绑定手机号
确认绑定









作者:姜富春
地址:https://zhuanlan.zhihu.com/p/1931076626940139506
经授权发布,如需转载请联系原作者
自2025年初DeepSeek R1模型发布以来,强化学习(RL)在大型语言模型(LLM)的后训练范式中受到越来越多的关注,R1的突破性在于引入了可验证奖励强化学习(RLVR),通过构建数学题、代码谜题等自动验证环境,使模型在客观奖励信号的驱动下,自发地演化出与人类推理策略高度相似的思维方式。
与此同时,R1模型还提出了GRPO方法。这一方法大幅削减了RL infra的复杂性,它让强化学习在大型语言模型训练中的应用,从原本抽象的理论研究层面,大步迈向了工业界切实可行的实践探索阶段。
随着国内开源生态出蓬勃发展,一批国产强化学习(RL)框架持续开源问世。当下,主流的国产 RL 框架有 Verl、Slime、OpenRLHF、Areal、RoLL 等。
框架繁荣对开发者是友好的,大家选择更多,可以对比着用。但框架多也有困扰,RL的训练框架设计通常是比较重的,集成多引擎能力,包括训练引擎(FSDP,DeepSpeed, Megatron),推理引擎(SGlang, vLLM)。分布式引擎(Ray)等,说实话能捋顺一个框架并且在工业生产级用好,并不是一个低成本的事。跨框架使用对一般业务团队或个人来说,成本是比较高的。
在工业生产级的应用场景中,目前 VERL 框架经过了较为充分的验证,拥有大量可供参考的实际案例和issue。最近半年,本人也是深度使用 VERL 的用户,在忙碌之余,抽空对使用过程中的一些理解和实操经验进行了整理。
个人水平有限,若有错误,欢迎指正~
01 VERL参考材料
1. Paper : HybridFlow: A Flexible and Efficient RLHF Framework
2. 文档手册:https://verl.readthedocs.io/en/latest/index.html
3. Code : https://github.com/volcengine/verl/tree/main
## 参考: https://github.com/volcengine/verl/blob/main/recipe/genrm_remote/run_genrm_remote.sh
python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=grpo \
data.train_files=${HOME}/data/gsm8k/train.parquet \
data.val_files=${HOME}/data/gsm8k/test.parquet \
data.train_batch_size=1024\
data.max_prompt_length=1024\
data.max_response_length=2048\
......2. 入口函数##参考: https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py
@hydra.main(config_path="config",config_name="ppo_trainer",version_base=None)
def main(config):
run_ppo(config)
class TaskRunner:
......
def run(self,config):
......
trainer=RayPPOTrainer(config=config,......)
# Initialize the workers of the trainer.
trainer.init_workers()
# Start the training process.
trainer.fit()接下来我会从如下几个方面来聊聊自己的理解,先简单讲下VERL的设计原理,从宏观上有个理解,然后再逐层深入代码细节展开一些核心的实现,最后基于一个具体例子一步一步记录下Agentic RL的开发实践。
02 VERL设计原理
VERL框架核心设计思想: 控制流程使用单进程, 计算流程使用多进程,即分离控制流程和计算流程。verl旨在解耦RL算法的控制流程和计算引擎的实现。
以下图1是verl的控制-计算分离的设计的简化流程图,表示verl执行强化学习作业的处理过程。在图中,控制器(Driver Process)在单个进程中运行,而执行器(Rollout, Actor, Critic)等Worker Process会放置在特定的资源组(Resource Pool)中在多个进程中运行。
在 rollout 阶段,控制器会把数据传输给生成器(generator),由生成器执行样本生成任务。待 rollout 操作完成后,这些数据会被传回控制器(即 Driver Process),以便开展算法的下一步计算。其他工作进程也遵循类似的流程进行操作。借助这种混合控制器设计,数据流与计算实现了解耦,进而在计算效率以及定义算法训练循环的灵活性上展现出显著优势。
当然这种设计有个很大的弊端是数据传输会有瓶颈,Worker之间的数据交互都要通过Driver Process这个中控节点来协同,所有的数据都要回到中控节点,再通过中控节点分发给下游任务。这通常会使Driver Process执行成为瓶颈,也容易爆存储问题。
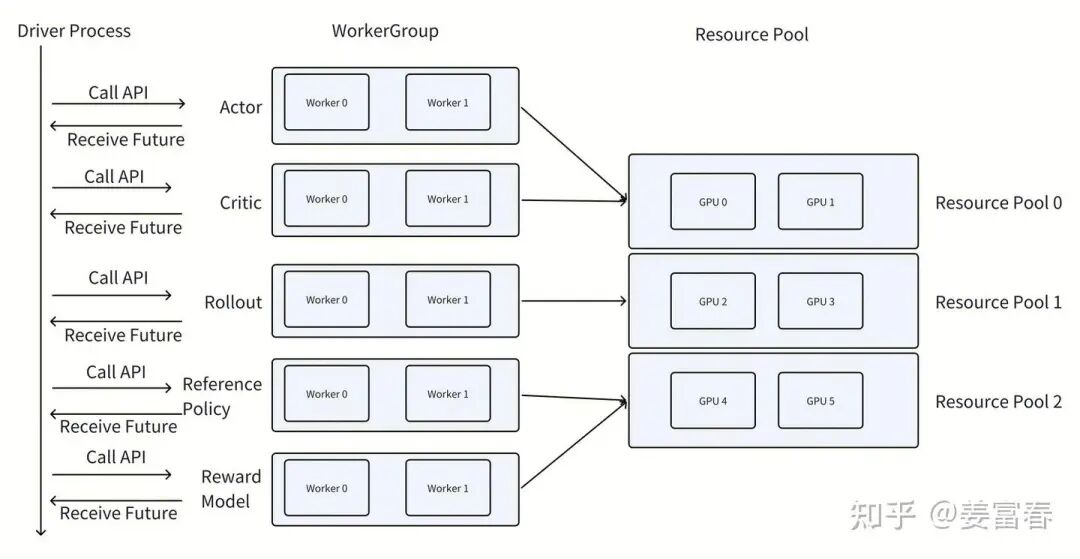
VERL 具体实现中,RayPPOTrainer类扮演着Driver Process的角色, 它负责初始化并构建Worker 和 WorkerGroup ,同时运行 PPO 算法的主循环,RayPPOTrainer 的 fit 函数是以单进程形式运行。WorkerGroup将在其指定的资源池(Resource Pool)上构建。资源池可以理解是 Ray 集群中的一组 GPU。
在VERL实现中,每个 WorkerGroup 负责管理一组远程运行的 Worker。WorkerGroup 在其构造函数中启动进程。WorkerGroup 作为控制器进程的代理,用于与一组 Worker 进行交互,每个 Worker 都在 GPU 上运行,以执行特定的计算任务。为了实现这一功能,VERL实现了WorkerGroup绑定了一组Worker 的方法,能通过在控制流中一次调用,触发关联的多个Worker执行远程任务
简单说,WorkerGroup可调用的方法跟Worker是完全一样的,通过WorkerGroup调用方法,实际执行是触发关联的所有Worker的方法远程执行。
如在RayPPOTrainer主控流程init_worker
class RayPPOTrainer:
def init_workers(self):
"""Initialize distributed training workers using Ray backend.
Creates:
1. Ray resource pools from configuration
2. Worker groups for each role (actor, critic, etc.)
...
## 获取 ActorRollout WorkerGroup
self.actor_rollout_wg = all_wg[str(actor_role)]
## WorkerGroup执行 init_model()初始化,实际是触发了所有绑定Worker执行init_model()执行,如下图所示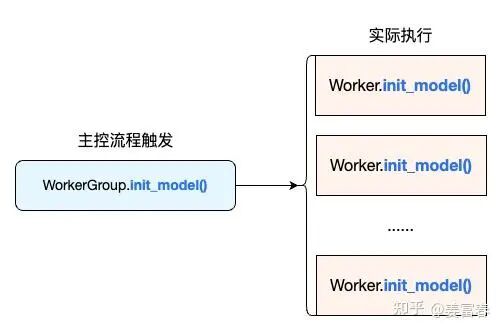
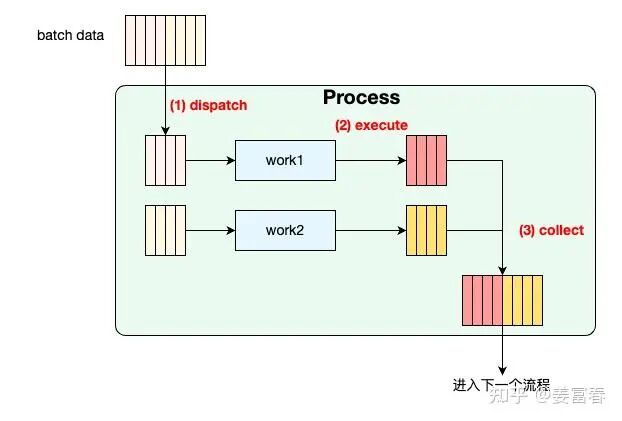
VERL本质是分布式的数据处理流,如下图所示
由于是多Worker运行,会涉及到对数据的分片和拼接处理,从图中的每个Process(绿色的块)都是一个WorkerGroup的方法,我们展开一个绿色的Process块看下细节,大概是这样(如下图所示):
每个Process接收一个Batch数据:
1. 执行dispatch,将数据分发给多Worker
2. 多Worker拿到各自的数据分片,执行任务
3. 执行collect,收集各个Worker计算的分片结果,merge成完整的Batch结果,然后进入下一个计算流程。
VERL 针对强化学习计算中的多个Process,实现了多种数据分发(dispatch)与收集(collect)的方法。在实际执行任务时,可在任务执行前后灵活添加这些分发与收集方法,以此高效处理数据的分发和收集工作。同时,它采用装饰器模式,通过@register(dispatch_mode=xxx)来装饰目标函数,为函数注入数据分发和收集的能力。
具体实现(如下图)
1. Worker的目标方法通过@register(dispatch_mode=xxx)装饰
2. 装饰器register会给目标方法增加一个MAGIC_ATTR的属性,并赋值一个dict,包括{"dispatch_mode": dispatch_mode}键值对
3. WorkerGroup通过_bind_worker_method方法将Worker的所有方法绑定成自己的方法,当识别一个目标方法有MAGIC_ATTR属性,拿到"dispatch_mode"配置动态实例出dispatch 和 collect方法,并调用func_generator返回一个新的方法绑定给WorkerGroup,新方法的执行逻辑: dispatch -> 目标方法 -> collect,实现数据自动分发和收集
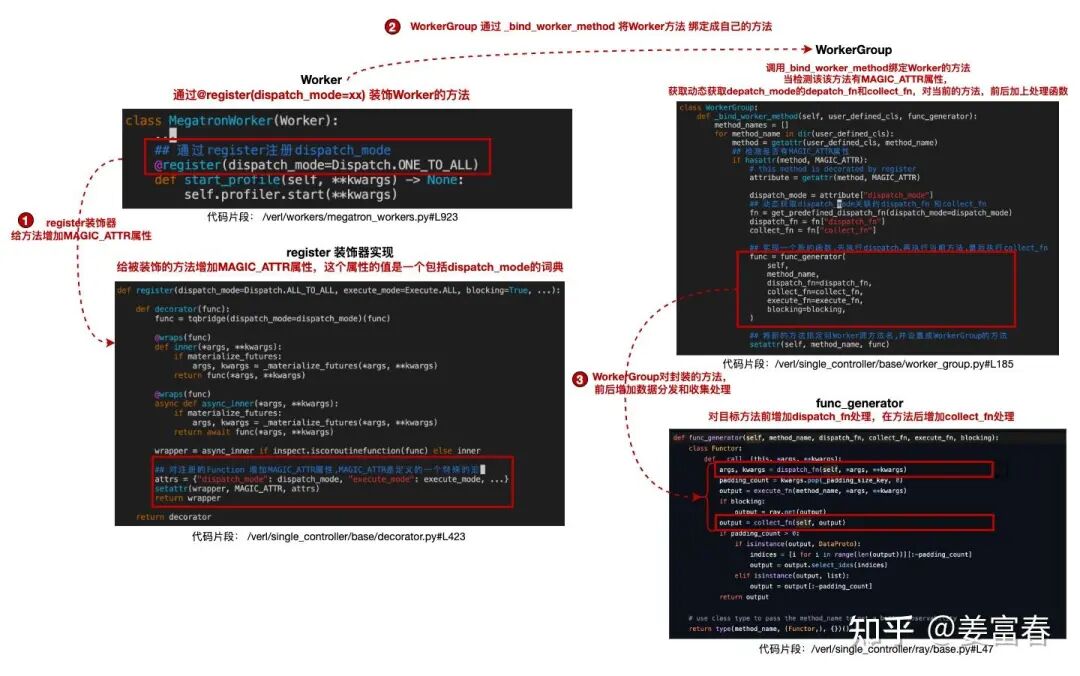
VERL预定义的dispatch_mode如下,每种dispatch_mode都实现了dispatch_fn和 collect_fn,来满足在RL计算流程中的各种数据分发和收集的需求
## 参考https://github.com/volcengine/verl/blob/main/verl/single_controller/base/decorator.py#L332
DISPATCH_MODE_FN_REGISTRY={
Dispatch.ONE_TO_ALL:{"dispatch_fn":dispatch_one_to_all,"collect_fn":collect_all_to_all,},
Dispatch.ALL_TO_ALL:{"dispatch_fn":dispatch_all_to_all,"collect_fn":collect_all_to_all,},
Dispatch.DP_COMPUTE:{"dispatch_fn":dispatch_dp_compute,"collect_fn":collect_dp_compute},
Dispatch.DP_COMPUTE_PROTO:{"dispatch_fn":dispatch_dp_compute_data_proto,"collect_fn":collect_dp_compute_data_proto,},
Dispatch.DP_COMPUTE_PROTO_WITH_FUNC:{"dispatch_fn":dispatch_dp_compute_data_proto_with_func,"collect_fn":collect_dp_compute_data_proto,},
Dispatch.DP_COMPUTE_METRIC:{"dispatch_fn":dispatch_dp_compute_data_proto,"collect_fn":collect_dp_compute},
Dispatch.DIRECT_ROLLOUT_METHOD:{"dispatch_fn":dummy_direct_rollout_call,"collect_fn":dummy_direct_rollout_call,},以最简单的ONE_TO_ALL为例
ONE_TO_ALL.dispatch_fn 实现: 根据worker Group的worker的数量(N),对传递的数据复制N份,每个worker都拿到同样的数据
## 代码:https://github.com/volcengine/verl/blob/main/verl/single_controller/base/decorator.py#L129
def dispatch_one_to_all(worker_group,*args,**kwargs):
args=tuple([arg]*worker_group.world_sizeforarginargs)
kwargs={k:[v]*worker_group.world_sizefork,vinkwargs.items()}
return args,kwargsONE_TO_ALL.collect_fn实现:数据回收不做任何处理,输出源结果
## 代码:https://github.com/volcengine/verl/blob/main/verl/single_controller/base/decorator.py#L143
def collect_all_to_all(worker_group,output):
return outputONE_TO_ALL适合在单控制器阶段指定多Worker执行load,save,profile等操作
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
def load_checkpoint (self,checkpoint_path, hdfs_path=None, del_local_after_load=True):
......
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
def save_checkpoint (self, checkpoint_path, hdfs_path=None, global_step=0, max_ckpt_to_keep=None):其他dispatch_mode可以详见源码,这里不做赘述。
通过@register(dispatch_mode=xxx)装饰的方法,控制器(Driver Process)可以像单进程方法一样直接调用。比如做rollout,实现方法如下
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)# 定义数据并行处理逻辑
def generate_sequences(data):
# 实际生成序列的实现
...通过上面的register修饰后,控制器可像调用单进程方法一样使用方法,实际执行是分布式的数据分发,执行和数数据收集。
output=actor_rollout_ref_wg.generate_sequences(data)# 自动完成 DP 分发和结果收集基于上述 API,PPO 主循环可像单进程程序一样编写,实际运行在多进程环境:
for prompt in dataloader:
# 1. 生成序列并计算概率、价值、奖励
output=actor_rollout_ref_wg.generate_sequences(prompt)
old_log_prob=actor_rollout_ref_wg.compute_log_prob(output)
ref_log_prob=actor_rollout_ref_wg.compute_ref_log_prob(output)
values=critic_wg.compute_values(output)
rewards=reward_wg.compute_scores(output)
# 2. 计算优势函数(在控制器进程直接执行)
advantages=compute_advantages(values,rewards)
# 3. 合并所有数据
output=output.union(old_log_prob).union(ref_log_prob).union(values).union(rewards).union(advantages)
# 4. 更新模型
actor_rollout_ref_wg.update_actor(output)
critic_wg.update_critic(output)设计目标:在多进程计算环境中保持单进程式的编程简洁性。
实现方式:
(1)WorkerGroup 代理多进程 Worker,通过装饰器封装分布式逻辑。
(2)控制器仅需调用高层 API,底层自动处理数据并行和结果聚合。
上面大概介绍了下VERL的设计原理,下面主要从实操的方面梳理下VERL的代码逻辑和开发细节。
我们先思考下训一个RL任务,从大的环节上想想我们要做哪些工作:
1.我们需要准备训练数据;
2.如果是Agent需要把我们的Agent嵌入到RL系统来做Rollout;
3.需要开发Reward Model;
4.最后需要结合自己的场景,开发总控脚本设置配置项。
注:这里的事项没有包括一些算法的开发,通常我们使用算法(包括PPO,GRPO,DAPO等)都可以简单配置使用,一些loss也都可以配置,一般不需要做深入开发,足够大部分场景使用。
上面这些工作,涉及VERL的数据协议,配置管理,AgentLoop三块内容,下面我们就来展开来聊聊。
03 VERL数据协议
首先我们拿一个开源数据集为例,看下VERL内部数据的流转状态。
我们以开源数据集nq_hotpotqa_train为例,该数据集是一个封闭题库,数据集自带golden_answer,可用该数据集直接训裸模RL,做简单测试。
我们可视化下RL各阶段操作后的内部数据结构,看下内部数据的协议
如下是一条样本数据,这里面核心的字段是prompt(做rollout)和reward_model.ground_truth (计算reward score)。extra_info可以用来透传一些额外的辅助信息,会在Reward计算中,辅助做些复杂的计算。
{
"data_source":"nq",
"prompt":[
{
"content":"You are a helpful and harmless assistant.",
"role":"system"
},
{
"content":"Answer the given question. You must conduct reasoning inside <think> and <\/think> first every time you get new information. After reasoning, if you find you lack some knowledge, you can call a search engine by <tool_call> query <\/tool_call> and it will return the top searched results between <tool_response> and <\/tool_response>. You can search as many times as your want. If you find no further external knowledge needed, you can directly provide the answer inside <answer> and <\/answer>, without detailed illustrations. For example, <answer> Beijing <\/answer>. Question: total number of death row inmates in the us?",
"role":"user"
}
],
"ability":"fact-reasoning",
"reward_model":{
"ground_truth":{
"target":[
"2,718"
]
},
"style":"rule"
},
"extra_info":{
"index":0,
"question":"who got the first nobel prize in physics?",
"split":"train"
}
}这样一条数据,经过Dataset处理(详见rl_dataset.py): 将全部样本数据加载到一个迭代器里,Dataset内部做了一些Token化,Attention_Mask的处理,最终处理后数据如下:
[
//index[0]第一条数据
{//原数据集字段
"data_source":"searchR1_nq",
"prompt":[{...},{...}],
"ability":"fact-reasoning",
"reward_model":{...},
"extra_info":{...},
"metadata": null,
//新增
"input_ids":input_ids,//Prompt的tokenid
"attention_mask":attention_mask,
"position_ids":position_ids,
"raw_prompt_ids":raw_prompt_ids,
"raw_prompt":messages,//原始massage的Prompt
"full_prompts":raw_prompt,//过了chattemplate的Prompt
"index":row_dict.get("extra_info",{}).get("index",0),
"tools_kwargs":row_dict.get("extra_info",{}).get("tools_kwargs",{}),
"interaction_kwargs":row_dict.get("extra_info",{}).get("interaction_kwargs",{})
},
//index[1]
......
]
经过Dataloader将数据组织成Batch(详见:RayPPOTrainer._create_dataloader)
{//一个Batch数据
"data_source":[batch_size],
"prompt":[batch_size],
"ability":[batch_size],
"reward_model":[batch_size],
"extra_info":[batch_size],
"metadata":[batch_size],
"input_ids":[batch_size,MAX_INPUT_LEN],
"attention_mask":[batch_size,MAX_INPUT_LEN],
"position_ids":[batch_size,MAX_INPUT_LEN],
"raw_prompt_ids":[batch_size,MAX_INPUT_LEN],
"raw_prompt":[batch_size],
"full_prompts":[batch_size],
"index":[batch_size],
"tools_kwargs":[batch_size],
"interaction_kwargs":[batch_size]
}再进一步处理成VERL的统一数据协议(DataProto),代码如下:
## 参见:https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py#L1420
for batch_dict in self.train_dataloader:
batch:DataProto=DataProto.from_single_dict(batch_dict)在后续的所有计算更新过程,DataProto作为统一的标准数据协议,这个协议可以扩展管理任意类型的数据。
我们看看DataProto定义:
classDataProto:
#####
# batch 是TensorDict类型,TensorDict 允许你将一个由Tensor组成的字典像操作单个张量一样进行操作。
# 理想情况下,应将具有相同batch size的Tensor放入batch中。
# batch里存的是参与模型计算的Tensor,如input_ids, position_ids等
#####
batch:TensorDict=None
#####
# non_tensor_batch 是保留每个样本的一些原始信息,如原始prompt,原始样本里的extra_info等
#####
non_tensor_batch:dict=field(default_factory=dict)
#####
# meta_info 保存的是跟Batch无关的全局信息,如采样的temperature等
#####
meta_info:dict=field(default_factory=dict)一条DataProto,可视化的数据大概长这样
{//一条DataProto数据
//DataProto.batch模型计算相关
TensorDict(
fields={
"input_ids":Tensor(shape=torch.Size([64,max_seq_len]),device=cpu,dtype=torch.float32,is_shared=False),
"attention_mask":Tensor(shape=torch.Size([64,max_seq_len]),device=cpu,dtype=torch.float32,is_shared=False),
"position_ids":Tensor(shape=torch.Size([64,smax_seq_len]),device=cpu,dtype=torch.float32,is_shared=False),
"raw_prompt_ids":Tensor(shape=torch.Size([64,max_prompt_len]),device=cpu,dtype=torch.float32,is_shared=False)
},
batch_size=torch.Size([64]),
device=None,
is_shared=False)
//DataProto.non_tensor_batch每条样本的附加字段
{
"raw_prompt":[batch],
"full_prompts":[batch],
"index":[batch],
"tools_kwargs":[batch]
}
//DataProto.meta_info全局一些信号
{
"temperature":0.7,
"top_p":0.8
}
}04 VERL配置管理
VERL框架使用了Hydra来管理配置项,Hydra 是 Meta 开发的一个基于 Python的开源配置管理工具,专为机器学习等复杂项目设计。它通过分层组合的方式,解决了传统 argparse 或单一 yaml 难以管理成百上千参数的问题。
Hydra 允许你将配置拆分为多个模块(如:数据集配置、模型配置、优化器配置),并在运行时动态组合它们。
配置组 (Config Groups):将相关配置放在文件夹中,通过 defaults列表自由切换(例如一键从 mysql切换到 postgresql)。
命令行覆盖:可以在不修改代码的情况下,通过命令行直接覆盖任何嵌套参(如 python train.py model.lr=0.01)。
层级化配置:支持 YAML 嵌套和多文件组合,配置结构清晰。
动态实例化:支持通过 _target_ 关键字在配置中直接定义 Python 类,通过Hydra动态实例化。
我们来看看VERL的配置管理 ,分如下四个层级
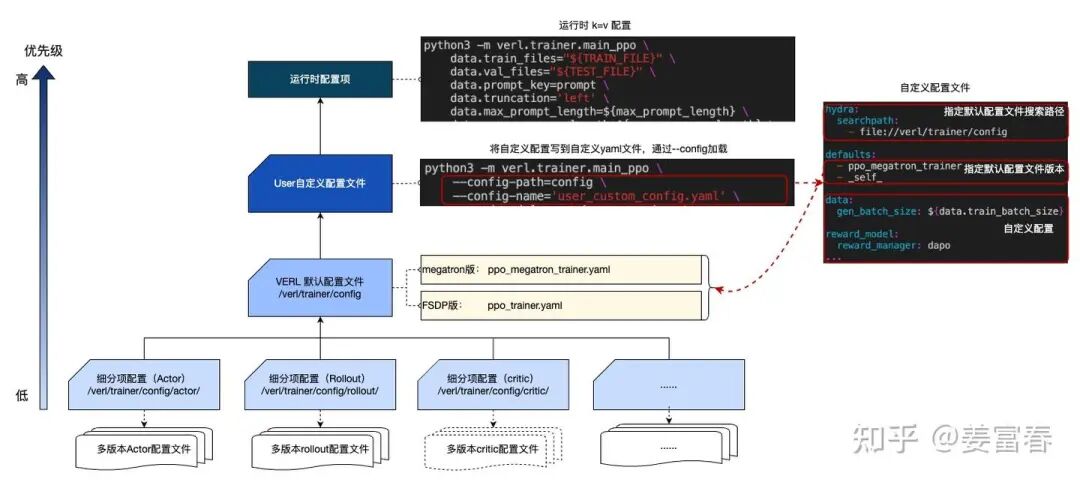
配置优先级
运行时配置,在运行脚本通过k=v的方式传入,优先级最高
自定义配置文件: 指定配置文件,设置配置项,通过--config-path 和--config-name加载
VERL默认配置文件:/verl/trainer/config 定义了默认配置项,包括总控配置项ppo_trainer.yaml(fsdp版)和ppo_megatron_trainer.yaml(megatron版)
细粒度分项配置文件:在/verl/trainer/config的子文件夹下,定义了细分维度的配置项
配置项通过defaults指定多配置的优先级文件的优先级,后面的配置覆盖前面同名的配置。当前文件的配置用_self_关键字表示。
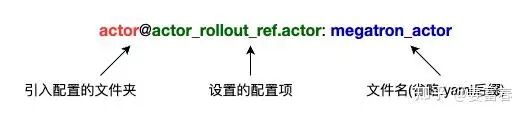
defaults可以指定文件来初始化配置项,具体形式:文件夹@配置项名称: 文件名(省略yaml后缀)
如ppo_megatron_trainer.yaml:
# specify the default per-component configs
defaults:
- actor@actor_rollout_ref.actor:megatron_actor
- data@data:legacy_data
......
我们开发项目设置配置时,一般是改运行时配置和自定义配置文件,通过指定自定义的配置优先级更高的方式来覆盖默认配置,不会修改框架默认的配置项。
05 VERL AgentLoop
下面我们来看看RL的Rollout和Reward Model开发的核心模块: AgentLoop,在展开这块之前,我们先来看看一个最简单的RL训练流程
目前主流的RL训练包括同步(sync) 和 异步(async)两种模式
同步:on-policy,表示使用当前模型采样的样本来进行训练的,一个Batch的采样和训练串行执行
异步:off-policy,表示使用历史版本模型采样,来训练当前模型,采样和Batch并行执行,并发效率更高,有多种模式,相对比较复杂,后面有时间单独整理个笔记
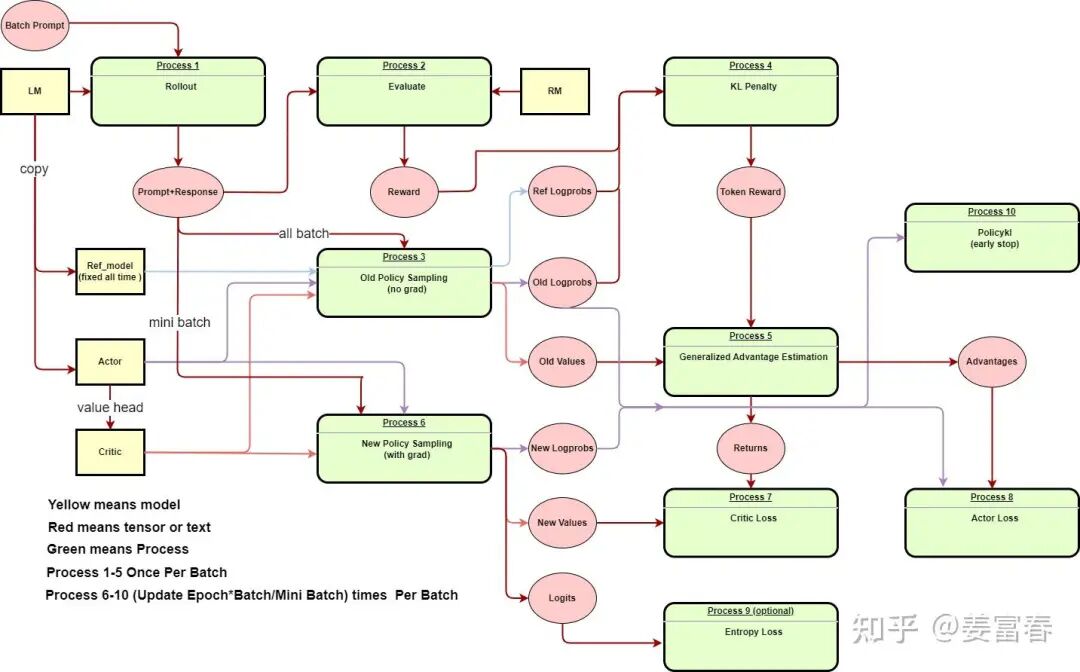
为了理解简单,我们来看下同步RL训练,最简单的就是同步的GRPO训练。如下图:
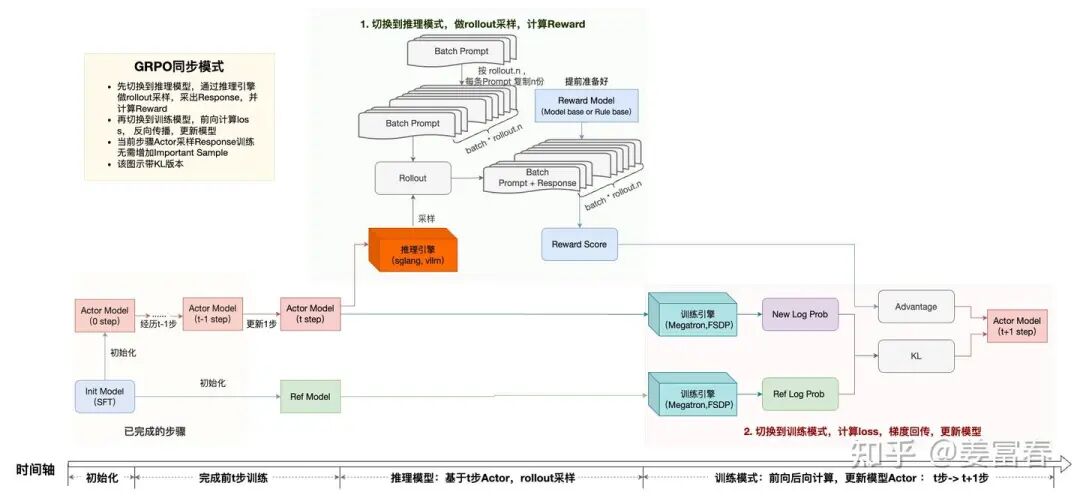
同步训练一个Batch Task Prompt训练1步,包括4个阶段:
1. rollout采样: 将Actor Model部署到推理引擎,对于一个Batch的Prompt通过推理引擎产出Response,对于GRPO,一个Prompt要采样rollout.n个答案,VERL处理是对Batch直接复制rollout.n倍,然后与Agent交互进行采样
2. 采样的样本输入给Reward Model,计算Reward score
3. 计算经验数据(experience): 切换成训练模式,计算经验数据,准备计算Loss Function的一些中间变量,包括(log prob, advantage, KL等)
4. 计算loss, 反向传播梯度,更新模型。再回到步骤1,重复这个循环,直至训练结束。
注:这里并没有计算old log prob,old log prob是为了计算 IS(Impotant Sampling)和 熵Loss使用,这里不考虑增加熵Loss,因为同步训练不存在采样样本跟当前模型分布不一致问题,所以不需要计算IS,因此图中没有old log prob。
在Rollout+Reward的执行过程,VERL也有两种实现模式
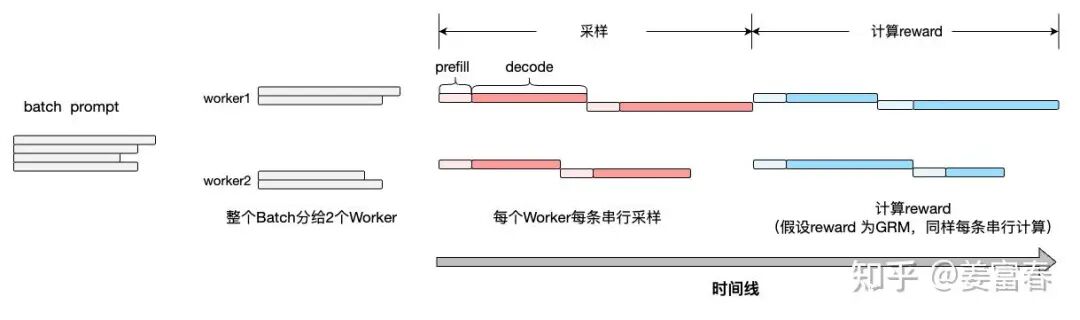
方式1: 采样和reward计算Batch粒度串行执行,如下图:先完整采样一个Batch,获取一个Batch的response后,再完整计算一个Batch的Reward score
方式2:采样和reward计算单条数据串行,整个Batch 流水线并行。每条Prompt采样完,立即计算Reward score。
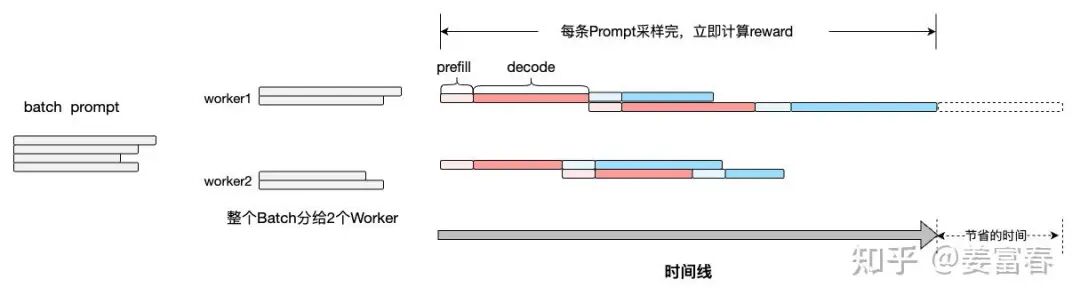
两种方式,方式2要明显更高效,尤其Reward计算耗时比较长时,单条流水式的并行计算,效率会更高。
VERL rollout主入口如下(generate_sequences):
## https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py#L1343
class RayPPOTrainer:
def fit(self):
gen_batch_output=self.async_rollout_manager.generate_sequences(gen_batch_output)
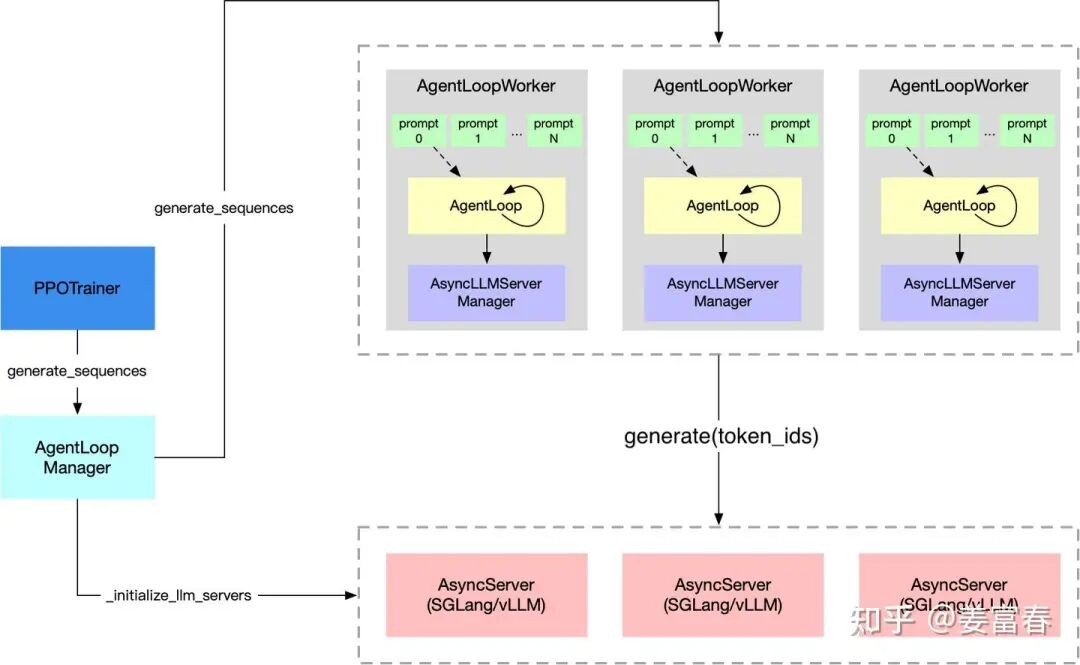
generate_sequences具体执行流程,核心是下面是AgentLoop循环(如下图所示),首先通过AgentLoopManager初始化推理引擎(SGLang/vLLM Server);然后调度多AgentLoopWorker,每个Worker执行Agent调用,进行采样;AgentLoopWorker还会管理RewardLoopWorker执行Reward Score计算。
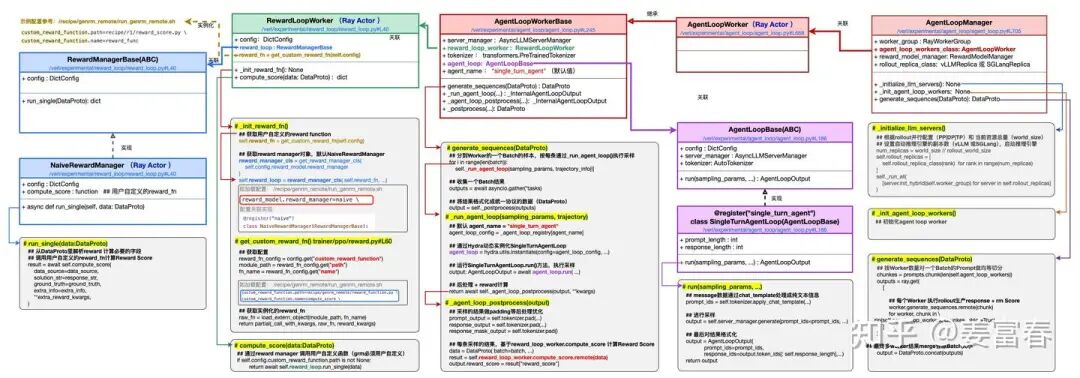
Agentloop具体实现,类图如下:
06 Agentic RL 开发实践
下面我们以一个简单的Agent的场景为例,实操开发下Agentic RL
例子:我们有一个搜索工具,我们的模型要自主规划做Function call和Answer。我们假设reward Model是一个LLM 的PE 的Judge Model。如下图所示:
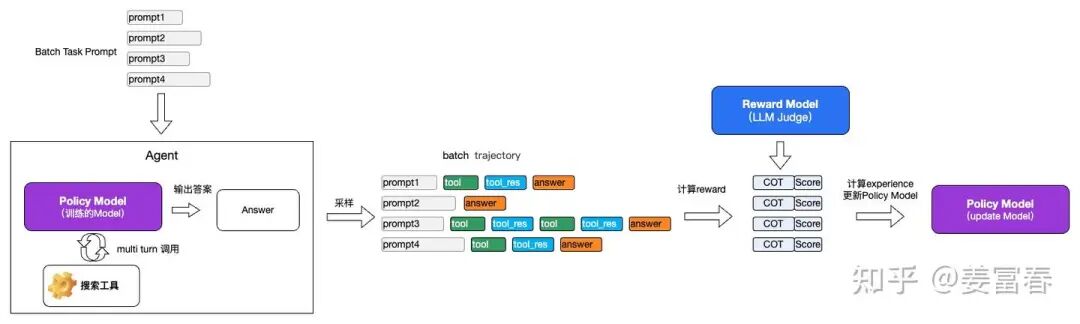
我们一步步看下基于VERL来实现上面的Agentic RL。
我们简单模拟一个搜索工具,定义(web_search):可放到/verl/tools下,新建web_search.py文件,模拟工具实现,如下
## 文件路径: /verl/tools/web_search.py
def web_search(query:str,num_results:int=10)->str:
"""
工具输入query,默认返回10条网页Doc, 每个网页包括:title 和content两个字段
"""
# result = api_request(query) ## 替换成自己真实的工具
# fake一个结果
result=[
{
"title":"西红柿炒鸡蛋做法-菜谱网",
"content":"西红柿炒鸡蛋是以西红柿和鸡蛋为主要材料制作的一道家常菜。主要食材有鸡蛋,西红柿..."
}
]*10
return json.dumps(result)
工具Function call标准化描述信息
{
"type":"function",
"name":"web_search",
"description":"访问互联网,获取实时的、最新的联网数据,工具默认返回10条Doc,每篇Doc包括title和content信息",
"parameters":{
"type":"object",
"properties":{
"query":{
"type":"string",
"description":"搜索关键词",
},
},
"required":["query"]
},
}
VERL框架对工具做了进一步封装,所有工具都要继承BaseTool或MCPBaseTool,才能集成到框架里被调用。如果你的工具是OpenAPI接口的,则需要继承BaseTool封装;如果是MCP封装的工具,需要继承MCPBaseTool。
具体开发:在/verl/tools目录下新增工具实现脚本my_web_search_tool.py。参考同目录下的其他工具类实现,实现get_openai_tool_schema(), execute()等方法。具体代码参考如下:
## 请参考 https://github.com/volcengine/verl/blob/main/verl/tools/search_tool.py#L117
class MyWebSearchTool(BaseTool):
"""Search tool for retrieving information using external retrieval services.
This tool provides search functionality with rate limiting and concurrent execution
support through Ray. It integrates with external retrieval services to perform
semantic search operations.
Methods:
get_openai_tool_schema: Return the tool schema in OpenAI format
create: Create a tool instance for a trajectory
execute: Execute the search tool
calc_reward: Calculate the reward with respect to tool state
release: Release the tool instance
"""
两个基类的描述:
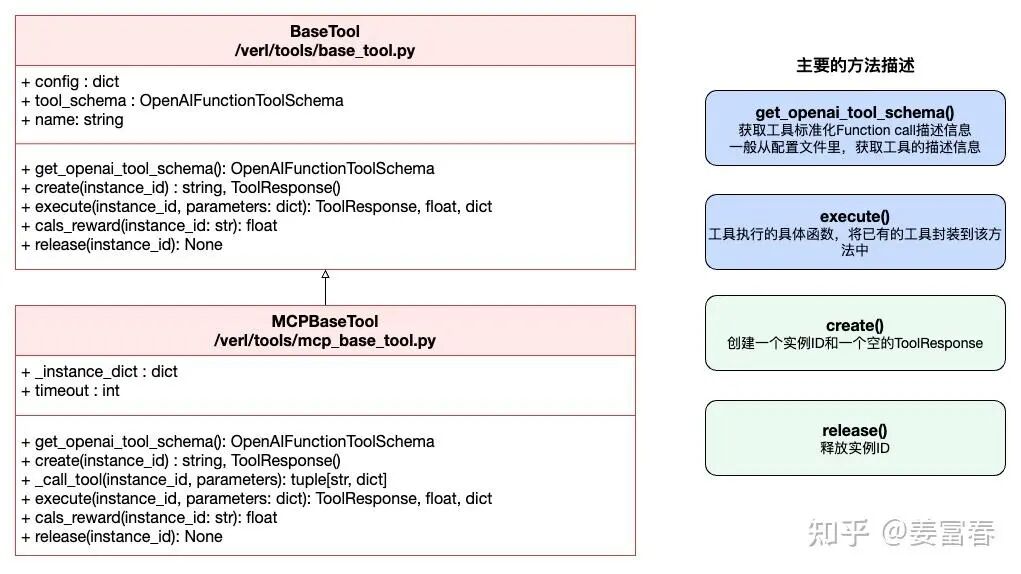
VERL对工具的调用通过配置一个文件来声明工具,然后会在初始化阶段动态加载配置文件,实例化工具。配置文件描述工具的实现类(class_name),工具的类型(type)和工具标准化描述(tool_schema)
具体实现:我们在/examples/sglang_multiturn/config/tool_config/ 目录下新增工具描述文件: my_web_search_tool_config.yaml
具体配置项如下:
## 参考 https://github.com/volcengine/verl/blob/main/examples/sglang_multiturn/config/tool_config/search_tool_config.yaml
tools:
## 上面实现的工具类
- class_name:verl.tools.search_tool.MyWebSearchTool
config:
## 原生的API设置type为native; MCP的接口设置为mcp
type:native
## 对齐JSON版的工具描述信息,格式化成YAML版
tool_schema:
type:function
function:
name:search
description:访问互联网,获取实时的、最新的联网数据,工具默认返回10条Doc,每篇Doc包括title和content信息
parameters:
type:object
properties:
query:
type:string
description:搜索关键词
required:
- query
Agentic RL模型需要调用上面的工具,执行Function Call,对于我们训练的不同模型,工具的输出协议是不一样的。
<tool_call>
{"name": "get_weather", "arguments": {"location": "北京"}}
</tool_call>
<tool_call>
{"name": "get_weather", "arguments": {"location": "上海"}}
</tool_call>Deepseek的Function call输出为:
<|tool▁calls▁begin|>
<|tool▁call▁begin|>
get_weather<|tool▁sep|>{"location": "北京"}
<|tool▁call▁end|>
<|tool▁call▁begin|>
get_weather<|tool▁sep|>{"location": "上海"}
<|tool▁call▁end|>
<|tool▁calls▁end|>
我们要能根据模型的输出,正确解析出Function 的 name和 arguments,然后执行工具调用拿结果。要正确解析出我们训练模型的参数,就要有个后处理的解析函数。在VERL中,我们需要开发一个ToolParser函数,来做这个解析。具体实现:
在/verl/experimental/agent_loop/tool_parser.py文件实现自己的ToolParser方法,如果是Qwen系模型,则可直接使用HermesToolParser。我们自定义个ToolParser:MyModelToolParser, 实现如下:
@ToolParser.register("my_model_toolparser")
class MyModelToolParser(ToolParser):
def__init__(self,tokenizer)->None:
self.tool_call_regex=regex.compile(r"<tool_call>(.*?)</tool_call>",regex.DOTALL)
async def extract_tool_calls(self,responses_ids:list[int])->tuple[str,list[FunctionCall]]:
matches=self.tool_call_regex.findall(text)
function_calls=[]
for match in matches:
try:
function_call=json.loads(match)
name,arguments=function_call["name"],function_call["arguments"]
function_calls.append(FunctionCall(name=name,arguments=json.dumps(arguments,ensure_ascii=False)))
except Exception as e:
logger.error(f"Failed to decode tool call: {e}")
# remaing text exclude tool call tokens
content=self.tool_call_regex.sub("",text)
returnfunction_call
可参见VLLM对各模型Function Call的parser实现: https://github.com/vllm-project/vllm/blob/v0.9.1/vllm/entrypoints/openai/tool_parsers/
到这步,我们已经有了工具(MyWebSearchTool),也确定了我们要训练的模型,并开发了模型Function Call的解析脚本。下面我们就可以实现一个AgentLoop把Tool,Model串起来,能正确执行Multi turn的Agent调用。
实现上,我们需要继承AgentLoopBase基类,在/verl/experimental/agent_loop下参考tool_agent_loop.py,实现自己的AgentLoop:新建文件: my_tool_agent_loop.py ,声明类:MyToolAgentLoop,通过@register注册一个agent_name(my_tool_agent),这个agent_name可以作为我们使用该AgentLoop的Key。示例代码如下:
## 参考ToolAgentLoop实现 https://github.com/volcengine/verl/blob/main/verl/experimental/agent_loop/tool_agent_loop.py#L96
@register("my_tool_agent")
class MyToolAgentLoop(AgentLoopBase):
def__init__(self,...)
):
super().__init__(trainer_config,...)
config=trainer_config.config
## 初始化工具调用相关配置
# 设置当前请求最大执行轮数
self.max_user_turns=config.actor_rollout_ref.rollout.multi_turn.max_user_turns
self.max_assistant_turns=config.actor_rollout_ref.rollout.multi_turn.max_assistant_turns
# 设置一次Function Call 最大并行调用量
self.max_parallel_calls=config.actor_rollout_ref.rollout.multi_turn.max_parallel_calls
# 设置工具结果的最大长度
self.max_tool_response_length=config.actor_rollout_ref.rollout.multi_turn.max_tool_response_length
# 当工具返回结果超长,截断的方向(left, right)
self.tool_response_truncate_side=config.actor_rollout_ref.rollout.multi_turn.tool_response_truncate_side
# 根据步骤(3)的配置,动态加载工具,初始化工具实例
tool_config_path=config.actor_rollout_ref.rollout.multi_turn.tool_config_path
tool_list=initialize_tools_from_config(tool_config_path)iftool_config_pathelse[]
self.tools={tool.name:toolfortoolintool_list}
self.tool_schemas=[tool.tool_schema.model_dump(exclude_unset=True,exclude_none=True)fortoolintool_list]
# 配置步骤(4)定义的ToolParser
self.tool_parser=ToolParser.get_tool_parser(
config.actor_rollout_ref.rollout.multi_turn.format,self.tokenizer
)
self.tool_parser_name=config.actor_rollout_ref.rollout.multi_turn.format
# 输入输出长度配置
self.prompt_length=config.actor_rollout_ref.rollout.prompt_length
self.response_length=config.actor_rollout_ref.rollout.response_length
## 实现run方法
@rollout_trace_op
async def run(self,sampling_params:dict[str,Any],**kwargs)->AgentLoopOutput:
messages=list(kwargs["raw_prompt"])
# 创建一个AgentData实例,用于保存Agent运行时的所有中间状态
agent_data=AgentData(messages=messages,...)
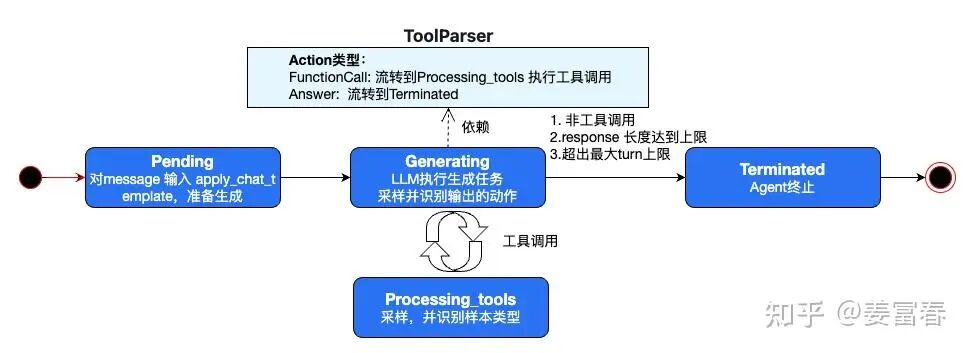
## AgentLoop是执行一个Agent状态机,这是ToolAgentLoop的核心
"""
初始状态: AgentState.PENDING, 用户将message输入,通过Chat Template处理成扁平的文本格式
LLM执行生成状态: AgentState.GENERATING, LLM执行Function Call 或 Answer
工具执行状态:AgentState.PROCESSING_TOOLS,执行工具调用
终止状态: AgentState.TERMINATED,任务结束
"""
state=AgentState.PENDING
whilestate!=AgentState.TERMINATED:
ifstate==AgentState.PENDING:
state=awaitself._handle_pending_state(agent_data,sampling_params)
elifstate==AgentState.GENERATING:
state=awaitself._handle_generating_state(agent_data,sampling_params)
elifstate==AgentState.PROCESSING_TOOLS:
state=awaitself._handle_processing_tools_state(agent_data)
else:
logger.error(f"Invalid state: {state}")
state=AgentState.TERMINATED
output=AgentLoopOutput(
prompt_ids=prompt_ids,response_ids=response_ids[:self.response_length],...)
returnoutput
AgentLoop的Multi Turn执行,我们需要实现一个状态机:可以多次执行工具调用,并最终输出Answer。状态机如下图所示:
到这我们就开发好了我们的Agent,执行AgentLoop就可以实现Multi Turn的Rollout采样。下面我们还要实现对每条样本计算Reward Score的逻辑。
VERL通过RewardManager来管理Reward的计算,如第5节的描述,VERL实现了两种Rollout+Reward计算的方式。对应RewardManager的实现入口:
1.同步方式计算Reward(Batch Rollout + Batch Reward):入口:/verl/experimental/reward_loop/reward_manager
继承AbstractRewardManager类,重载__init__, __call__两个方法
class AbstractRewardManager(ABC):
@abstractmethod
def__init__(self,...):
pass
@abstractmethod
def__call__(self,data:DataProto,...)->torch.Tensor|dict[str,Any]:
pass
2.异步方式计算Reward(单Prompt Rollout + 单Prompt Reward 流水线计算):入口:/verl/workers/reward_manager
继承RewardManagerBase虚基类,实现方法run_single方法
class RewardManagerBase(ABC):
@abstractmethod
async def run_single(self,data:DataProto):
raise NotImplementedError
我们以按异步为例,实现自己的RewardManager,在目录:/verl/experimental/reward_loop/reward_manager 下,新建文件:my_web_search_reward_manager.py,声明类:MyWebSearchRewardManager
我们需要实现run_single方法,接口传入一条完整的DataProto协议的样本数据。实现逻辑上,我们需要拿到模型采样的response(response_str), 和我们样本里的(ground_truth),传给我们自定义的compute_score方法(详见步骤7),计算Reward score,实现如下:
## 参考: https://github.com/volcengine/verl/blob/main/verl/experimental/reward_loop/reward_manager/naive.py
@register("my_reward_manager")
class MyWebSearchRewardManager(RewardManagerBase):
async def run_single(self,data:DataProto)->dict:
## 做必要的校验,取必要的前置数据
assert len(data)==1,"Only support single data item"
data_item=data[0]
......
data_source=data_item.non_tensor_batch["data_source"]
ground_truth=data_item.non_tensor_batch["reward_model"]["ground_truth"]
extra_info=data_item.non_tensor_batch.get("extra_info",{})
......
extra_info["num_turns"]=num_turns
extra_info["rollout_reward_scores"]=rollout_reward_scores
response_str=awaitself.loop.run_in_executor(
None,lambda:self.tokenizer.decode(valid_response_ids,skip_special_tokens=True)
)
## 调用自定义的Reward计算方法
result=awaitself.compute_score(
data_source=data_source,
solution_str=response_str,
ground_truth=ground_truth,
extra_info=extra_info,
**extra_reward_kwargs,
)
## 返回Reward score
reward_extra_info={}
reward_extra_info["acc"]=score
reward=result
return{"reward_score":reward,"reward_extra_info":reward_extra_info}
VERL支持我们自定义Reward Function,传给RewardManager来计算Reward Score。这个主要是定义一个方法,接收模型预估的Response和样本的一些字段(ground_truth, extra_info等)来计算打分
具体实现:在/verl/utils/reward_score/ 目录下,新建一个文件 my_reward_function.py,并实现自己的Reward 逻辑,如下:
def compute_score (data_source, solution_str, ground_truth, method="strict", format_score=0.0,score=1.0):
"""The scoring function for exact match (EM).
Args:
data_source: 样本中的data_source字段
solution_str: 模型输出的answer结果
ground_truth: 样本中的ground_truth字段
....
"""
## 从模型的结果里,按自己的逻辑抽取答案
answer=extract_solution(solution_str=solution_str)
open_count,close_count=count_answer_tags(solution_str)
do_print=random.randint(1,64)==1
if answer is None:
return 0
else:
## 检测Answer是否与golden Answer匹配
if em_check(answer,ground_truth["target"]):
return 1
else:
return 0
完成上面的开发,我们基本完成了Agentic RL的主要实现,我们总结下实现了哪些类和方法:
1. 一个工具:MyWebSearchTool,通过配置文件my_web_search_tool_config.yaml声明
2. 自定义了模型Function Call解析类: MyModelToolParser
3. 实现名为my_tool_agent的Multi Turn Agent: MyToolAgentLoop。在类初始化时,通过配置实例化定义的工具(MyWebSearchTool)和实例化ToolParser类(MyModelToolParser)
4. 实现名为my_reward_manager的MyWebSearchRewardManager
5. 自定义了Reward Score的计算方法: compute_score
接下来就是如何通过配置化方式,把上面这些实现串接起来。首先看下如何对我们的task prompt指定上述实现的Rollout方式(MyToolAgentLoop)
在每条样本中,增加一个"agent_name"key,具体值配置成步骤5实现的AgentLoop的注册name(my_tool_agent)。
如下一条样本:增加"agent_name":"my_tool_agent" 键值对,来指定rollout的执行逻辑。
{
"agent_name":"my_tool_agent",
"data_source":"nq",
"prompt":[
{
"content":"You are a helpful and harmless assistant.",
"role":"system"
},
{
"content":"Answer the given question. You must conduct reasoning inside <think> and <\/think> first every time you get new information. After reasoning, if you find you lack some knowledge, you can call a search engine by <tool_call> query <\/tool_call> and it will return the top searched results between <tool_response> and <\/tool_response>. You can search as many times as your want. If you find no further external knowledge needed, you can directly provide the answer inside <answer> and <\/answer>, without detailed illustrations. For example, <answer> Beijing <\/answer>. Question: total number of death row inmates in the us?",
"role":"user"
}
],
"ability":"fact-reasoning",
"reward_model":{
"ground_truth":{
"target":[
"2,718"
]
},
"style":"rule"
},
"extra_info":{
"index":0,
"question":"who got the first nobel prize in physics?",
"split":"train"
}
}
最后我们通过在总控脚本中,把上述所有的实现通过配置化串到整个训练流程里。
在verl根目录新建总控执行脚本:run_train_main.sh,相关配置如下
TOOL_CONFIG="${ROOT_DIR}/examples/sglang_multiturn/config/tool_config/my_web_search_tool.py"
REWARD_PATH="${ROOT_DIR}/verl/utils/reward_score/my_reward_function.py"
python3 -m verl.trainer.main_ppo \
......
actor_rollout_ref.rollout.multi_turn.max_assistant_turns=3\
actor_rollout_ref.rollout.multi_turn.max_parallel_calls=3\
actor_rollout_ref.rollout.multi_turn.tool_config_path=${TOOL_CONFIG}\ # 配置步骤(3)的工具
actor_rollout_ref.rollout.multi_turn.format=hermes \ # 配置步骤(4)的ToolParser
actor_rollout_ref.rollout.name=sglang \
actor_rollout_ref.rollout.mode=async \
......
reward_model.reward_manager=my_web_search \ #配置步骤(6)自定义的RewardMeneger
custom_reward_function.path=${REWARD_PATH}\ #配置步骤(7)自定义的reward fucntion 文件
custom_reward_function.name=compute_score \ #配置步骤(7)自定义的reward fucntion 函数名经过上面一通操作,我们完整的实现了一个完整Agentic RL流程,总结下所有的修改,如下:
https://github.com/volcengine/verl/tree/main/verl
verl_project_root/
├── run_train_main.sh # 开发自己的训练总控脚本
├── verl/
│ ├── tools/
│ │ ├── web_search.py # 模拟API搜索工具(替换成自己真实的API)
│ │ ├── my_web_search_tool.py # 自定义工具
│ ├── experimental/
│ │ ├── agent_loop/
│ │ │ ├── tool_parser.py # 自定义tool parser
│ │ │ ├── my_tool_agent_loop.py # 自定义AgentLoop
│ │ ├── reward_loop/
│ │ │ ├── reward_manager/
│ │ │ │ ├── my_web_search_reward_manager.py # 自定义reward manager
│ ├── utils/
│ │ ├── reward_score/
│ │ │ ├── my_reward_function.py # 自定义Reward Function
├── examples/
│ ├── sglang_multiturn/
│ │ ├── config/
│ │ │ ├── tool_config/
│ │ │ │ ├── my_web_search_tool_config.yaml # 自定义工具配置化描述07 总结
VERL真的很重,整理这块费了不少时间,虽然有些流程很绕,但里面的设计模式还是比较优雅的。目前在VERL里还有个高级的Feature: TransferQueue高性能的数据存储与传输模块,TransferQueue 将数据管理与数据存储解耦,使得服务之间只需传递数据引用,而实际数据则通过点对点方式直接获取。这种设计显著减少了数据传输的开销,提高了系统的整体效率。










