:使用 X 应用程序研究并找出一款高度推荐的扫地机器人,然后前往亚马逊购买一台。
1. 本文贡献
提出了 GUI-R1,首个利用基于规则的强化微调来提升大语言视觉模型在高级图形用户界面(GUI)动作预测任务中推理能力的框架。
设计了一个基于规则的统一动作空间奖励函数,该函数能有效地验证不同平台和任务粒度下的图形用户界面(GUI)任务响应。这确保了可靠且高效的数据选择和模型训练。
利用基于规则的统一动作空间奖励函数,构建了 GUI-R1-3K,这是一个具有多样性和复杂性的高质量微调数据集。该数据集显著提高了训练效率和模型性能。
对图形用户界面(GUI)智能体进行了全面评估,涵盖三个不同平台(桌面端、移动端和网页端)以及八个基准测试中三个层次的任务粒度(低级基础任务、低级任务和高级任务)。实验结果表明, GUI - R1 在多种现实场景中处于领先地位。这为未来的研究创建了一个强大的 GUI 智能体基线。——(有点强行拼凑创新贡献)
相关工作
提出了当前根据不同任务进行 SFT 的方案如 UITars的两点局限:
训练过程需要大量多样的数据;
模型的泛化能力有限,难以理解图形用户界面(GUI)截图并适应未见的界面。
总览图
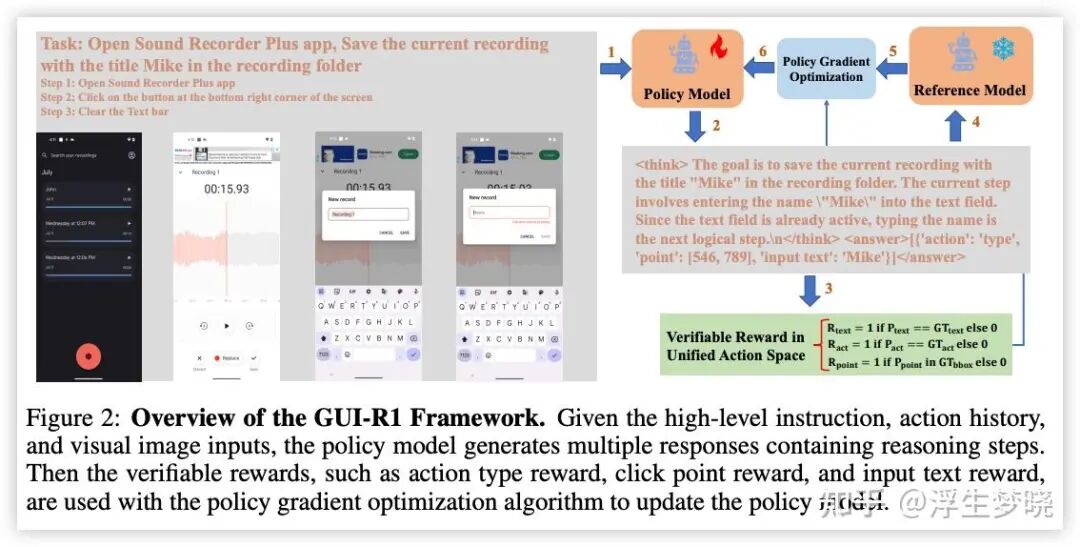
训练方案
还是 GRPO,论文中连 GRPO 公式都没有列出…,对单步输出进行 GRPO 训练,输入是历史信息,当前截图以及指令。不是对 agent 进行 GRPO 训练。
模型输出内容的格式奖励
action 及 grounding 任务格式要求:

正确率奖励
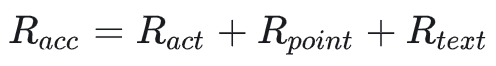
action 奖励:动作类型正确与否,二元奖励[0,1]
point奖励:point 命中 grounding,二元奖励[0,1]
输入 text 奖励:模型给的 text 与 gt 中 text的 F1 分值是否大于 0.5,二元奖励[0,1],论文没有给出无 text 情况下该项奖励如何给值
最终训练的奖励
上面两种的加权:

数据工程

最终筛选出来的 3K 个样本分布,来源自多个开源数据集,使用上面奖励函数对数据进行评估过滤再随机采样,最终获得3K 高质量数据。
2. 实验部分
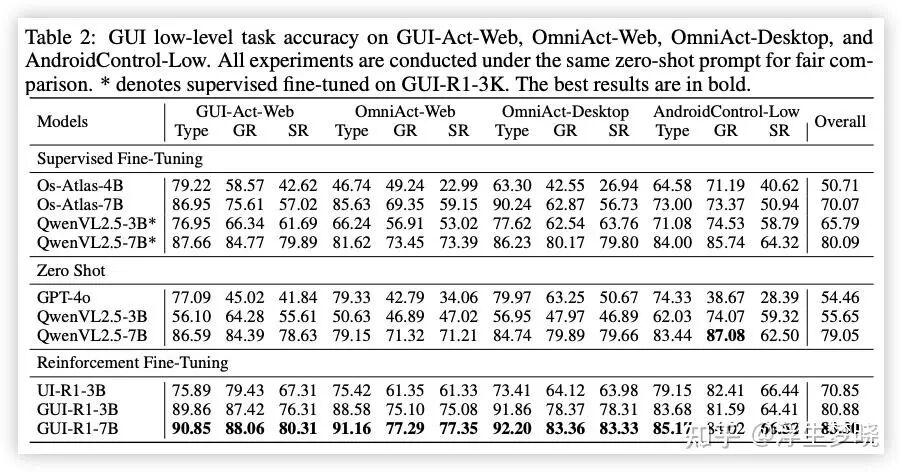
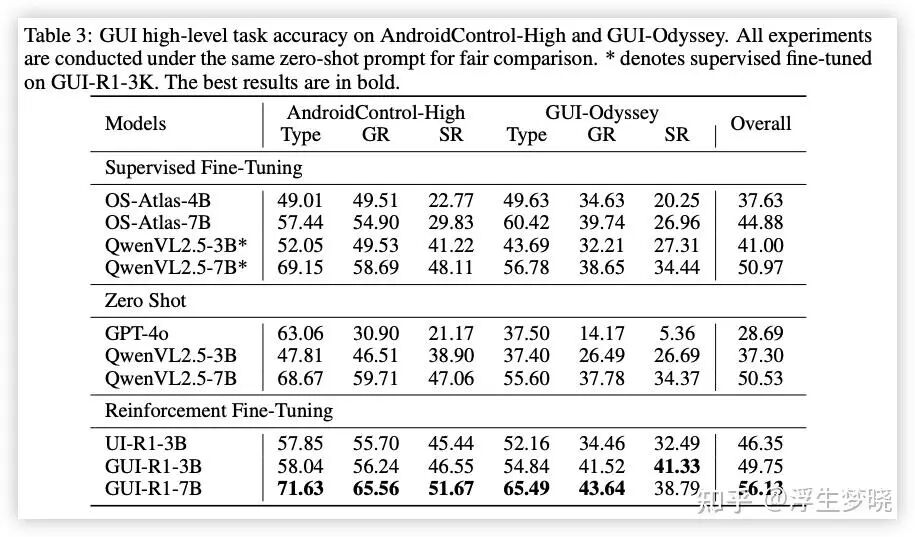
Type:动作类型准确率
GR:point 命中 grounding 准确率
SR:function call 格式内容完全正确率
消融实验:

训练过程:
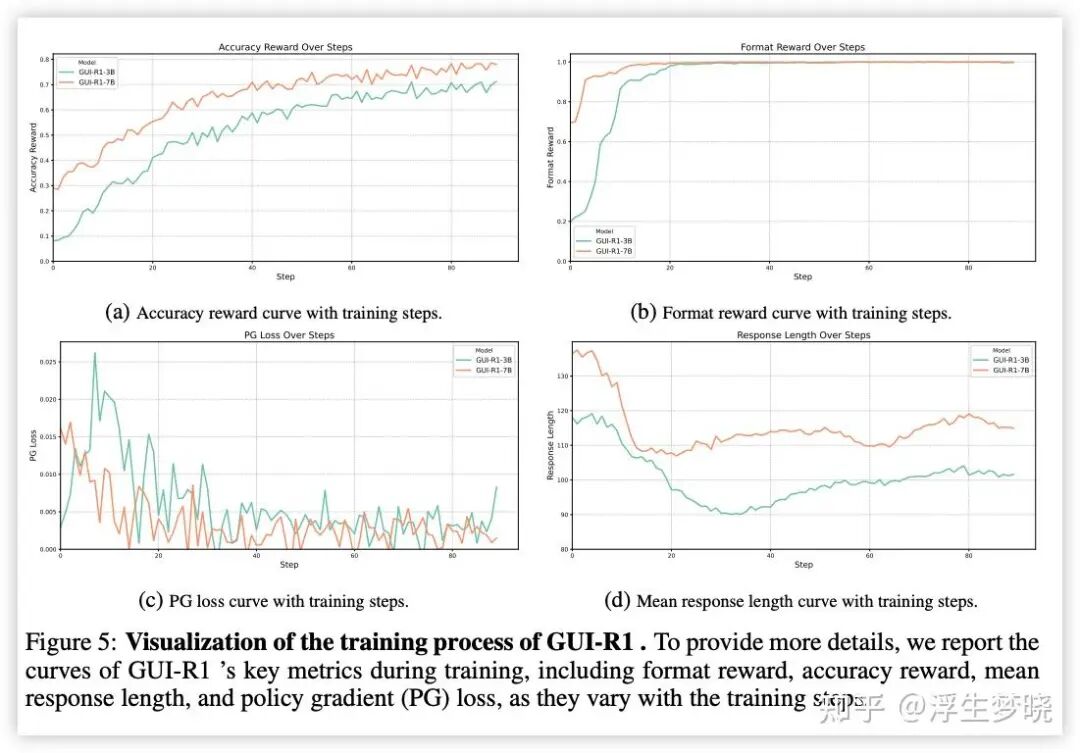
未出现类似 R1 的“顿悟”时刻,整体曲线较为连续。
本论文内容干货较少,仅证明在 GUI 任务上强化学习可用性,且仅对单步输出内容使用 RL 训练。
04 InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
https://arxiv.org/pdf/2504.14239
一句话总结:GUI 任务需要显式的推理过程,论文就是为 MLLM 加上推理过程,通过两阶段,首先是推理内容注入,其次将推理内容修改的更优。
总览:
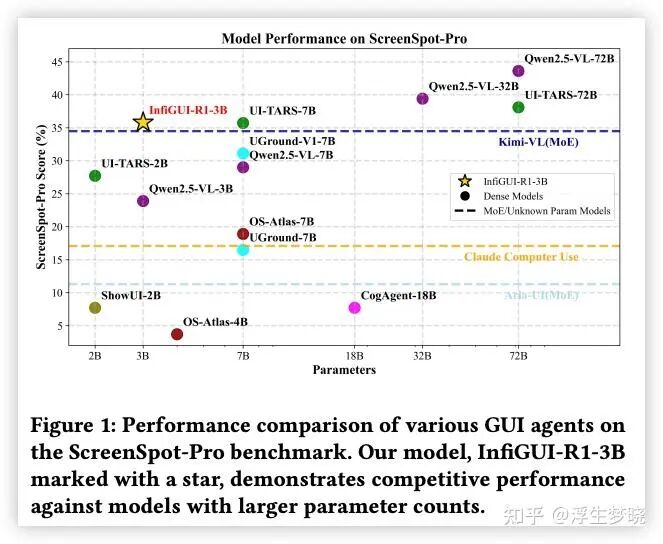
前面三篇论文中,第一篇是使用强化学习对整体的GUi 任务轨迹进行训练,第二和第三篇是对单步的智能体输出内容进行训练,本篇论文则是使用强化学习对模型中 GUI 任务从没有推理能力到有推理能力进行训练。
1. 本文贡献
提出了 Actor2Reasoner 框架,这是一种新颖的两阶段训练方法,旨在通过逐步注入和完善推理能力,将基于多模态大语言模型(MLLM)的图形用户界面(GUI)智能体从被动反应式执行者系统地转变为主动慎思式推理者。
这个框架内,引入了三项关键的技术创新:空间推理蒸馏,用于建立基础的跨模态推理;子目标引导,用于增强规划推理;以及错误恢复场景构建,通过有针对性的强化学习培养反思性纠错能力。
发布了InfiGUI-R1-3B。
核心在于Actor2Reasoner 框架,之所以要开发这个框架是因为作者认为,从根本上提升图形用户界面(GUI)智能体的能力需要一种范式转变:需要从被动执行的智能体转向严谨的推理发挥作用的智能体。这些智能体应在感知与行动之间明确融入推理过程(感知→推理→行动),使其能够提前规划、分解复杂目标、深入理解空间关系,并反思过去的行动以纠正错误。这种转变对于应对现实世界 GUI 环境的复杂性和动态性至关重要。(这也是作者向DeepSeek-R1对齐的原因,这种推理范式作者需要借助 R1 的RL 训练方案来在 GUI 任务上复现,模型自己学会复制任务推理任务的分解、规划和反思纠错)
Actor2Reasoner 框架应对两个核心挑战:
注入基础推理能力,需要具备视觉空间感知与文本推理之间关键的跨模态能力,以实现从行动者到推理者的初步跨越;
优化并提升这个基础推理能力,赋予其高级规划和反思能力,最终达到严谨推理的阶段。
Actor2Reasoner 框架也分两个阶段展开:
推理能力注入:说白了就是监督微调,让模型根据标注的推理内容具备基础的推理能力。
推理能力增强:通过 RL 训练让模型的推理具备规划和反思的能力。
规划(子目标分解)能力:为了增强智能体的前瞻性规划和任务分解能力,引导它在推理过程中生成明确的中间子目标。这些生成的子目标与事实情况的一致性提供了一个中间奖励信号,有效地训练智能体主动规划的能力(“总目标→子目标→行动”)。
错误恢复场景构建:作为对规划能力的补充,这一创新培养了智能体通过反思性自我纠正进行回顾和调整的能力 。需要在强化学习环境中积极构建模拟错误状态或恢复时刻的场景(例如,刚刚执行了一个错误动作,或者在出错后需要 “回到正轨”)。在这些场景中进行训练,并使用有针对性的奖励,促使智能体学习适应性策略,如摆脱错误状态(例如,使用 “后退” 动作)以及在认识到错误后调整计划。这直接塑造了智能体反思自身行动并从失败中恢复的能力,增强了其稳健性。
(上面内容直接翻译的)
Actor2Reasoner框架总览

相关工作
这部分没什么可说的,就列举了一系列 GUI 工作。
2. 实现部分
Stage 1: Reasoning Injection
步骤:从教师模型中蒸馏出推理轨迹,使用轨迹来训练目标模型。
首先定义推理瓶颈样本,这些样本使得模型推理失败是因为模型本身的推理能力不足造成,而非感知不足或执行不正确造成。(可以理解成上面任务的执行低水平(详细指令)的任务,但没办法执行高水平(简单指令)的任务)
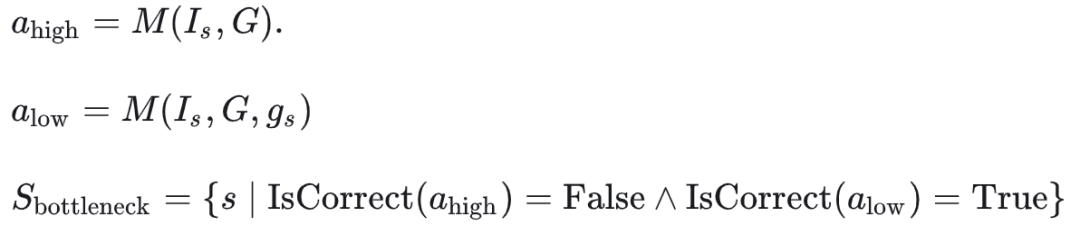
:模型推理的上下文
:任务总目标,高级指令
:子任务目标,低级指令
当仅高级指令执行失败,但低级指令执行成功时判断当前step 为本轨迹的瓶颈 step。
生成空间推理轨迹:对于瓶颈step 中的每个 step,都使用能力更强的教师模型生成详细的推理信息,推理信息中包括:
空间信息提取和压缩:通过 a11y树来提取,仅保留元素类型、文本内容、坐标和层级结构。然后,使用强大的多模态大语言模型(如 Qwen2.5-VL-32B - 指令模型)将这些处理后的信息压缩为简洁的文本描述空间,其中包含图形用户界面页面的详细描述,包括特定步骤的所有相关元素的坐标信息和描述,从而获取基本的空间布局和关键元素。
推理轨迹生成:压缩后的空间描述和动作空间描述以及该 step 任务总体目标作为输入,送入具有强大推理能力的大型语言模型(例如,QwQ - 32B )。蒸馏出文本推理和动作执行内容,蒸馏出的文本推理内容需要清晰阐述逻辑步骤,包括通过空间描述里的空间信息来进行元素定位、关系评估和预期动作。
通过 SFT 为目标模型注入推理能力。将截图及高级指令做为输入,推理轨迹(推理内容及动作)做为输出来对目标模型进行监督微调,使其具备初步推理能力。
Stage 2: Deliberation Enhancement
本步骤通过RL 训练,核心作用是在基础推理能力上使模型再具备“审议式”推理能力,即具备任务分解及反思纠错能力。
Rl 训练设置
算法:REINFORCE Leave-One-Out (RLOO),该方案通过将同一批次中其他样本的平均奖励作为当前样本的基线,有效地降低了策略梯度估计的方差。
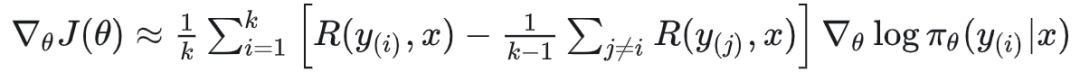
:模型针对同一个输入的个输出
:输入后模型输出的奖励值
RLOO 算法是在策略梯度定理上优化的去掉价值评估模型的强化学习算法,一个创新方案。
策略梯度定理:
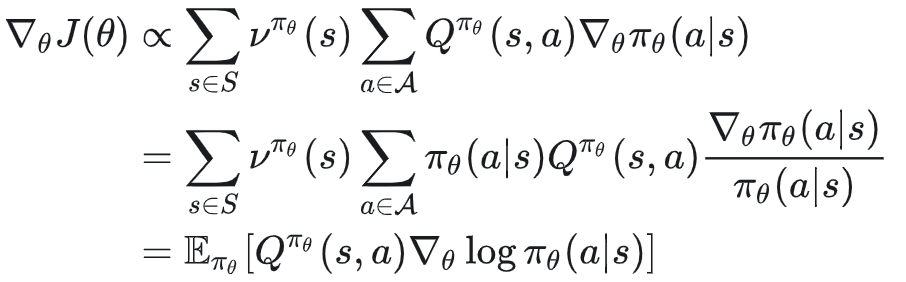
奖励值
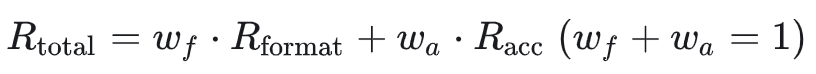
:模型输出格式是否正确(推理过程是否在<think>和</think>之间),二元奖励[0,1]
:模型输出的内容正确性,只有 为1时才会计算这部分奖励
由可以展开为三种
的三种奖励分别为:
1、Agent Trajectory Task Reward(轨迹任务奖励),该奖励又分为动作类型奖励和动作参数奖励;

R_type (动作类型奖励):动作类型是否正确,二元奖励[0,1]
R_param(动作参数奖励):要求动作类型和所有参数(比如点击的坐标、输入的文字)都必须完全正确,二元奖励[0,1]。
2、Grounding Task Rewards(定位任务奖励),该奖励又分为 point 奖励和Bounding Box奖励;
R_point (点定位奖励):预测动作区域是否在真实 grounding 中,二元奖励[0,1]
R_bbox (边界框奖励):计算预测的边界框与真实边界框的IoU(交并比)。如果IoU大于一个阈值(如0.7),则得1分;否则,得到一个按比例缩小的IoU分数。

3、其他奖励:用于视觉问答,多项选择题等辅助任务
Stage 2-1:子目标分解能力训练
这里作者创新性设计了一个子目标评估奖励函数:在训练过程中,针对每个 step,部署一个轻量级的 LLM来对分析目标模型输出的推理内容(在和之间的内容),并抽取推理内容中潜在的子目标,将抽取到的子目标与真实标注的子目标做对比,判断二者的语义相似度等级。 根据语义相似度将分值设置为 1-10 之间,如果轻量级 LLM 没有从推理内容中抽取到子任务则为 0 分。将最终的分值除 10 来归一化。
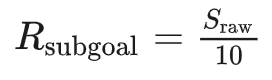
:抽取的子目标与真实标注子目标语义相似度;
:目标模型对于当前任务规划能力的奖励判断分值
为了应对目标模型具备了较好的子目标分解能力,但目标模型输出的动作参数错误而一棒子打死的情况(R_agent 中还没有子目标规划能力的奖励函数成分),因此需要对 R_agent 进行修改:
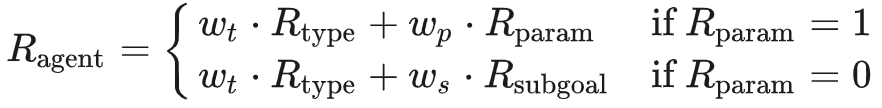
都是非负值参数
远低于 (优先保证模型生成动作内容正确性,规划能力优先级要低)
Stage2-2:错误恢复场景构建
首先需要识别出容易出错的 step,对于给定的 step,使用 base 模型(Qwen2.5-VL-3B-Instruct)用比较高的温度采样出 N的输出,计算出这个 N 个输出中正确结果的占比P_success(s),如果正确率占比大于 0,但小于 1,则代表对应这个 step目标模型是有能力正确输出结果的,将这个 step 标记成易出错 step。收集所有易出错 step 到一个集合中,使用易出错 step 来训练可以很好的提升模型纠错能力。
对于易出错集合中的 step 创建两种恢复场景:
错误逃离场景:执行错误动作后会的到一个错误的观察结果(截图),当错误结果保存到轨迹历史中后,再将历史输入给目标模型后,期望模型输出“escape”的逃离动作(如按返回按钮)。
回到正轨场景:目标模型执行逃离动作后回到了上一步的观察结果处(上一步页面),但历史记录中存在错误动作及错误动作执行后的观察状态,以及逃离动作,目标模型根据这些历史记录来进行反思,输出正确的 Action内容。
将上面两种场景增加到stage2 的 RL 训练中,可以有效提升目标模型的自我反思纠错能力。
3. 实验部分
实验细节
Base Model : Qwen2.5-VL-3B-Instruct
Stage2奖励函数:

训练数据:

训练参数:

实验结果
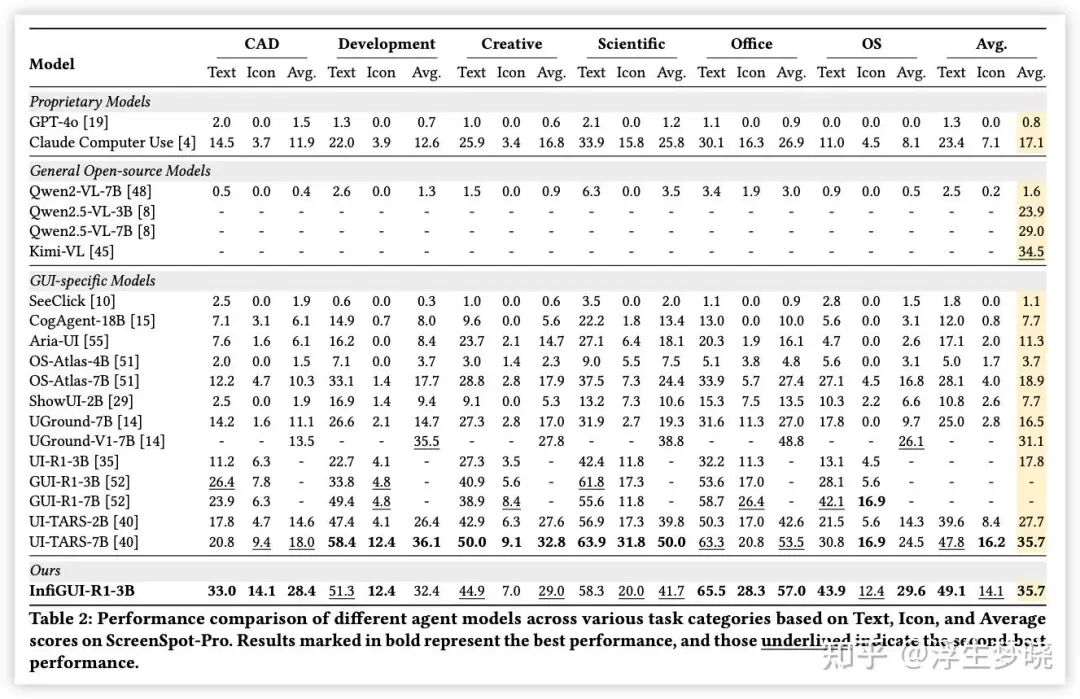
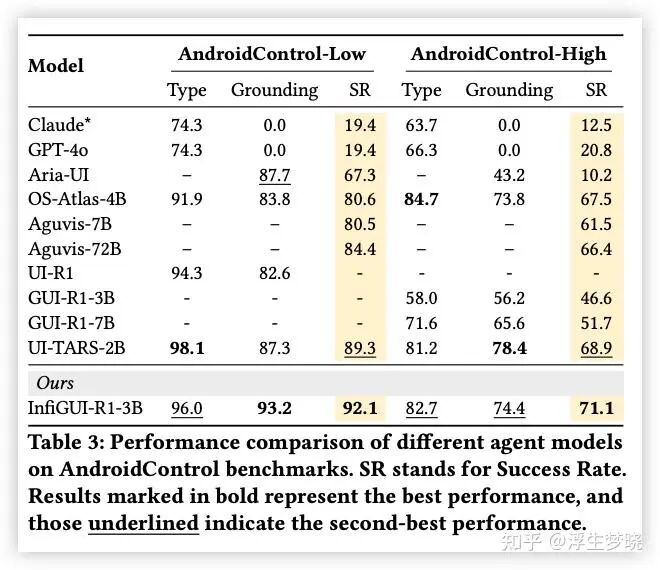
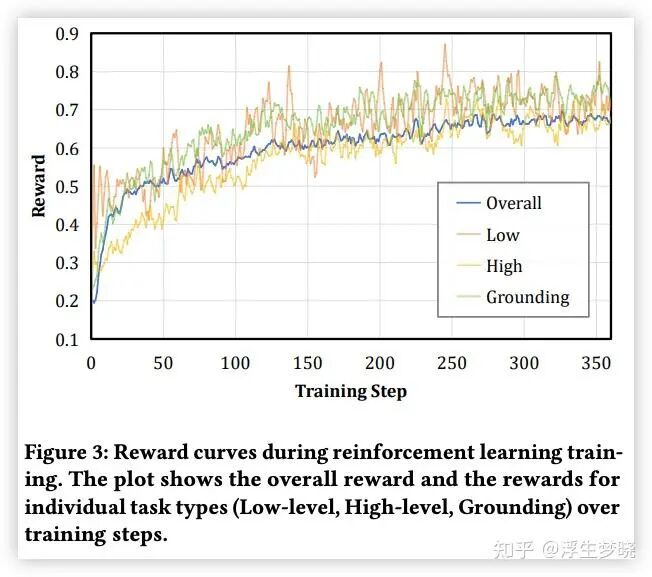
个人总结(仅代表个人观点):论文中绝大部分篇幅都在讨论其复杂层次的奖励函数的组成,对于 Stage2 中错误场景构建描述的很不清晰(场景是怎么构建的,基于真实环境还是虚拟机?如果采用实验部分描述的公开数据集做为训练数据又如何复现这些数据集中的轨迹?),本论文侧重为 GUI 任务上没有推理能力的目标模型增加上推理能力,但整体结构感觉很不完善。尤其是 RL 训练部分很模糊,只知道大概方案,是 offline 还是 online 训练都没有提到(错误场景构建来推断是 offline)。










