绑定手机号
确认绑定









作者:赵晨阳,SGLang RL Lead
地址:https://zhuanlan.zhihu.com/p/1999486437280745217
经授权发布,如需转载请联系原作者
TL;DR
我们在 slime 上实现了 LLM 与 VLM 训练范式的统一。得益于优秀的解耦设计,开发者现在只需编写一套定制化的 rollout 函数,即可像训练 LLM 一样,轻松开启 VLM 的多轮强化学习(Agentic Multi-turn RL)
近期,SGLang RL 团队在强化学习的训练稳定性,训练效率与适用场景方面取得了重要进展,具体包括:
INT4 QAT 全流程训练:我们实现了从训练到推理的完整 QAT INT4 闭环的方案,并提供了详细的技术方案,显著提升了 Rollout 的效率与稳定性。
Unified multi-turn VLM/LLM 多轮采样范式:我们提供了 VLM 多轮采样范式的实现 blog,开发者只需编写一套定制化的 rollout 函数,即可像训练 LLM 一样,轻松开启 VLM 的多轮强化学习。
Rollout Router Replay:我们实现了 Rollout Router Replay 机制,显著提升了 MoE 模型在 RL 训练过程中的稳定性。
FP8 全流程训练:我们在 RL 场景中成功实现了 全流程 FP8 训练与采样,进一步释放了硬件性能。
投机采样:我们在 RL 场景中成功实践了 投机采样,实现了大规模训练的无损加速。
在此基础上,我们进一步分享将 VLM 与 LLM multi-turn RL 训练范式统一的设计,希望为社区提供一个符合第一性原理的 multi-turn RL 解决方案。
感谢 SGLang RL 团队,Amazon AGI SF Lab 与 slime 社区的贡献者们,由衷感谢 Verda Cloud 为本工作提供的计算资源。
01 Introduction
与传统的单次执行(Single-turn Inference)不同,Agentic VLM 的本质是连续交互。它不再是端到端地吐出一个“最终答案”,而是作为决策核心,在执行动作(Action)与感知环境(Observation)的往复循环中不断演进。每一次模型的输出都会对环境进行一次试探,而环境每一轮反馈又是为模型下一次采取行动提供更进一步的信息。这种与环境的多轮交互,是目前充满期待的 VLM 进化为真正智能体的必经之路。
例如大火的 Computer Use Agent 或具身智能场景下,模型不是一个孤立的对话机器人(chatbot),而是深嵌在环境链路中的思维引擎(thinking machine)。模型必须具备“审时度势”的能力:输出 Action 引起环境的状态变更(UI 状态、物理位移等),实时捕获环境以图片等丰富形式返回的 Observation,并在长上下文的持续滚动中完成复杂的推理。
这正是 slime 协同 Miles 社区在 VLM Agentic Training 中致力攻克的核心场景。得益于其在 LLM Multi-turn Training 阶段就完成的优雅设计,用户仅需通过 --rollout-function-path 参数,即可传入为 VLM Agent 设计的交互逻辑,无缝衔接“自主生成 → 环境交互 → 多模态观测回传 → 迭代推理”的完整链路。我们保持对 Agentic Multi-Turn RL 一贯的设计哲学:极致解耦,Rollout 逻辑不与任何特定数据集格式或交互协议强绑定,“环境如何解析 Action、如何执行工具、如何反馈 Observation”完全由用户自由决定,为 Agent 的无限演进保留绝对的自由。
02 核心设计
正如我们反复强调的那样,从第一性原理出发,任何 multi-turn 训练本质上只需要定义采样与交互逻辑即可。
具体来说,slime 的 LLM Multi-Turn Training(e.g. Search-R1 )通过自定义采样(generate 函数),让模型在每一轮根据当前上下文生成动作指令,实时捕获环境观测(Observation)并将其增量注入上下文,直至模型决定返回结论或者超出上下文限制长度。得到完整的 trajectory 后,再通过正确的 loss mask 来区分模型输出的动作指令与环境反馈信息。
VLM 与 LLM 的多轮采样并无本质区别,只需要在在每一轮交互中额外维护并拼接多模态的上下文信息。我们将 environment 与 rollout 明确解耦,“环境如何解析 Action”等等设计完全独立于采样与训练之外,提升了可复用性与可扩展性。
03 多轮交互迭代逻辑
1. 初始化任务:从 Sample 提取 prompt 和多模态输入,完成首轮编码并初始化 sample.tokens, image_data, multimodal_train_inputs_buffer 等等,为后续的多轮循环提供初始化的上下文。
2. 模型生成:产生本回合执行的动作,追加到上下文,且将 loss mask 对应 position 设置为 1。
3. 环境接受动作影响:把模型输出传递给 env,env 返回 observation (可能含多模态内容)。
4. 追加 observation 到上下文:将 observation 编码成下一回合的输入。
获取干净的 prompt_ids(详见工程附录 ) ,追加到上下文,且将 loss_mask 对应的position 设置为 0。
在 VLM 场景里,observation 可能带新的多模态内容,因此需要同时维护多轮多模态数据的拼接;具体来说,这里需要维护两条链路:
rollout 的 image_data:每轮把新图片 encode 后 append。
训练侧的 multimodal_train_inputs:每轮 processor 产生的张量需要合并。
5. 终止条件:由如下各种限制条件共同决定。
max_turn: 最多执行 max_turns 轮交互,达到上限后无论任务是否完成都将被迫停止。
token budget: 为避免采样长度过长,我们维护了一个可用 token 的预算,每次模型生成或追加 observation 都会消耗预算,一旦预算耗尽就提前停止并标记为截断(TRUNCATED),确保不会超过最大上下文或最大生成限制。
env done: 环境在 env.step() 中返回 done=True,表示任务已完成或无法继续(例如已得到最终判定、进入终止状态等),rollout 立即停止,不再追加后续轮次。
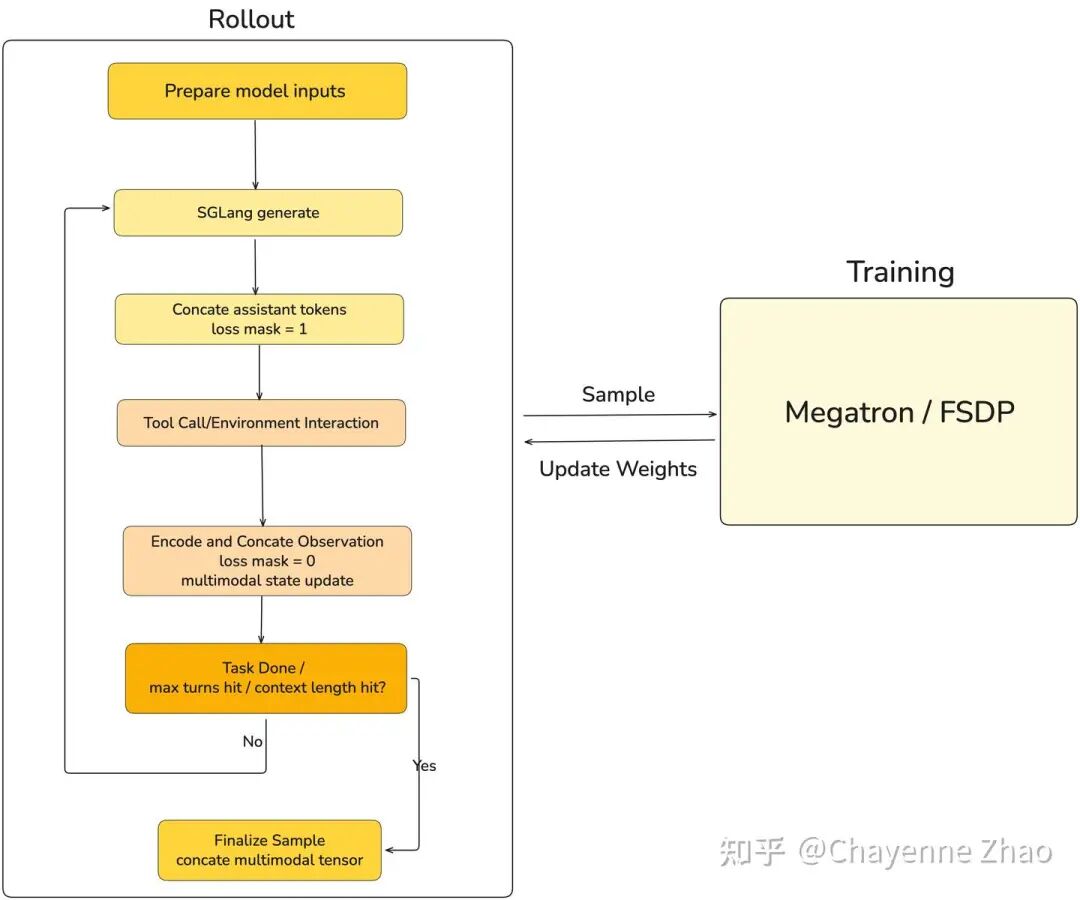
# Pseudocode: custom multi-turn rollout.generate
async def generate(args, sample, sampling_params):
# 0) Init: load custom variable like envrionment path and max_turn
env = load_env_module(args.rollout_interaction_env_path).build_env(sample=sample, args=args)
max_turns = args.max_turns # injected via --custom-config-path (YAML) :contentReference[oaicite:0]{index=0}
# 1) Encode initial prompt and multimodal inputs
sample.tokens, image_data, mm_train_buffer = init_from_prompt(sample, state)
# 2) Turn loop: actor -> env -> append observation -> repeat
for _ in range(max_turns):
# (a) Actor generation (assistant tokens)
response_text, new_tokens, new_logprobs, finish_reason = sglang_generate(
url=url, input_ids=sample.tokens, sampling_params=sampling_params, image_data=image_data
)
append(sample, new_tokens, new_logprobs, loss_mask_val=1)
# (b) Env step (returns next observation; may include multimodal payload)
observation, done, _ = env.step(response_text)
if done:
break
# (c) Process and append observation tokens
user_msg = env.format_observation(observation)
obs_ids, obs_image_data, obs_mm_inputs, obs_mm_train = encode_observation_delta(
user_msg, tokenizer=state.tokenizer, processor=state.processor, tools=sample.metadata.get("tools")
)
append(sample, obs_ids, [0.0] * len(obs_ids), loss_mask_val=0)
# (d) Multimodal state update
image_data += obs_image_data # inference-side image_data
if obs_mm_train:
mm_train_buffer.append(obs_mm_train) # training-side image_data
return sample04 环境接口
我们为环境(BaseInteractionEnv)定义了一些公用接口以供 user 参考:
reset():清空环境内部状态。
step(response_text: str) -> (observation: dict, done: bool, info: dict):接收模型输出,返回观测与是否结束。
format_observation(observation: dict) -> dict:把 observation 转成下一回合要追加的 chat message。如果 observation 带 multi_modal_data,会把图片放进 message content。
05 实验结果
基于上述设计,我们使用 geo3k 多模态数据集,对 Qwen3-VL-2B-Instruct 进行了 Agentic Multi-Turn GRPO Training,用 Megatron-LM 作为训练后端(具体可参考训练脚本)。实验效果如下:
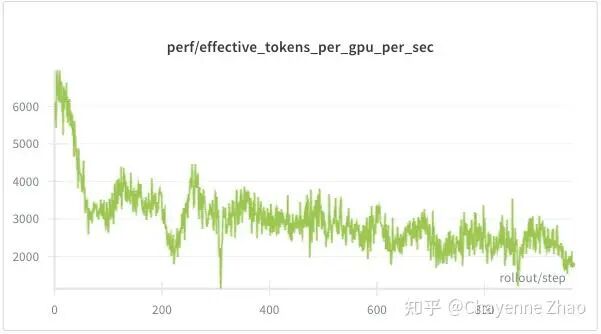
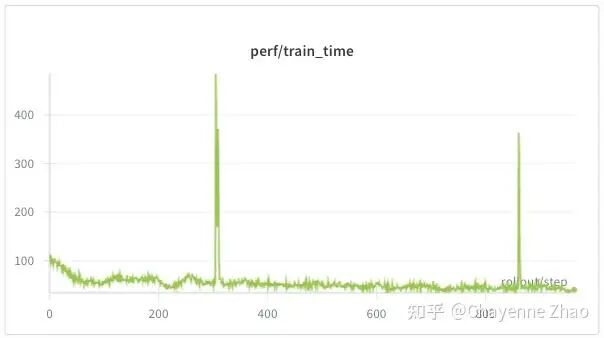
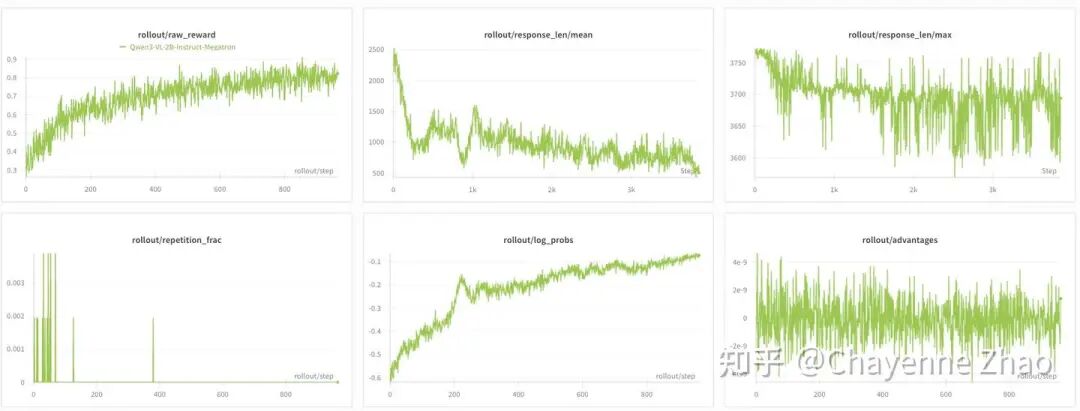
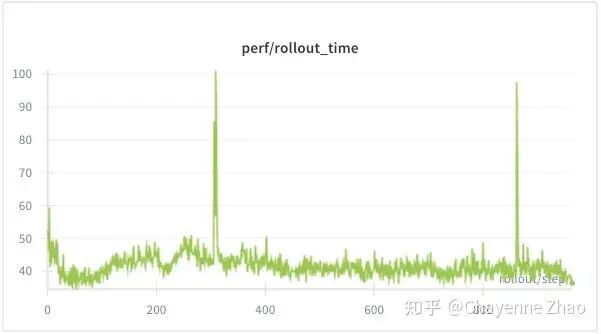
可以看到,raw reward 持续上升并收敛,actor model 实现了有效学习。repetition fraction 很快下降,并未出现无效的语言重复的问题。模型的平均响应长度显著缩短,模型逐步学会更高效的推理方式。
为了进一步测试 VLM multi-turn training 的性能和稳定性,我们将 --rollout-max-response-len从默认脚本里的 4096 逐渐增加到 32000,并把 max_turns 从 3 调大为 20,得到以下的结果:
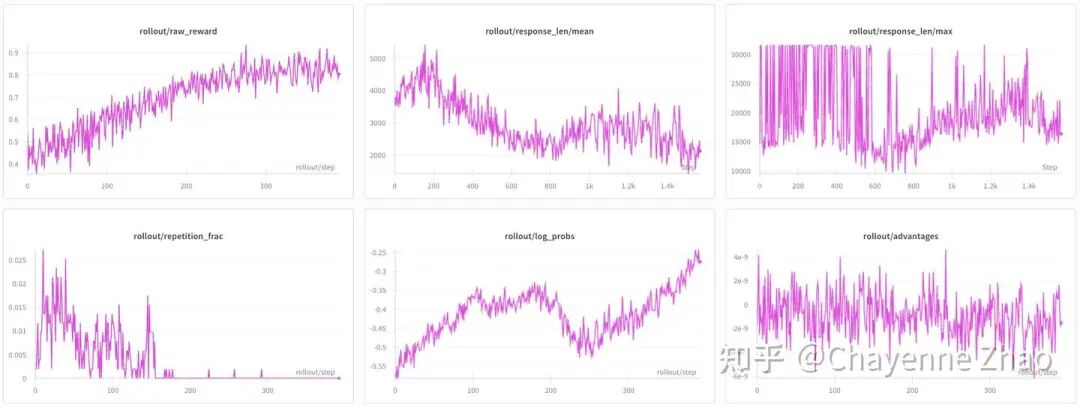
可以看到,raw reward 仍然稳定上升并收敛。其他指标的变化趋势几乎与短上下文、小轮数时无异。
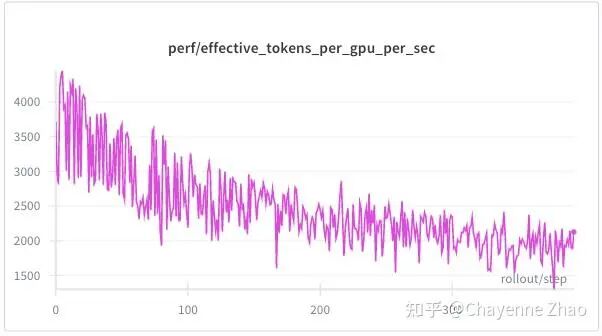
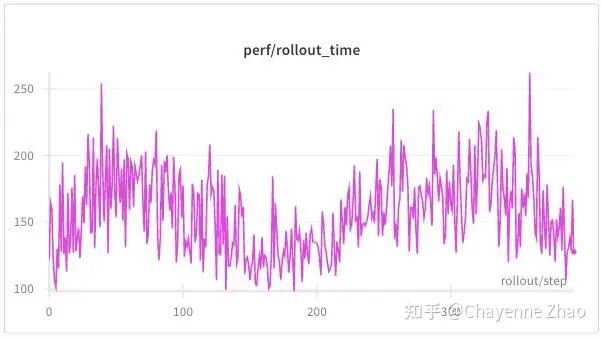
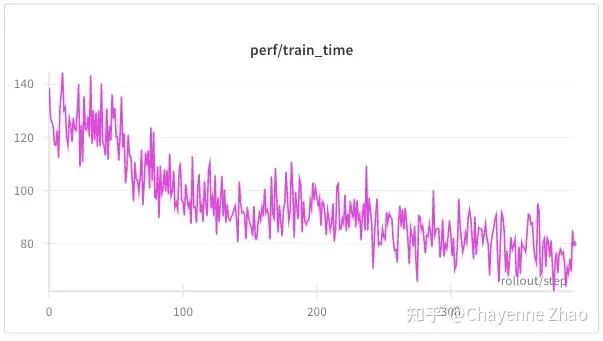
性能方面,与短上下文长度、小轮的情况相比,训练时间和采样时间均有上升,并且采样时间与训练时间的比值也明显增大,这符合预期。注意,如果将上下文长度、轮数设置得过大,可能会出现OOM,需要根据自己的硬件条件和场景来合理设置参数。
06 未来计划
随着 multimodal agentic AI 的训练需求快速增长,我们的 VLM multi-turn RL 更要具备可扩展性和可诊断性。
更稳健的回合控制与重试机制
当前的 turn loop 采用 for turn_idx in range(max_turns),在环境较稳定交互逻辑较简单时尚且可用;但当后续接入更复杂的交互环境(例如 OS 执行)时,env 可能因超时、动作解析失败、偶发服务错误等原因失败。我们考虑引入 retry 功能:例如将回合推进改为 while 循环,仅在“成功完成一次有效交互”后才递增 turn,同时指定环境交互的失败预算(如 max_env_retries_per_turn),在可恢复场景下通过 env.reset()后重试当前 turn,但又能避免无限循环与不可控的运行时开销。
在多轮采样中使用各类 async 训练方法提升性能
正如实验效果部分中提到的,在多轮采样中,不同样本的实际轮数与长度会有较大差异,由少数超长样本造成的长尾效应也许会成为整体吞吐的主要瓶颈。slime 目前已支持 partial rollout,但还没有与 VLM 多轮采样进行很好的适配与测试,这将是未来的一个工作方向。
支持 LLM-as-judge 等更复杂的交互反馈
目前 Geo3K 示例环境是 rule-based 的最小实现,便于验证链路,但很多 multi-turn 场景会引入一个 LLM 来提供每轮的反馈、批改或评价(LLM-as-judge)。由于 rollout 与 env 已解耦因此引入 LLM judge 本身并不要求修改 rollout 主循环;用户只需实现自己的 env 并通过 rollout_interaction_env_path替换即可。但随着交互逻辑变复杂,当前的 Base env class可能偏简单,未来可以考虑为环境接口补充更强的能力。
更完善的 logging 与 turn-level 指标体系
未来需补充更细粒度的指标,例如:实际执行的轮数分布、截断原因分布、env retry 次数与类型等。同时,当前日志更多是整条轨迹的粒度,但调参和排障可能需要轮粒度的debug;因此也可以支持每轮的 logging。
Acknowledgements
Xiaole Guo, Nan Jiang, Zilin Zhu, Jin Pan, Jiajun Li, Yuzhe Zhou, Chengxing Xie, Yueming Yuan, Chenyang Zhao
07 工程附录
1. Observation Tokens 编码方式:dummy messages + delta tokens
在 multi-turn rollout 里,每一轮环境都会返回 observation,我们需要把它编码成 prompt_ids 追加到 sample.tokens,让下一轮生成能“看到”环境反馈。直觉上可以直接对observation 调用 tokenizer.apply_chat_template ([message], tools=...) 进行编码,但这样会引入一个实际问题:chat template 往往会自动插入system prompt以及 tool的使用说明(若tools非空),示例如下:
<|im start]>system
You are a helpful assistant that can use tools to get information for
the user.
# Tools
You may call one or more functions to assist with the user query.You are provided with function signatures within <tools></tools> XMLtags:
<tools>
...若我们每轮都对 observation 直接进行这样的操作,这些文本就会被重复追加到上下文,导致:
上下文被重复内容快速撑大(浪费 token budget)。
即便这些 observation tokens 在训练里被 loss_mask=0 屏蔽,它们仍然占据上下文位置,可能影响行为分布与稳定性。
为了解决这个问题,我们采用了一个通用技巧:用固定的 DUMMY_MESSAGES 作为模板基座,计算其对应的 token 数,然后只取 observation 带来的增量 tokens(delta tokens)。核心思路是:
(1)先对 DUMMY_MESSAGES 单独 apply chat template,得到 dummy_prompt(包含 system/tool preamble,但不包含本轮 observation)。
(2)再对 DUMMY_MESSAGES + [message] apply chat template,得到 formatted_prompt(包含相同的 system/tool preamble + 本轮 observation)。
(3)用 trim_length = len(encode (dummy_prompt) ) 得到需要裁剪的前缀长度;对 formatted_prompt 编码后直接切片:prompt_ids = prompt_ids[trim_length:].从而确保最终追加到上下文的只是一段干净的 observation tokens而不会把 system/tool preamble 每轮重复塞进来。
用伪代码概括就是:
dummy = apply_chat_template(DUMMY_MESSAGES, tools=tools, add_generation_prompt=False)
full = apply_chat_template(DUMMY_MESSAGES + [obs_msg], tools=tools, add_generation_prompt=True)
trim = len(encode(dummy))
obs_ids = encode(full)[trim:] # delta tokens only2. 多轮 multimodal_train_inputs 的处理
在 multi-turn rollout 中,每一轮把 observation 编码进上下文时,如果使用了 VLM 的 processor,就会产出一份供训练侧使用的的 multimodal_train_inputs(一个 dict,value 往往是 torch.Tensor,例如图片相关的特征信息等)。关键问题是:这些张量是按轮产生的碎片化 tensor,最终训练希望得到“拼起来的一整块 tensor”。
我们的拼接策略是:先 buffer,最后按 key torch.cat 一次
实现上分两步:
(1)逐轮收集到buffer
每次 _encode_observation _for_generation (...) 产出 obs_multimodal _train_inputs 时,不立即拼接,而是:multimodal_train_inputs _buffer.append (obs_multimodal_train_inputs)
(2)结束时统一 merge
在 _ finalize _ sample (...) 里调用 _merge _ multimodal _ train _ inputs (multimodal _ train _ inputs _ buffer) :
先把每一轮的 dict 按 key 聚合成 values_by_key[key] = [t0, t1, ...]
对每个 key 只做一次torch.cat(values, dim=0) 得到最终 tensor
这样每个 key 对应的tensor只发生一次大张量分配 + 一次线性拷贝。这样做相比于每轮都concate一次的好处是,可避免反复大块显存分配与拷贝(torch.cat 每次都会新分配输出张量并复制旧内容),并降低碎片化风险;同时也避免每轮 cat 时短暂同时持有 old + new 带来的峰值显存抖动。整体效果是把拷贝/分配开销从O(n²) 降到 O(n),并让 peak memory 更稳定、更不易 OOM。










