绑定手机号
确认绑定









作者:Zhihong Deng
地址:
https://zhuanlan.zhihu.com/p/1981013725080227910
经授权发布,如需转载请联系原作者

过去一年来, o1和DeepSeek-R1 的神话,结合媒体的宣传,让 RL 特别像武侠小说里的绝世功法:给个 reward,堆上算力,模型自己就能学会全新的技能。但真正做过LLM RL后,就会发现它更像是“熟能生巧”的提效手段(exploitation),而不是真的从有限的反馈信号里学出新的东西(exploration)。预训练在解锁各种能力的同时,也给 RL 画了一道看不见的牢笼。大部分“探索”只能在这个牢笼里打转,没有传统RL里从环境中学习的那股灵气。
大家争论RLVR也蛮长时间了,NeurIPS 2025 这篇Runner-up就是说,既然大家都说 RL 能拓展推理能力边界,那我们就认真来测一下在现在这套 RLVR 设置下,它到底有没有做到这点?作者通过 pass@K 曲线、覆盖率和困惑度分析很好地回应了这个问题。整个验证的思路很扎实,借这篇博客记录一下:
1. 如何测量推理边界?
2. 哪些证据说明了目前的RLVR没有获取新的能力?
3. What's next?
01 pass@1 看临场表现,pass@k 看能力上限
要理解这篇论文的全部实验,核心就是弄明白一件事:为什么我们这么在意 大k的 pass@k。
1. pass@k 是什么?
简单来讲:
pass@1:一题只给你一次生成机会,看你能做对几道,这就是我们平时最常看的指标;
pass@k:一题给你 k 次重试机会,只要有一次生成了正确答案,就算这题“在能力范围内”。
论文里做了一件很多 benchmark 和论文评估没有做的事情,不仅看了 k=1,还看了一整条 k 从 1 提到 128、256 甚至 1024 的 pass@k 曲线。那么大k就意味着给足够多的机会,你到底会多少题,通过这种方式来刻画出一个模式在推理能力上的边界。
2. 为什么这比单看 pass@1靠谱?
单看 pass@1 耦合了“模型会不会” 和 “运气(有没有采到)”这两个因素。那用它评估一个模型的时候就会忽略了模型的长尾能力,就是一些理论上模型可以解但得到多试几把才能解出的问题。
这篇论文的思路就是,我们可以把 pass@1 和大 k 的 pass@k 分开看。把基座模型在大 k 下的 pass@k,当成它的理论上限,那么前面那个能不能拓展推理能力边界的模糊问题就转换为了一个可量化的问题:
RLVR 模型在 pass@1 上是比 base 高,但给了足够多的抽样次数,它在大 k 下的 pass@k 是不是也更高?
如果答案是不能,那RL 很可能只是帮你压缩了搜索空间,并没有让模型真正学会更多。
当然,我们肯定会想“pass@k 有可能就是瞎蒙对的,不是真的会呢?”作者是这么回应这个问题的:
code 和 math答案空间巨大、靠瞎猜不太可能蒙对,比如编程题要全测例通过、复杂表达式要完全匹配;
在 GSM8K、AIME 这类题上,人工检查那些只有在大 k 时被 solve 的题对应的 CoT,确保真的是有完整推理,而不是最后一步胡写个答案刚好撞上。
02 小 k RL 吊打 base,大 k 结论反转
1. 数学:GSM8K / MATH / AIME
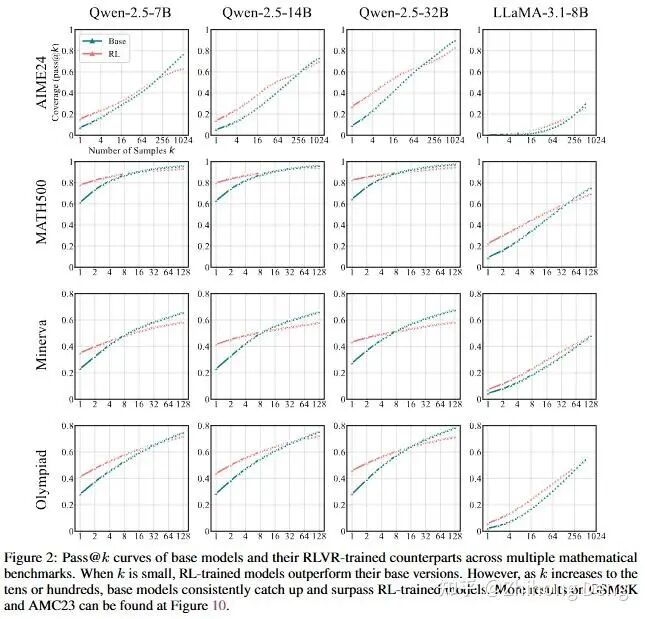
作者在好几个数学 benchmark 上都跑了同一套对比:
Base:Qwen2.5(不同尺寸)、LLaMA-3.1-8B 等;
RL:用 SimpleRL-Zoo 提供的算法在这些基座上直接 zero-RL 出来的版本。
几乎所有图都是一样的形状:
k 很小(1、2、4)时:RL 曲线明显比 base 高——也就是RL平均一发命中的能力更强;
随着 k 拉到几十、上百:在某个点之后,base 的 pass@k 开始超过 RL;
这就是说,如果你肯给 base 足够多的出手机会,它在最终能做对多少道题这件事上反而更强。这点在难度比较高的基准(比如 AIME、竞赛类数据)上尤为明显,到了 k=256 或 1024 的时候,base 能多解出一批 RL 永远解不出的题。
2. 代码:LiveCodeBench / HumanEval+ / MBPP+
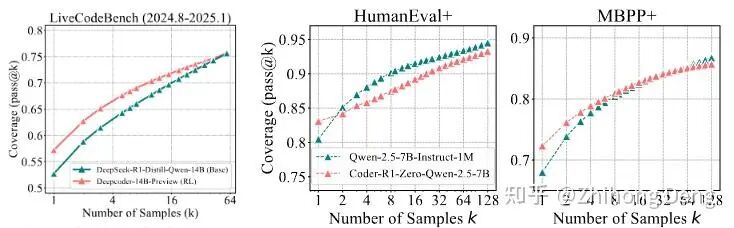
代码这一块测了:
CodeR1-Zero-Qwen2.5-7B:在 Qwen-2.5-7B-Instruct-1M 上做 zero-RL;
DeepCoder-14B:基于 DeepSeek-R1-distill 的 RL 模型;
结果跟数学几乎是一模一样的 pattern:
小 k:RL 模型 pass@k 明显更高;
大 k(比如 64、128):base 曲线逐渐追平甚至超过 RL。
如果说数学还有一点瞎蒙的可能,这个实验就更有说服力了,乱写一堆代码正好所有测例全过的概率确实低到可以忽略。
3. 视觉推理:MathVista-TestMini / MathVision-TestMini
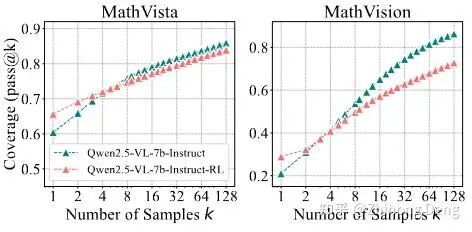
作者还拿 Qwen2.5-VL-7B 做了视觉推理上的 RL 实验,用 EasyR1 框架在 Geometry3K 上训练(看几何图、解数学题),结果也是一致的:
RL 模型在 k=1 的表现更好一些;
但当你拉大 k,base 模型终会反超。
这说明:RLVR 的这个特点不是纯文本任务的特例,而是存在于更普遍的推理任务上。小结一下,这里并非RL模型的能力,在 pass@1 这种用户指标上RL模型确实更强,但要说它们在推理能力上比基座高出一截,这篇论文给出的证据是:并没有。
03 RL模型的能力边界
论文里这个部分很有意思,把前面pass@k的分析又再深挖了一层,安利阅读原文。
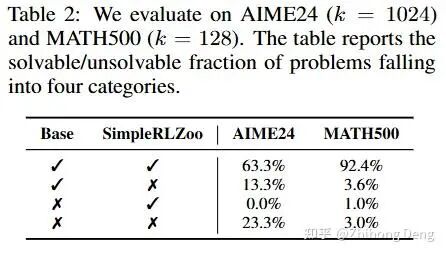
1. Base 的 solvable set 更大
想象每个模型在某个 k 下都有一个solvable set:至少有一次解对的问题集合。当 k 很大时,我们可以用这个集合近似“模型理论上能解的所有题”。作者把 base 和 RL 的 solvable set 做了个对比,结论可以一句话概括Base 的 solvable set 近似包含 RL 的 solvable set。换句话说:存在不少题,base 多抽几次能解出,但RL后反而解不出。
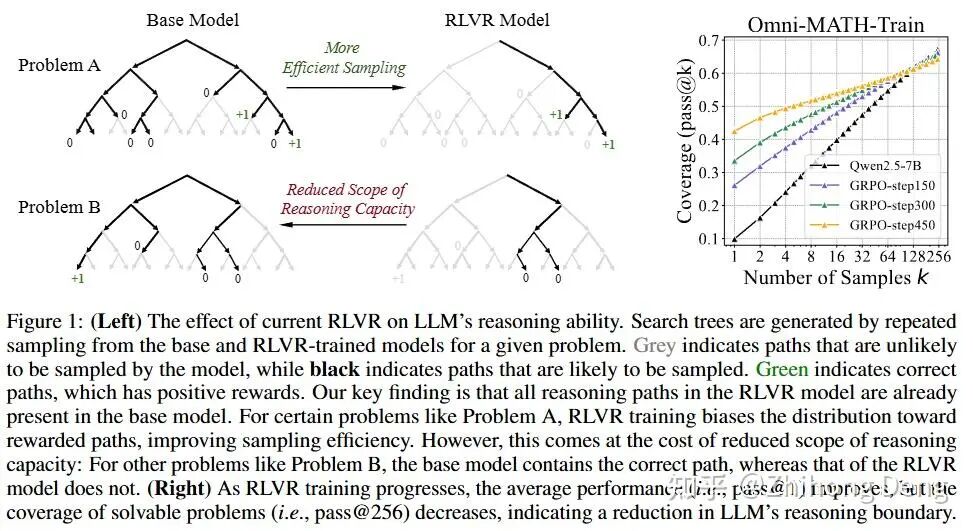
可以用图 1 里的搜索树来解释,对于某些题(Problem B):
base 的搜索树里有一条绿的正确路径;
RL 的搜索树里那条路径已经看不到了——概率被压低到几乎采不到的地步,推理能力的边界反而缩小了。
2. 困惑度分析:RL 的解原本就在 base 的高概率区
另一个很有意思的分析是:把 RL 模型生成的“成功 CoT”,拿去喂 base 模型,看它们在 base 下的 log-prob 是多少如果 RL 真的学会了新技能,那我们就会看到:这些 CoT 在 base 下应该是极端低概率,甚至几乎不可能出现的。
实测下来:RL 的成功路径在 base 模型下往往有不低的概率,并非极端事件;
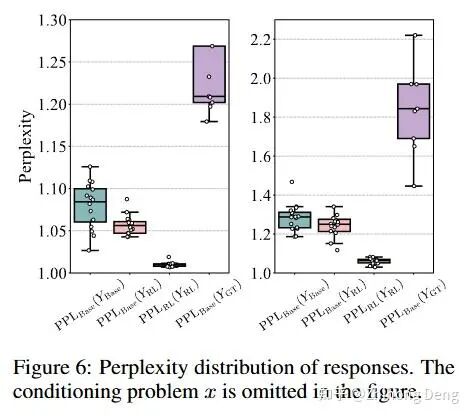
也就是说:RL 会的解法确实就藏在了 base模型的分布里。
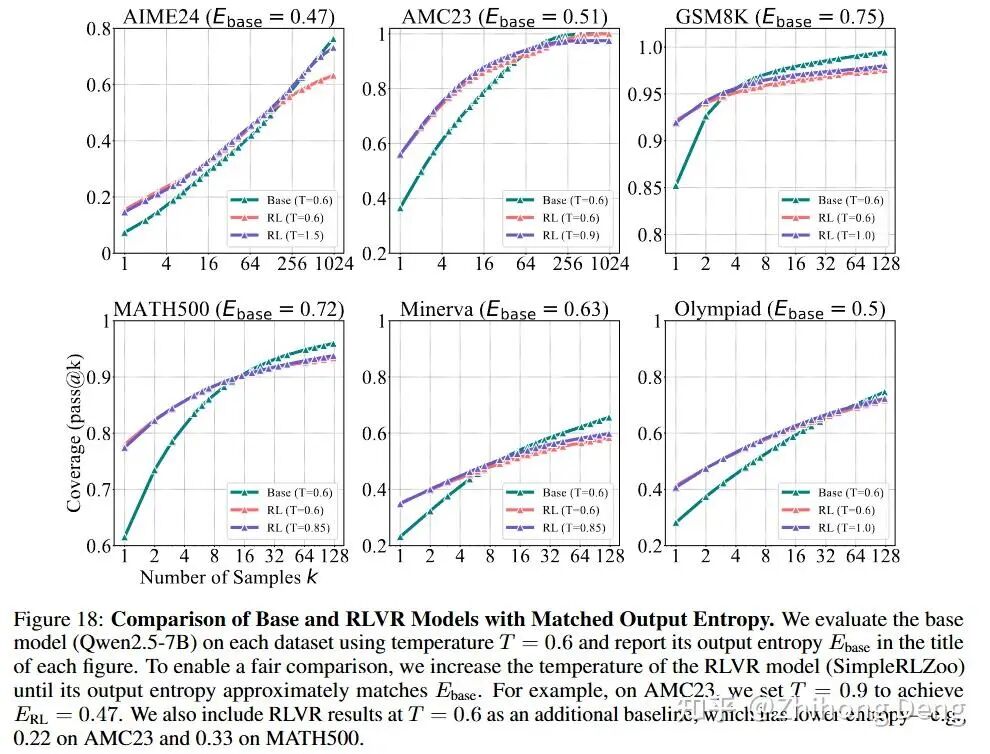
3. 熵变小是表象:把温度调回去也救不回来
我们看 RL 训练的过程常常会检查entropy,随着RL 训练,策略逐渐收敛,熵就会越来越小,这个其实在绝大部分RLVR的训练过程中都很常见。那如果我们采样时把温度调高一些,让RL模型的输出更diverse一些,结论会不会有变化呢?作者也做了这么一个实验,结果时:
熵确实上来了,输出更发散了;
但更高的 temperature 下,RL模型在大 k 的 pass@k 上还是明显落后于 base。
04 蒸馏 vs RL:谁真的在“拓展边界”?
看过R1论文的话,应该会对文中关于小模型走蒸馏比zero RL的效果更好。现在想来,这是埋了个伏笔。这里说的蒸馏并不是传统蒸馏,而是指用老师模型生成一堆推理轨迹,然后让学生模型直接SFT。作者也对比了蒸馏和RL模型的区别,同样用 pass@k 评估,看学生模型在大 k 的表现和 base 比,到底有没有扩展 solvable set。

结果挺有意思:
蒸馏出来的学生模型,在大 k 的 pass@k 上确实能超过 base 一截;
重要的是:它解出了一批 base 模型完全不会的问题——也就是说,学生的 solvable set 真的在往外扩。
理解起来倒也直观,很多时候想问题就是容易被自己的思想牢笼困住,需要一点“外力”(蒸馏别人的思路)打破,缺乏外力的情况下可能就只会一直钻牛角尖。
05 为什么 RLVR 会被“先验”锁死?
如果你之前也做过传统 RL,很容易有个疑问:明明 RL 在环境里能自己摸索出新套路,怎么到了 LLM 上就变成一个采样器了?论文在 Discussion 里讲了两点,我非常认可。
1. 两个关键差异:动作空间太大 + 预训练先验太强
差异一:动作空间的数量级不是一个维度的东西。
传统RL,特别是像Atari和Go这样的环境:
动作空间有限(几个操作 / 上下左右落子),
状态空间虽然很大,但每一步的决策分支是有限且可控的。
LLM:
每个时间步是几万 vocab 的离散决策;
序列长度上百上千,组合空间直接指数爆炸。
在这么大的动作空间里,如果你从随机策略开始学,几乎是不可能靠 0/1 reward 把梯度传回来,这也是为什么大家都会从一个强 base 开始做 RLVR。
这里我认为还有一个隐含的点是:传统RL里,当你的动作空间有限时,你的每一步即便走错,只要这个错的动作被惩罚得足够多,那对的动作的概率就自然而然地浮上来了。但是在LLM RL中,动作空间实在太大了,稀疏奖励并不能让那些正确的解法自然而然地浮出,这是个更难的topic。
差异二:RLVR 不是从 0 开始,而是从一个“超强先验”开始。
传统 RL 大多是在白纸上画画,一开始啥都不会,慢慢靠 reward signal 探索出来(咱先不说offlien-to-online RL以及sim-to-real)。
RLVR 则是在一本已经写满字的书上涂改。base 模型已经有非常强的语言和推理先验,任何输出都在这个先验的强约束下。
这个设定一方面使得LLM RL可行,不至于因为动作空间太大直接挂掉; 另一方面也筑起了一道看不见的围墙。几乎所有的探索,都局限在 base 先验的“高概率区”里。所谓成也先验,败也先验,能理解为什么sutton老爷子为什么对这条路子这么悲观。
2. Policy gradient 在这种设定下,会天然“保守化”
简单来说,PG对 reward=1 的样本,提升 log-prob;对 reward=0 的样本,降低 log-prob。放在 RLVR 的场景里,它的效果变为:
在 base 分布里本来就有一定概率的 CoT,有机会偶尔拿到 reward=1;
那些远离 base 分布的“探索”:大概率 reward=0,梯度会一直往回推。长期下来,policy 被强行往“原有高密度区域”挤压,越训越保守。
所以训练到最后,policy 会自然收缩到:在 base 已经比较擅长的那几种解法上更极端,在其它潜在也能解题的路径上则越来越吝啬。
把前面看到的所有现象拼在一起,RLVR目前的缺陷就很清晰了:RL 抬高了 pass@1,模型会更偏好走那几条常规成功路径;同时也缩小了 solvable set,那些原本在 base 分布里偶尔能采到的、不那么“常规”的正确路径被渐渐压没了。
06 写在最后
与其说这篇论文给RLVR判死刑,其实更准确来说是现在这一套“0/1 RLVR + 基座先验 + policy gradient”的玩法还没有充分释放出RL的潜力。作者也列了些未来方向,最后结合自己的看法简单聊两句:
1. 过程奖励
不要只用 0/1,对中间推理过程打过程奖励,让模型即便没完全做对,也能从部分合理的中间步骤里学东西。这个方向肯定是可以做的,在RLVR火起来之前其实就有人在探索了,但是怎么造过程奖励是最大的问题。现在很多multi-turn RL的探索,包括agentic RL,都在往这个方向发展。要做到token粒度的reward assignment很难,但是中间每个子任务有没有做好,还是好评价的。
2. 价值网络
用 value function 做 credit assignment,而不是单纯靠 policy gradient。这个方向的难度也很高,整个25年下来感觉除了seed好像还没看到哪家大厂有脱离critic-free的,期待26年看到一些好的工作学习一波。
3. 环境与 curriculum
不在一个固定的小题库上做 RL,而是在更大、更动态的环境里,让模型体验“从简单到困难”的梯度。这是一直想做,但是还没有做的,我个人也比较看好这个方向。毕竟,没有环境,谈什么RL呢 :)
4. 探索机制
不要仅仅靠 token-level 的随机采样,而是引入更结构化的 search / program-level move。这也是个好方向,有点robotic里面hierarchical RL那种味道了,80/20那种reflection token的探索粒度还是太细了。
5. 多轮 agent 框架
跳出“一轮生成 + 一次 Verifier”的模式,让模型像 agent 一样在环境里来回试错和修正。同上~一个道理。
下一代 RL 范式会长什么样?我不太确定,但有一点可以肯定:真正有用的 RL 工作不会再出现在单模型、单回合、单 reward的 toy 设定里,而是会往环境 + 多轮交互靠。那时候我们可能才有资格说:
“嘿,RL 让大模型学会了人类没教过的东西。”
在那之前,这篇Limit of RLVR 先给 RL 降降温,也挺好。










