绑定手机号
确认绑定









作者:你好
地址:https://zhuanlan.zhihu.com/p/2003925669973878309
经授权发布,如需转载请联系原作者
TL;DR
我们提出了 Yunjue Agent,一个面向开放域任务的原地自进化智能体系统。与当前主流的”在新环境生成数据再训练”范式不同,我们认为真正的自进化应该是 In-Situ(原位自进化)——在推理过程中持续积累工具能力,无需外部监督。在 HLE、DeepSearchQA 等五个 benchmark 上,我们取得了 SOTA 或接近 SOTA 的成绩,并开源了完整的代码和trace。
01 引言
目前的智能体往往依赖人工写好的专用工具和固定流程:在熟悉任务里表现不错,但一旦进入开放世界,遇到信息噪声、目标变化、环境随机性或工具缺失,就很容易“卡住”。我们认为,通往 AGI 的关键不只是“能在很多领域用”,更重要的是在面对从未见过的新环境、新规则、新任务时,仍能自主进化学习——边做边吸收经验、沉淀通用能力,并在与环境的交互中持续提升,而不是靠人工补齐工具、改流程或额外训练来“续命”。为此,我们提出 In-Situ Self-Evolving 范式:让智能体在真实任务执行过程中,把过往经验持续“蒸馏”为可复用的通用知识,从而实现跨任务、跨领域的连续适应。为了落地这一范式,我们从智能体三大支柱——工作流(workflow)、记忆(memory)和工具(tool)出发做对比:workflow 更像“做事方法论”,在更精细的任务中提升规划与执行策略;memory 则像“经验库”,增强稳定性、抗遗忘与长期一致性;但在新环境里真正决定“能不能动起来”的往往是 tools——没有合适工具,再强的规划与记忆也会被功能边界锁死。基于此,我们首先以“工具自进化”为核心路径,构建了 Yunjue Agent,让智能体在任务中自动生成、优化并复用新工具,并将有效能力沉淀为可迁移的通用工具库。在五个多样化基准数据集上的实验显示,仅在零起步(zero-start)的条件下,Yunjue Agent 显著超越闭源商业基线;同时,冷启动阶段积累的通用知识具备收敛的趋势,并可无缝迁移到新领域。我们还提出一个类似“训练损失”的指标,用于监控测试时进化是否收敛。我们开源了所有实现细节,包括代码、系统轨迹与进化出的工具库等,推动更开放的自进化智能体研究。
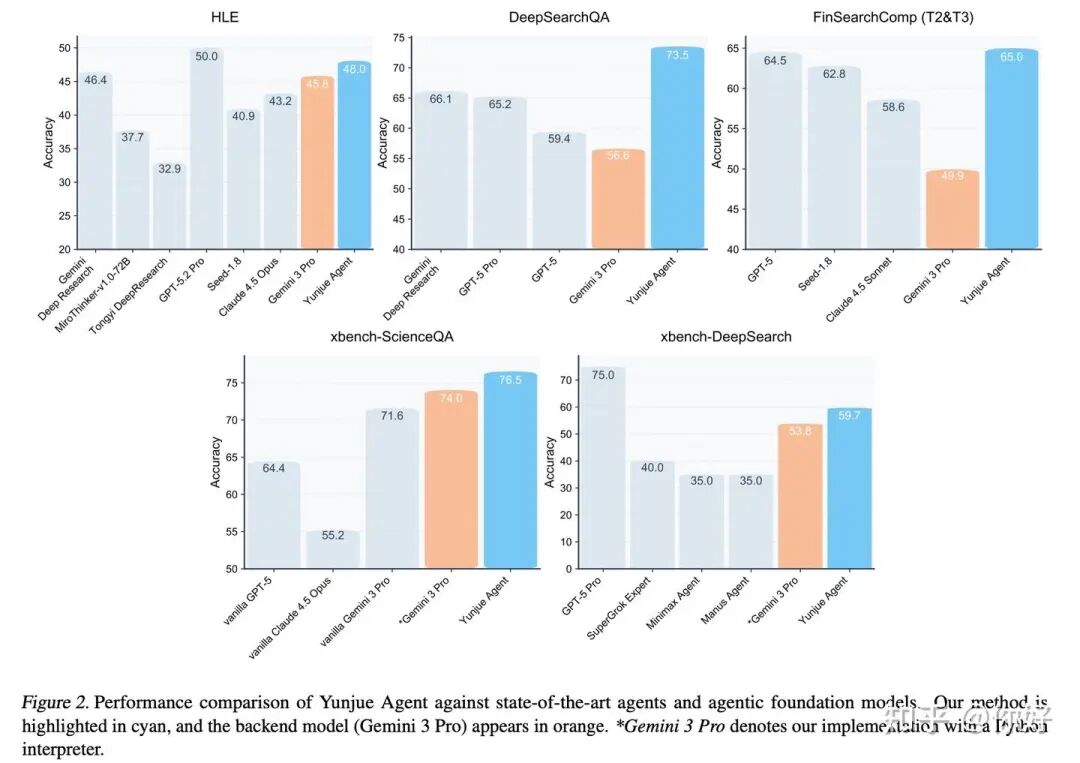
02 实验结果
该智能体在五个跨领域基准(HLE、DeepSearchQA、FinSearchComp、XBench ScienceQA 和 XBench DeepResearch)上均达到了当前最优或接近最优(SOTA)的性能。尤其是在需要复杂检索与推理的任务中,相比强大的基础模型(如 Gemini 3 Pro),性能提升最高可达十余个百分点。(可能是除了 Claude 外唯一一家报了 GPT-5.2 Pro 在 HLE 上 50 分的?OpenAI 把这个分数藏得太严实了……)
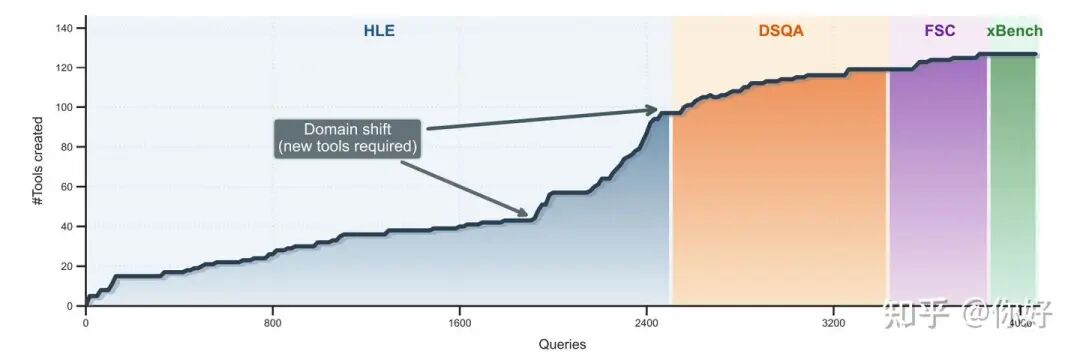
1. 工具收敛
为了验证自进化智能体所积累能力的跨领域迁移性,我们进一步设计了顺序式实验:首先在覆盖面广、规模较大的 HLE 数据集上“从零造工具”,随后将得到的工具库依次迁移到 DeepSearchQA,并继续用于金融与深度检索等更专业的任务。实验结果表明,这种“先打基础、再迁移”的策略不仅能够稳定保持性能,在部分数据集上甚至带来进一步提升。更重要的是,随着任务不断切换,新工具的生成数量迅速下降,工具集规模逐步趋于稳定。
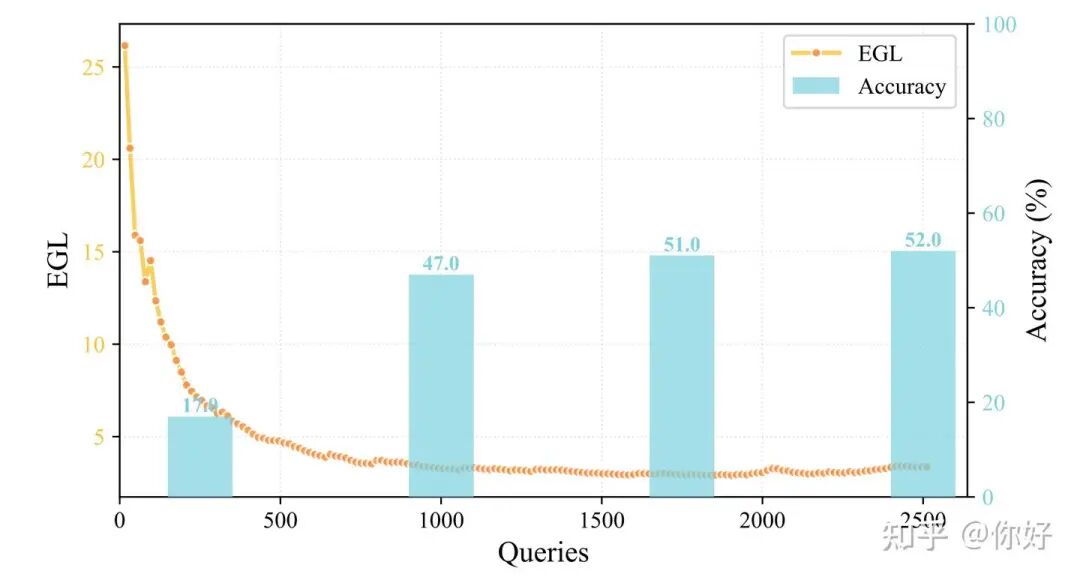
2. Evolutionary Generality Loss
为了衡量工具是否收敛,我们提出了一个新指标 Evolutionary Generality Loss (EGL):
EGL = 累计创建工具次数 / 累计工具调用次数
这个指标的计算非常直观:如果工具库趋于收敛,那么新增工具的速度会慢于工具调用的速度,EGL 就会下降。下面这张图展示了HLE上的EGL
关于更多的细节、实验以及分析,欢迎大家参考论文
https://arxiv.org/pdf/2601.18226arxiv.org/pdf/2601.18226
下面是我们真实开发的心路历程
03 起源
我们其实都想要一个越用越强的智能体,他不单单能做简单的问答,也能够处理各种开放域的任务,并且随着见过的开放域的任务也多,能力边界也在不断提升。这个东西确实比较让人激动,所以九月份的时候和老板们还有我的好大哥决定要做一个能处理开放域任务的,越用越强的自进化智能体。
彼时吴妈刚刚在云栖大会上提到“ASI一定会到达,并且此前的一个关键节点,就是AI能够自进化。“而我们也仅仅只有一个topic,于是就和好大哥一起对着这篇综述[1]开始看这块大伙都在研究什么。这综述量大管饱,内容很杂:从 Context、Tools、Workflow 各自如何进化,到它们进化的时机是什么、用什么信号作为进化的指标…
前前后后调研了一个月,读了不少论文,我们逐渐明确了几个点:
1. 开放域任务上的自我进化 —— 不能只在某个特定领域打转,当时不少讲自进化的论文还是在一个垂域做训练的,我们不想做垂域,而且我们没卡
2. 避免性能退化 —— 最好能做到真正意义上的能力单调不减,通常意义上的训练还是会引入别的领域上的性能退化的(TextGrad[2]这种大概率也会)
3. 可沉淀、可共享 —— 进化过程中产生的知识要能被复用
4. 可判断是否收敛 —— 希望能找到一个明确的信号来判断进化的程度
从这个角度看,我们能做的点就比较明确了,即专门做Tool的自进化
04 为什么做Tool
在当时我们的认知里,LLM Agent = LLM + Context + Workflow + Tool。自进化肯定要从这几个组件里选,那逐个来看这几个组件
1. 关于Context,当时看的很多和Memory 管理的论文感觉 trick 太多,而TextGrad 这类自动 prompt 优化感觉过于学术玩具,并且很难保证prompt在一个领域调整之后不会在另一个领域上掉点
2. 关于Workflow,我们当时觉得Workflow的核心节点就是 Planner 和 Worker,针对 IMO 这类强推理任务可能再加个 Evaluator。所以觉得静态 workflow 已经够用了,而且 AFlow[3] 这类自动生成 workflow 的研究已经很多
3. 关于Tool,我们觉得Tool天生有明确的可评价的标准,即能正常调用的工具肯定比内部有错误的工具更好,并且直觉上讲工具池越大,agent 能力边界越大,更重要的是,我们觉得针对开放域任务,tool决定了agent的能力下限,并且在开放域任务上天然容易出现一些交互能力的缺失,即有些任务(比如网络搜索),如果没有相应的tool,不管你的memory和workflow怎么进化,他都是完成不了的。
所以我们选择tool的最核心的原因还是面对开放域的问题,反馈信号往往很弱或者是缺失的,而tool的特性决定了他天生是具备比Context和Workflow更明确的反馈信号的。
当然,自己造Tool这件事情其实也有很多论文已经做了,比如Voyager[4]是在我的世界里自己造工具,而Alita[5] / Alita-G[6]是自己造 tool 去做 GAIA 等benchmark。而我们的差异点主要是在处理更强的开放域任务上做的更极致,并且做到了工具库的收敛和可观测指标。
05 杂糅得到的一个初版系统
在明确了以自己造Tool为核心之后,我们当时选择把有的一些技术全都揉进去,但是以自己造Tool和Tool收敛为核心,看看效果怎么样,大概长下面这样

初版系统,大杂烩
但做完之后找了十几道题测了一下,发现了一些很严重的问题
1. 过度思考: 本身planner就会把一个任务拆成若干步,然后针对每一步,agent builder生成的system prompt又会把它拆成更详细的小步骤,这里面其实有非常严重的过度思考,GPT-5在这一点上最严重,他除了正常做题,在做完题之后还会尝试去进行交叉验证,如果交叉验证本身因为一些原因(比如anti-bot)失败了,这个任务也就失败了,并且这样会消耗非常大量的token,而且任务耗时很长。
2. 单测没用: 造工具的时候,生成的测试似乎没有特别大的用处,生成的测试绝大多数时候都能通过(可能因为我们用的tool builder模型比较牛),但是通过了也不代表这个工具没有问题,而这个过程本身是当时系统里的一个单点,耗时比较长
3. Worker 脑裂: 让worker自己决定是否需要一个新工具,这个事情导致我们的系统执行时间很长,并且直觉上讲,既让他做题,又让他判断当前工具是否够用,有点容易让他脑裂。
4. 串行太慢: 因为我们想强调的是工具的复用,所以我们是串行的让他一道题一道题做的,这样的问题也是实在是太慢了
06 逐渐迭代彻底收敛到自己造工具
主要考虑时间和token开销的优化,我们做了下面这些改进
1. 干掉了所有向量数据库,将重心完全收敛到tool
2. 干掉agent pool,感觉没啥用处,并且他生成的system prompt里的一条一条的步骤反而限制了worker执行时候的自主性,并且增加一个新的节点,要调整的工作量有点大
3. 造工具的时候,不再生成测试,而是直接让worker去用这个工具,如果调用会出错就在线生成增强这个工具。
4. 为了让效率更高,同时让worker仅仅只专注于完成任务,我们把判断是否需要新工具这个功能移到了worker的前置节点manager上,一方面在manager可以直接提前并行把所有工具都造好,另外manager也可以选工具,避免worker配的工具太多导致上下文太长,另一方面也是当时有想增加一个针对worker的response进行evaluate的功能(主要针对HLE),这个evaluate在manager做感觉挺合适的(事实上这个设计后面引入了更多的问题)
5. 参考模型训练里的batch,我们这里也增加了batch的设计,最早只是为了效率更高做的,即batch内并行,batch间串行
这会看起来其实和我们最终发的系统已经非常像了,但是我们小规模测了一下,但效果其实也不是很理想,出问题的原因主要有两个:
一方面,planner这个节点在模型能力足够强的时候似乎并没有明显的收益,我们做任务拆解的时候发现planer不可避免的会有一些信息丢失,甚至step之间还可能有逻辑断层,让每个step的worker看到什么,有点难取舍,并且当时绝大多数旗舰模型(比如gpt-5),他们拆解出来的计划都很固定,即第一步完成任务,第二步确定任务完成对了,第三步交付答案,显得非常头重脚轻。并且当时kimi k2 thinking[7]的blog里,单纯通过重复的工具调用就拿到了一个比较好的分数。而且planner这个东西的问题在于他在拆解的时候是完全不知道外部环境怎么样的,这种时候加replan可能是一个好选择,但是我们觉得还是需要一些工程量,所以最后决定直接把planner干掉。
另一方面,manager和worker之间存在一个gap,最早我们发现manager给worker选的工具worker总是不喜欢用,并且manager并不知道在真实执行的时候worker遭遇了什么困难,并不能给worker造出面对这些困难时候的新工具。解决方案其实也比较直接,就是让manager生成一个tool usage guidance,告诉worker在他眼中这些tool都是干什么用的(没直接生成一个tool use的plan的原因还是我们觉得应该给旗舰模型最大的自由),然后worker在发现任务完不成的时候一般会直接摆烂不干,基于此我们引入了一个新的节点,来对worker的执行轨迹进行总结,判断他是否需要新的能力来完成这个任务,将这个反馈给manager。
至此,就基本已经到了论文里的那个版本

07 一些工程问题
做Agent其实最大的阻碍在API上,国内提供国外模型中转服务的API供应商大多都是草台班子(某家公司的服务器在我选型压测的时候甚至被我的mac打爆了。。),好几周充满了项目要黄的压抑感....
最后用了一些抽象方法解决了API和网络的问题,包括但不限于
1. 多采购几家API中转商(真的是草台班子),做了一个llm请求的混池
2. 在国内服务器跑的时候,到这几家API中转商的请求似乎都不是很稳定(他们都喜欢把服务器放到美国),并且很多网络搜索的题需要挂代理。最后选择直接租美国服务器,享受到了难得的网速。
3. 经常出现llm请求一直不回来的情况,设置langgraph的timeout也不管用,只好自己在外面封装一个类去控制timeout
4. Gemini的API经常返回None,中转商的意思是这是内容被审核了导致直接被吞了(不应该至少给我返回一个错误码么???),为了避免这种情况,在react agent里,增加了roll back,即如果返回了None,就返回到前一次AIMessage的生成,让他重新生成
08 一些调prompt的心得
我们主要用了GPT-5系列,Gemini-3系列,Claude 4.5的几个模型以及几家国产模型,主观感受如下
模型 | 体验 |
|---|---|
GPT-5 | 指令跟随最强。后续的 GPT-5.1/5.2 都稍微有点抽象。如果输出抽象,大概率是 prompt 和上下文的问题 |
Gemini-3-Pro | 号称 2M 上下文简直是在扯淡,上下文变长之后几乎没有指令跟随能力,output format 也差。但智力水平真的明显高出一大截。多模态能力是真的强,GAIA 里有一道视觉题(黑底图片识别红绿数字),当时只有他和flash能做对,其他全是红绿色盲 |
Gemini-3-Flash | 感觉没有工具调用能力 |
Claude 系列 | 整体感觉介于 GPT 和 Gemini 之间,存在一定 function call 的幻觉(调用了不存在的工具),可能他家是写代码比较强 |
Kimi K2 Thinking | 做 plan 的时候直接吐了 function call 的 special token……只能说确实不适合我们的任务 |
MiniMax M2 | 和 Kimi 差不多 |
09 总结
我们提出了Yunjue Agent,一个面向开放域任务的原地自进化智能体系统。与当前主流的”在新环境生成数据再训练”范式不同,我们认为真正的自进化应该是 In-Situ(原位自进化)——在推理过程中持续积累工具能力,无需外部监督。在 HLE、DeepSearchQA 等五个 benchmark 上,我们取得了 SOTA 或接近 SOTA 的成绩,并开源了完整的代码和trace(应该是第一个开源trace的?)。
https://github.com/YunjueTech/Yunjue-Agentgithub.com/YunjueTech/Yunjue-Agent
Reference
[1] Gao, Huan-ang, et al. "A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to Artificial Super Intelligence."arXiv preprint arXiv:2507.21046(2025).
[2] Yuksekgonul, Mert, et al. "Textgrad: Automatic" differentiation" via text."arXiv preprint arXiv:2406.07496(2024).
[3] Zhang, Jiayi, et al. "Aflow: Automating agentic workflow generation."arXiv preprint arXiv:2410.10762(2024).
[4] Wang, Guanzhi, et al. "Voyager: An open-ended embodied agent with large language models."arXiv preprint arXiv:2305.16291(2023).
[5] Gao, Huan-ang, et al. "A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to Artificial Super Intelligence."arXiv preprint arXiv:2507.21046(2025).
[6] Qiu, Jiahao, et al. "Alita-G: Self-Evolving Generative Agent for Agent Generation."arXiv preprint arXiv:2510.23601(2025).
[7] Kimi K2 Thinking










