绑定手机号
确认绑定









作者:haotian
经授权发布,如需转载请联系原作者
在上一篇《初探MOE-RL训推一致性》中,我们受[2]启发,探讨了MOE-RL的一致性问题,主要从IS估计的variance角度切入。
结合笔者最近的一些自我修养,本文进一步探讨这个问题。
首先明确一点,不存在理论上完美的onpolicy训练,即使调度层面是onpolicy的配置,training-dynamics、推理引擎、推理加速、低精度等等手段加上后,都是事实上的offpolicy-setting。解决好offpolicy-setting的稳定、收敛效率,是比较核心的问题。
我们依然从这个式子出发:
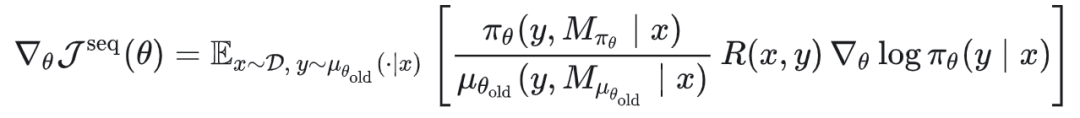
由于推理引擎本身的算子、调度以及可能的加速解码的方法使用,会让期望估计变得越来越复杂。
当下比较好的解决方案:
1. Rollout-Routing-Replay(R3)。将采样分布的expert-routing应用于 policy和old-policy,将MOE变成类似dense-model(消除了由于算子、调度等等带来的expert-routing随机性)。适合onpolicy和offpolicy训练。[5,6]
2. XPO-EWMA。古早时候提升训练稳定性的不二选择:参数平滑(EMA)。笔者在Restricted-Boltzman-Machine训练的时候,应用EMA,会极大加速RBM收敛效率[3]。而EMA在理论上也有一个比较经典的收敛性保证工作: Polyak averaging[4]。
当然上述两个方法也有各自的弊端:
1. R3。多次参数更新但使用旧参数的expert-routing,限制探索。
2. EMA。存在过平滑的问题。(平滑系数、开启平滑的step)。
除了以上经典方法,[7,8,9]均提出了IS-weight修正/IS-MASKING等等方法,解决采样分布、目标分布的不一致带来的期望估计bias。

当我们引入更复杂的推理加速方法,这个IS的修正会变得越来越难分析比如 投机采样 等等。
很多工作包括笔者自己,在引入truncated-is后,agentic+moe的rl训练都可以训的很稳定(纯文本、多模态)等等:
TIS/MIS+适当的learing-rate,基本可以在单轮、几百轮的多轮、多模态、moe、低精度推理 等等上面跑出更稳定长时间训练曲线。
但在一些短周期项目中,长时间的稳定训练可能不是最优选择:时间等不起、环境调用费用过高。
所以,很自然的一个想法是:用最稳定的训练setting+最激进的训练策略,以更短的训练step达到更高的上限。笔者称之为:戴着镣铐,行走在崩溃的边缘快速稳定训练。
但这么做真的可以work么?
01 TIS的一些经验性观测
观测1: [5]中的实验,不使用IS修正时,benchmark-score涨点速度反而是最快的,但崩溃的也更快一些。
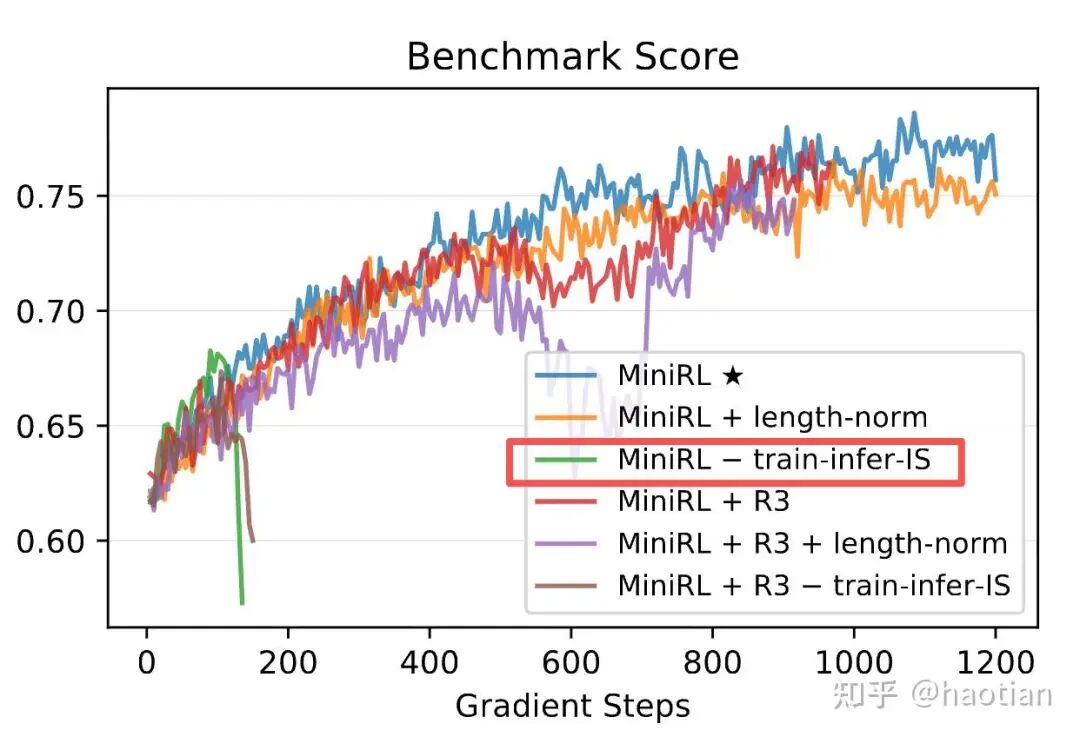
观测2: 在 zero-tir[10]中,我们对比了TIS和sample-filtering的配置,发现token-level的TIS的收敛速度慢于无IS修正的setting。
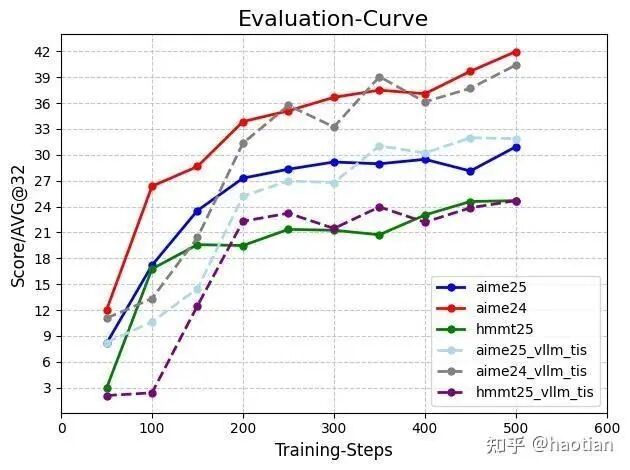
观测3: [2]中的对比实验也验证了这一点。
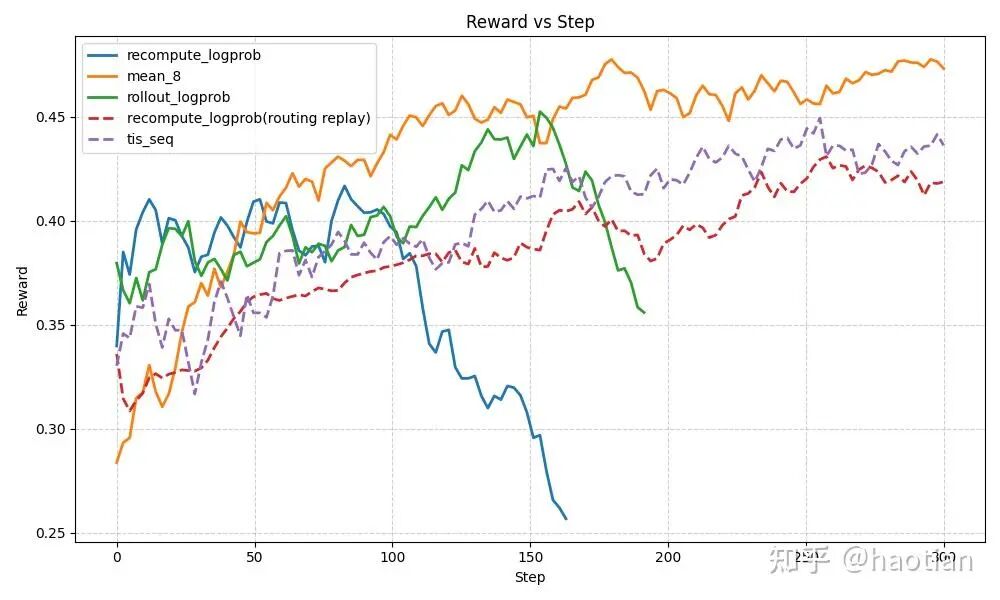
以上三个观测都表明,token-level-tis 或多或少都会降低收敛速度但获得了更稳定的训练。
更稳定的训练不一定带来更好的效果。(笔者曾经使用 string-in-string-out+filter策略,zero-tir也能稳定训1k-step,但700step以后,指标停滞不前。但换成token-in-token-out+filter策略,训到1.6kstep,指标也能长。)
在更复杂的agentic-rl任务(环境复杂、轮数多等等)中,TIS显示出更好的稳定性但往往收敛速度会慢一些。如果底座训的很猛,不加这些修正,TIS也可能弱于最朴素的训练setting(如无必要,勿增实体)。
基于这些观察,笔者决定梭哈一把:在TIS的配置下,将lr设置到和sft一个量级。核心想法:既然稳定,咱们就增加lr,让梯度更新更猛一些。
当lr扩大到和sft一个量级时,大部分的训练setting都会崩的很快,TIS也在预期中可以很稳定的训练。
(如果只有token-level-MIS,会崩溃的慢一些,但最终也崩溃。这里的崩溃,笔者认为/观测到的核心原因:即使同一份参数,训练引擎和推理引擎的kl分布也会大到令人发指的地步。即使onpolicy的setting训练,依然可以训出来让训练引擎和推理引擎在同一份参数下,输出分布差异很大的参数。这个时候,已经变成事实上的offpolicy训练,更需要保持trust-region,显然,token-masking达不到保证trust-region的训练要求[9])。
TIS能够稳定训练,但更激进的训练策略往往不会得到收敛更快的曲线。有可能只是原地打转,看着稳定但毫无进步。
02 TIS的潜在问题
TIS说白了是IS的期望估计(为什么这么做:因为 即使同一份参数,训练引擎和推理引擎的输出分布也可以大到很夸张的地步)。
而IS有个默认需要满足的条件:proposal-distribution要尽可能贴近target-distribution。这个时候,期望估计的方差会比较小,期望估计方差更小,训练优化更稳定(简单理解,梯度方向会更一致,不会一会儿往东一会儿往西,看似稳定其实在原地打转--->原地打转也是一种稳定)。这个时候,优化setting越激进,收敛反而越慢,因为梯度方向比较乱,更多的是原地打转。
当然,proposal-distribution可以是任意分布,即使和target-distribution差很远,依然可以应用IS计算期望,但期望估计的方差会巨大。[11]给出了一个极端情况的variance分析(使用均匀分布作为proposal-distribution)

这个时候,我们有几种手段降低variance:
1. 使用更好的proposal-distribution,即我们要解决训推不一致,保证训推一致性,消除一个影响因子(消了也不一定能更好)。
2. 降低action空间大小,比如 使用topp、topk 采样,类似ds-v3.2里面的RL配置。
3. 增加采样个数,比如使用更大的rollout.n,需要更多的算力。
4. 使用更好的baseline估计方法,比如 optimal-token-baseline[12]。
相比token-level-is,无偏的is是序列级别的is[8]。但使用序列级别的IS,比如 输出token很多的情况下,也会导致序列IS的计算的方差变大。
03 一些可能的小众解决思路
1. Metropolis-Independence-Sampling (MIS)
此MIS非彼MIS。
借鉴stochastic approximation,我们只使用样本但不使用is-ratio做reweight。在笔者古早的一个小文章[3],我们提出了joint-sa训练有向图(中间每一层都是0/1的随机变量)模型:

因为proposal-distribution不一定是很好的target-distribution近似(可以批量采样,估计二者在同一个输入的输出分布的kl距离等等),使用IS-weights会带来比较大的噪声[2]。这个时候,我们仅使用样本做梯度下降(这个有SA的理论保证)。
当然,前提是要求采样的随机变量的稳态分布是目标分布。这个时候,也比较适合投机解码采样的场景。
这里,一个比较简单的MCMC采样方法(MIS采样):

这个方法也能在sequence、geometric、token-level使用,与[8]中的MIS(Masked Importance Sampling (MIS))类似。但Metropolis-Independence-Sampler有更好的收敛保证(short-run-MCMC)。相比[8]中的MIS,Metropolis-Independence-Sampler 省掉了threshold的超参数配置,完全由 proposal、target-distribution的似然值权重决定当前sample是否接受,如果接受就用于模型训练,如果不接受,则加入loss-mask,避免参与训练。序列级别依然是理论上的最佳实践,但可能导致接受率较低。
2. Self-Normalized-Importance-Sampling (SNIS)
SNIS 是 缓解IS估计期望高方差的常见技术手段。在[13]中,已经提出了多种基于SNIS的估计方法。

这里,如果是offpolicy-setting,依然可以使用这个方法,只是需要每次都提前计算group的normalization。
进一步,该工作提出了一个新的snis-estimator:

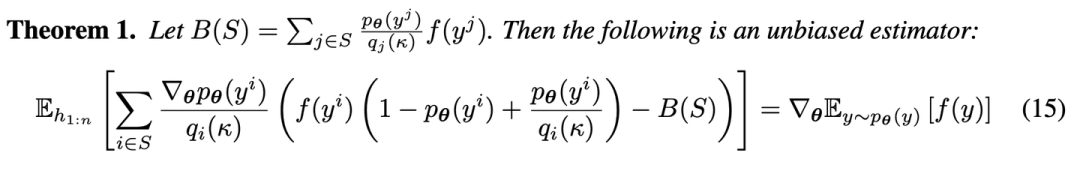
这样,我们通过SNIS得到了方差更小的期望估计estimator,缓解一部分proposal-distribution带来的不靠谱似然值估计。
3. Doubly-Robust-Estimator (DRS)
只要ratio、value-function有一个估计的比较准,就是一个无偏且更鲁棒的estimator。

4. Multiple-Importance-Sampling (MIS)
另一个MIS,在之前的知乎里面提到过,每个mask对应一个distribution,采样N次得到N个distribution。

这里的分母,是不同分布的加权求和。有N个样本N个分布,我们需要N x N次前向计算。
04 总结
EMA参数平滑、R3 都是首选的MOE-RL稳定训练方法,应该作为一个保下限的MOE-baseline。但二者也有各自需要注意的问题。
TIS 不可避免带来一定的high-variance,导致一些setting下,收敛速度慢于朴素的setting。但lr调的合适,也能进行长时间的稳定训练,也可能达到更高的上限。lr调大可能也不会收敛的更快更好。
从期望估计方差的角度出发,我们可以有多种手段缓解:
1. 基于SA理论,应用short-run-MCMC采样,只使用样本不使用IS-weight修正如Metropolis-Independence-Sampling。
2. 基于SNIS,应用有偏或者无偏的SNIS估计器,降低期望估计方差。如[2]中的尝试。
3. 基于value-function的doubly-robust-estimator(DRS)。
4. Multiple-Importance-Sampling(MIS)[15](另一个MIS)。
05 最后
RL的上限要高,reward、更细粒度的rubric打分也需要有(这些往往在数据合成、sft阶段会有,但只有做成标准的service,才能让RL部分也享受到前置阶段的优秀数据选择方法)。随着前置阶段对于 “好/坏” 更清晰的定义、think-pattern的优化,RL也能直接受益。内生健壮、持续进步的pipeline胜于短期的指标领先。
另外,think-pattern更重要[16]。匹配当前model的in-distribution蒸馏效果往往好于OOD-蒸馏效果。好的cpt,需要think-pattern的多样性、以及更多优质的think-pattern。这个时候,应用zero-rl,产出的in-distribution rollout-data,调教的sft,可能上限也会更高一些。
参考文献:
[1] 初探MOE-RL训推一致性
[2] KAT-Coder-V1 Pro 重磅升级,揭秘强化学习训练稳定性关键因素 - KwaiPilot
[3] Joint stochastic approximation learning of helmholtz machines
[4] Acceleration of stochastic approximation by averaging
[5] Stabilizing Reinforcement Learning with LLMs: Formulation and Practices.
[6] Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers.
[7] Your-Efficient-RL-Framework-Secretly-Brings-You-Off-Policy-RL-Training
[8] https://yingru.notion.site/When-Speed-Kills-Stability-Demystifying-RL-Collapse-from-the-Training-Inference-Mismatch-271211a558b7808d8b12d403fd15edda
[9] Trust Region Masking for Long-Horizon LLM Reinforcement Learning
[10] 重温pg-loss的期望计算
[11] https://people.eecs.berkeley.edu/~jiantao/2902021spring/scribe/EE290_Lecture_23_24.pdf
[12] The Optimal Token Baseline
[13] BUY 4 REINFORCE SAMPLES, GET A BASELINE FOR FREE!
[14] Learning Non-Convergent Non-Persistent Short-Run MCMC Toward Energy-Based Model
[15] 【复习】多重重要性采样(Multiple Importance Sampling)
[16] SHAPE OF THOUGHT: WHEN DISTRIBUTION MATTERSMORE THAN CORRECTNESS IN REASONING TASKS
地址:
https://zhuanlan.zhihu.com/p/1989646956054738179










