绑定手机号
确认绑定









作者:笨鸟先飞
地址:https://zhuanlan.zhihu.com/p/1995208571181367796
经授权发布,如需转载请联系原作者
在大模型训练推理过程中,有时会遇到“GPU 算力还没跑满,为什么服务就先被显存卡死了?”的问题。但其实,线上跑大模型卡住,很多时候不是“算不动”,而是 KV Cache 被“内存碎片化”和“预分配浪费”给拖垮了。PagedAttention 的核心就是:不是给每个请求硬塞一整段连续显存,而是“按块领用 + 用表映射”,像操作系统分页一样管理显存,用逻辑连续来代替物理连续。
01 问题本质是什么?
进一步展开“跑大模型卡住”的问题,如果遇到了以下类似现象,十有八九就是 KV 在作怪。
1)显存看着还有,但就是 OOM。问题本质是显存被碎片化,凑不出一大段连续的空间。具体的说,就是请求长度/生命周期都不一致,显存会被切得像蜂窝煤,看到“显存很满”,其实很多都是“拼不起来的大空洞 + 为最坏情况预留的空间”。
2)一开长上下文,或一提并发,吞吐断崖。问题本质是KV 随并发 B 和 上下文 T 线性膨胀。具体的说,就是模型为了下一步更快,把“历史注意力需要的 Key/Value 备忘录”一直放在显存里,历史越长、同时服务的人越多,这份备忘录就越大。
3)GPU 利用率不高,但吞吐上不去。问题本质不是算力遇到瓶颈,而是“能驻留的 KV 数量”遇到瓶颈。具体的说,就是 KV Cache 是自回归推理的结构性成本,KV Cache 的成本近似线性膨胀,系统往往没法在一张卡上同时“驻留”足够多的序列来把 batch 做大,于是算子本身还没跑满,吞吐就先被“显存能装下多少 KV”卡住了。更糟一点是,通常还要给权重、workspace、prefill 激活等留空间,留给 KV 的额度更小,这个瓶颈会更早出现。
02 传统做法为什么容易“翻车”?
传统实现常见思路是每个请求分一段“连续大内存”装 KV,后续 token 依次往后写。此做法在离线推理(长度固定、批次固定)中尚可;在线服务(prompt和生成内容长短不一、请求接收和结束时间不一致、为提升吞吐连续批处理)中就会出现两类浪费:
外部碎片——空闲显存被切成很多小洞。
预留浪费——因为担心 OOM,就按“最大可能长度”先预留一大段,结果大部分时间都空着。
03 PagedAttention 与传统做法
有何差异?是如何改进的?
PagedAttention 做法的核心思路是别执着于物理连续,用逻辑连续来代替,把 KV 变成“块池 + 块表”。
PagedAttention 与传统做法的核心差异如下:
连续分配——可类比成“给定一整条长桌,桌子必须完整真实连接”。
分页块池——可类比成“给定一堆乐高块 + 一张说明书,拼出来看着连续就行”。
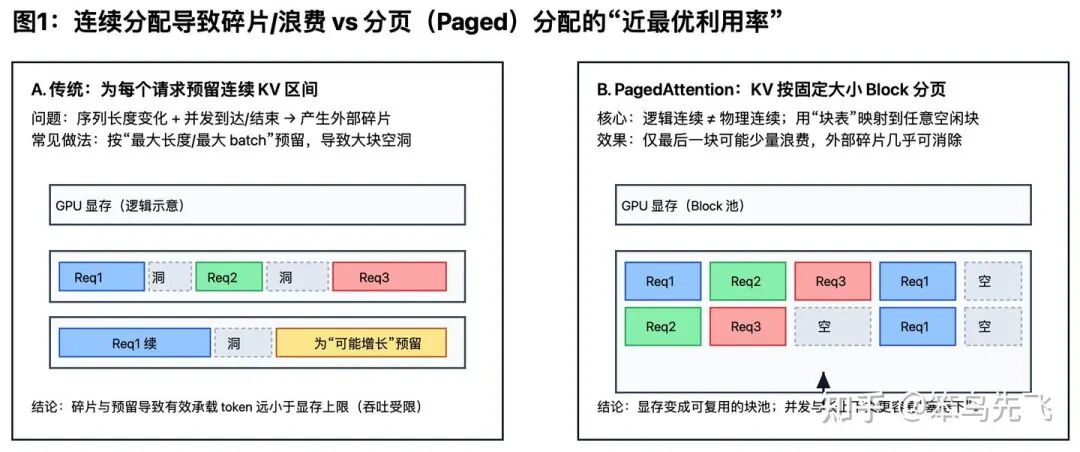
PagedAttention 做法的实现细节如下:
1)把 KV 切成固定大小的“小块”(block/page)。
2)维护一个“块表”(block table):把“逻辑上连续的 token 序列”映射到“物理上不连续的显存块”。
3)显存变成一个“可复用块池”:请求来了就领几块,用完就还回去。
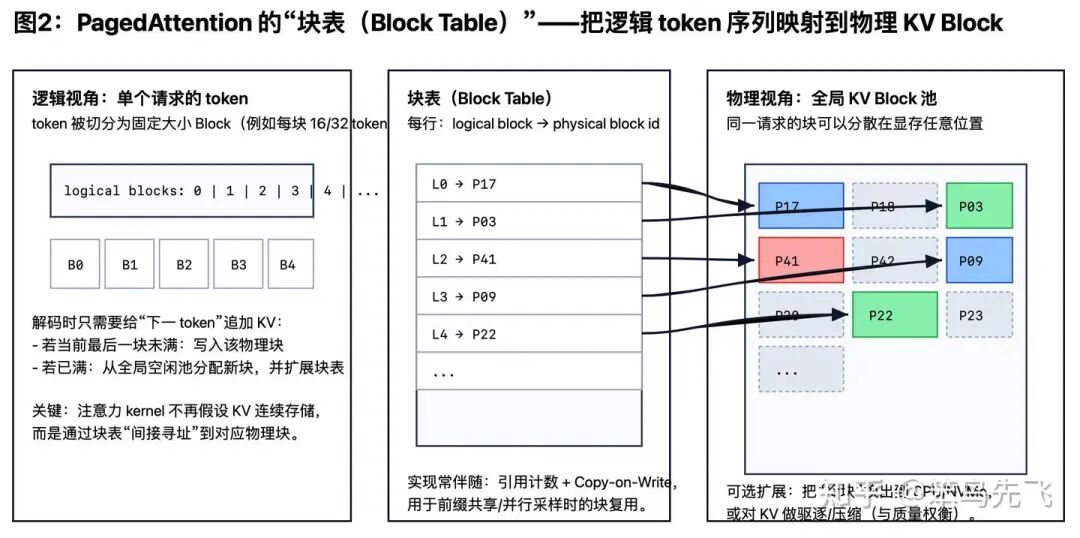
分页带来的最直观收益是:浪费上界从“跟最大长度/最大并发绑定”,变成“最多浪费最后一块没填满的(一个块的大小)”。
04 PagedAttention 为什么能让“多分支/并行采样”不再爆显存?
技术突破:前缀共享 + COW。
实际应用场景中常出现:同一个 prompt 想要多条结果(并行采样、beam、speculative 相关路径)。如前文所述,如果“每条分支都复制一份完整 KV”,显存会随分支数线性爆炸。
PagedAttention 做法更像“共享 + 引用计数 + 需要时才复制”。具体如下:
共享前缀——多个分支的块表可以指向同一批“前缀块”(refcount 增加)。
大多数 decode 只追加——历史 KV 很少被改动,所以共享通常很安全。
Copy-on-Write(COW)——真遇到要改共享块(回滚/重排/删除/重写),才分配新块并复制,且只影响那个分支。
下图概括了“前缀共享 + 引用计数 + COW”的效果:多分支共享同一份前缀 KV,仅在需要“写入共享块”时才触发拷贝(该机制在 vLLM 的 PagedAttention 论文中有系统描述[1])。
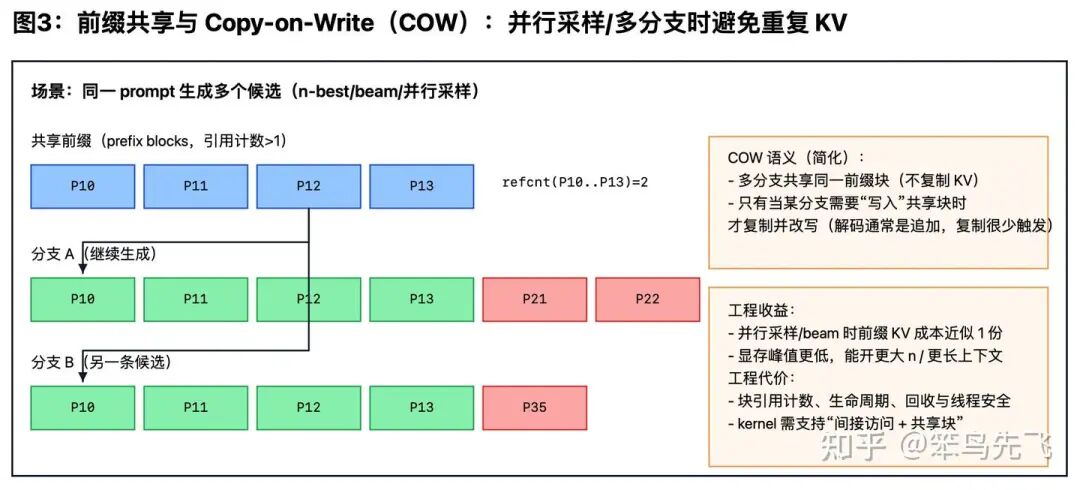
一句话总结:能共享就共享,真要写才复制。
05 PagedAttention 为什么
与连续批处理是“绑定”的?
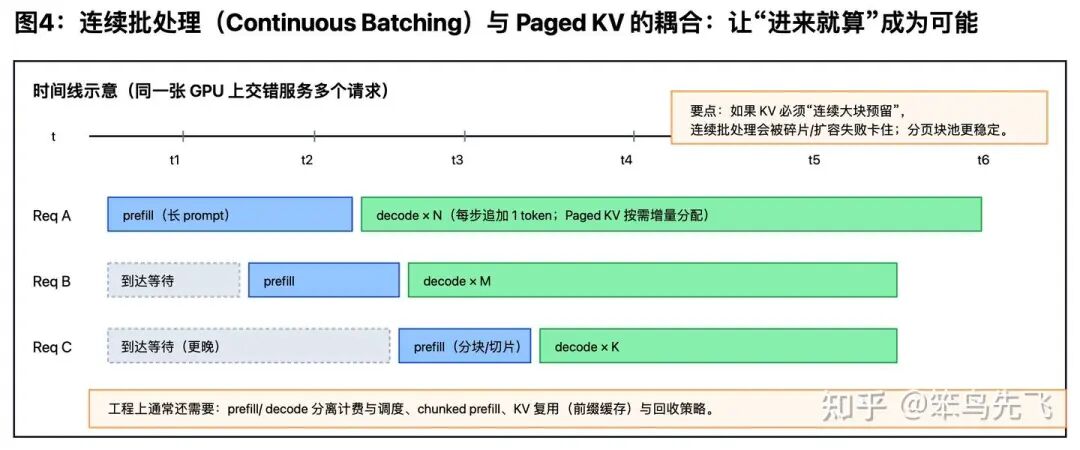
连续批处理(continuous batching)的机制是 batch 不再是“固定一起跑的一批请求”,而是“这一小步需要生成 token 的序列集合”。
这会让“驻留在 GPU 上的序列集合”一直变化,连续大块分配更容易碎;块池按块领用反而稳定。 “新增块数 / 新增 token 数”的结果突然变高,一般意味着:并发太高、很多序列卡在块边界,或块太小导致分配频繁——这时就该触发“显存治理”策略(限流/降并发/限制并行分支/优先跑短序列等)。
06 代码示例:块池 + 块表 + 映射读取
本节参考阿里云文章中的实现思路[12],说明 PagedAttention “分页块池 + 逻辑到物理映射 + 按需分配/回收/读取”这几个关键步骤的代码框架。可以把它理解为:把 KV 从“每序列一段连续数组”,改成“全局块池 + 每序列一张页表”。
1. 核心数据结构:物理块(KVBlock)
class KVBlock:
"""物理块:固定 block_size 的 KV 存储单元(可来自 GPU 显存池)"""
def __init__(self, block_id: int, block_size: int, num_heads: int, head_dim: int):
self.block_id = block_id
self.block_size = block_size
self.k = torch.empty((num_heads, block_size, head_dim), dtype=torch.float16)
self.v = torch.empty((num_heads, block_size, head_dim), dtype=torch.float16)
self.ref_count = 0 # 前缀共享/多分支共享的关键
def write_at(self, offset: int, k_t: torch.Tensor, v_t: torch.Tensor):
self.k[:, offset] = k_t
self.v[:, offset] = v_t2. 核心映射:序列页表(BlockTable)
页表把“逻辑 token 位置(virtual position)”映射到“物理块 + 块内偏移(physical block, offset)”:
class BlockTable:
"""每个序列一张页表:维护 logical_position -> (block_id, offset)"""
def __init__(self, block_size: int):
self.block_size = block_size
self.blocks: list[KVBlock] = [] # 逻辑顺序的块列表
def ensure_capacity(self, allocator, seq_len: int):
"""按需分配到能覆盖 seq_len 个 token(只在越过块边界时领新块)"""
need_blocks = (seq_len + self.block_size - 1) // self.block_size
while len(self.blocks) < need_blocks:
self.blocks.append(allocator.acquire())
def locate(self, pos: int) -> tuple[KVBlock, int]:
"""把逻辑位置映射到 (物理块, 块内偏移)"""
b = pos // self.block_size
off = pos % self.block_size
return self.blocks[b], off3. 全局块池:分配/回收(Allocator)
class BlockAllocator:
"""全局块池:free-list 管理,避免频繁 cudaMalloc/cudaFree 与碎片化"""
def __init__(self, blocks: list[KVBlock]):
self.free = blocks[:] # 简化:实际工程里会更复杂(分层、统计、并发保护等)
def acquire(self) -> KVBlock:
assert self.free, "OOM: no free KV blocks"
blk = self.free.pop()
blk.ref_count = 1
return blk
def release(self, blk: KVBlock):
blk.ref_count -= 1
if blk.ref_count == 0:
self.free.append(blk)4. 写入与注意力读取:用“映射”替代“连续地址”
写入(decode 每步追加 token):
def append_token_kv(block_table: BlockTable, allocator: BlockAllocator, pos: int, k_t, v_t):
block_table.ensure_capacity(allocator, seq_len=pos + 1)
blk, off = block_table.locate(pos)
blk.write_at(off, k_t, v_t)读取(attention 需要历史 KV):按页表把若干块拼接/聚合成 K/V 视图(这里省略 kernel 细节,只表达数据来源关系):
def gather_kv(block_table: BlockTable, positions: list[int]):
blocks_and_offsets = [block_table.locate(p) for p in positions]
# 实际实现会把 (block_id, offset) 喂给 kernel 做高效 gather / page-attention
return blocks_and_offsets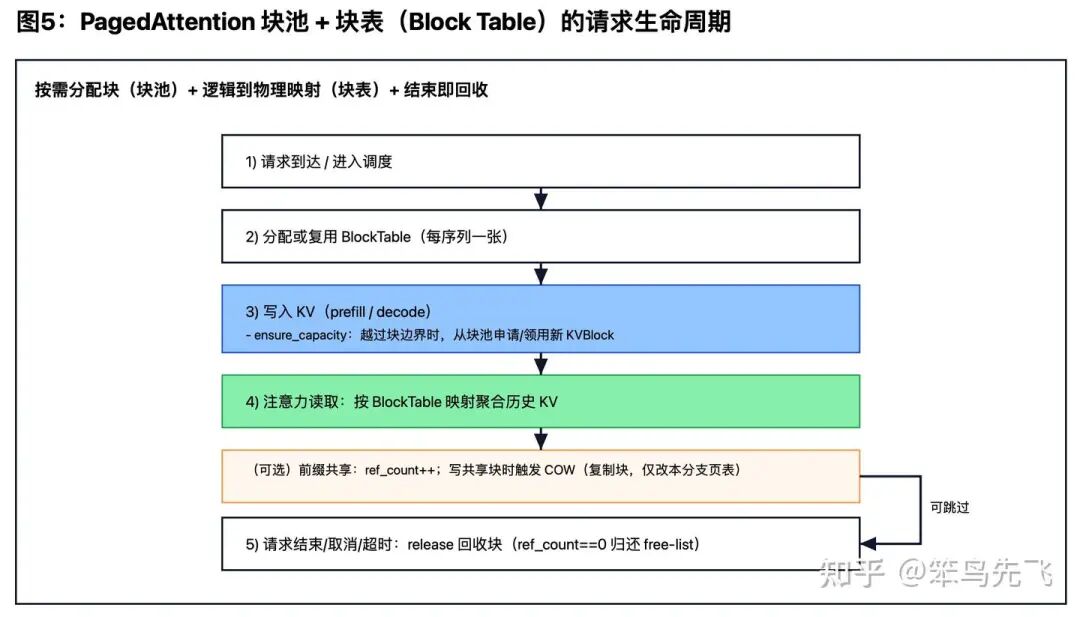
07 总结
线上大模型推理的瓶颈常常不在算力,而在 KV Cache 的显存占用、碎片化与“按最坏情况预留”带来的浪费;并发 B 和上下文长度 T 增长会让 KV 成本近似线性膨胀,从而提前卡住吞吐与稳定性。
而 PagedAttention 不再为每个请求分配“物理连续的大段显存”,是把 KV 切成固定大小的 块(page/block),用 块表(block table) 维护“逻辑连续 token”到“物理不连续显存块”的映射,让显存变成 全局可复用的块池,按需领取、用完归还。显存浪费的上界从“与最大长度/最大并发绑定”,转为 “最多浪费最后一个未填满的块”;同时显著缓解外部碎片问题,使得在更长上下文与更高并发下,KV Cache 也能更稳定地驻留在 GPU 上。
总体来说,PagedAttention 解决的重点不是“注意力算得更快”,而是把 KV 显存从一次性消耗品变成可计量、可复用、可治理的资源,从而让服务在高并发与长上下文场景下更加稳定。
参考文献
[1]: Kwon, W. et al. Efficient Memory Management for Large Language Model Serving with PagedAttention(vLLM). arXiv:2309.06180.https://arxiv.org/abs/2309.06180[2]: Dao, T. et al.FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv:2205.14135.https://arxiv.org/abs/2205.14135[3]: Dao, T. et al.FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. arXiv:2307.08691.https://arxiv.org/abs/2307.08691[4]: Microsoft Research.vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention. arXiv:2405.04437.https://arxiv.org/abs/2405.04437[5]: Ye, Z. et al.FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving. arXiv:2501.01005.https://arxiv.org/abs/2501.01005[6]: Joshi, T. et al.Paged Attention Meets FlexAttention: Unlocking Long-Context Efficiency in Deployed Inference. arXiv:2506.07311.https://arxiv.org/abs/2506.07311[7]: Liu, M. et al.Hold Onto That Thought: Assessing KV Cache Compression On Reasoning. arXiv:2512.12008.https://arxiv.org/abs/2512.12008[8]: Vaswani, A. et al.Attention Is All You Need. arXiv:1706.03762.https://arxiv.org/abs/1706.03762[9]: vLLM Documentation(持续更新). https://docs.vllm.ai/[10]: NVIDIA.TensorRT-LLM(持续更新). https://github.com/NVIDIA/TensorRT-LLM[11]: SGLang Project(持续更新). https://github.com/sgl-project/sglang[12]: 阿里云开发者社区.大模型推理加速技术:PagedAttention原理与实现. https://developer.aliyun.com/article/1685154










