绑定手机号
确认绑定









作者:李安渝
地址:
https://zhuanlan.zhihu.com/p/1993730995959111789
经授权发布,如需转载请联系原作者
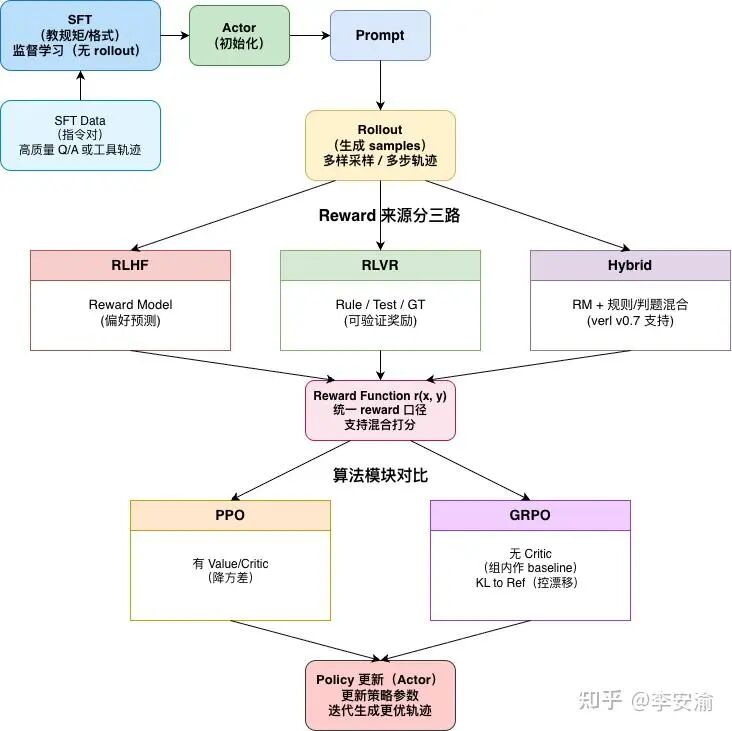
从年初 Manus 等通用/多步执行型 Agent 的走红,到随后各类垂直领域 Agent 在各个等场景加速落地,大家越来越多人把 2025 称作 “Agent 元年”:一方面,应用侧的产品形态和交付方式在快速迭代;另一方面,大家也开始重新审视能力从哪来——单靠预训练堆数据、堆算力,已经很难继续拉开代差。与这波应用热潮几乎同步升温的,是 Infra 侧的强化学习(RL)。大模型的竞争焦点正逐步从 Pre-training迁移到 Post-training:如何让模型不仅“会说话”,还能在复杂任务中“会思考、会决策、会自我纠错”?RL 提供了一条可规模化的路径。但现实是,大模型 RL 训练早已不是跑个脚本——它更像一项推理系统 + 训练系统耦合的复杂工程:既要在 Rollout 阶段榨干吞吐,又要在 Train 阶段承受重反传与重通信,最终演变成一门真正的分布式系统工程。
01 从 RLHF 到 RLVR
预训练像“把百科全书背进脑子”,SFT 像“统一答题格式”,而 RL 更像“刷题 + 复盘”:刷得越多、复盘越狠,模型越可能学会把推理步骤当成一种可迁移技能。 但前提是:你得先搞清楚 RL 的奖励到底来自哪里——奖励信号的性质,会直接决定你系统的形态。所以这一节我们来讲一下强化学习reward的来源和强化学习核心算法。
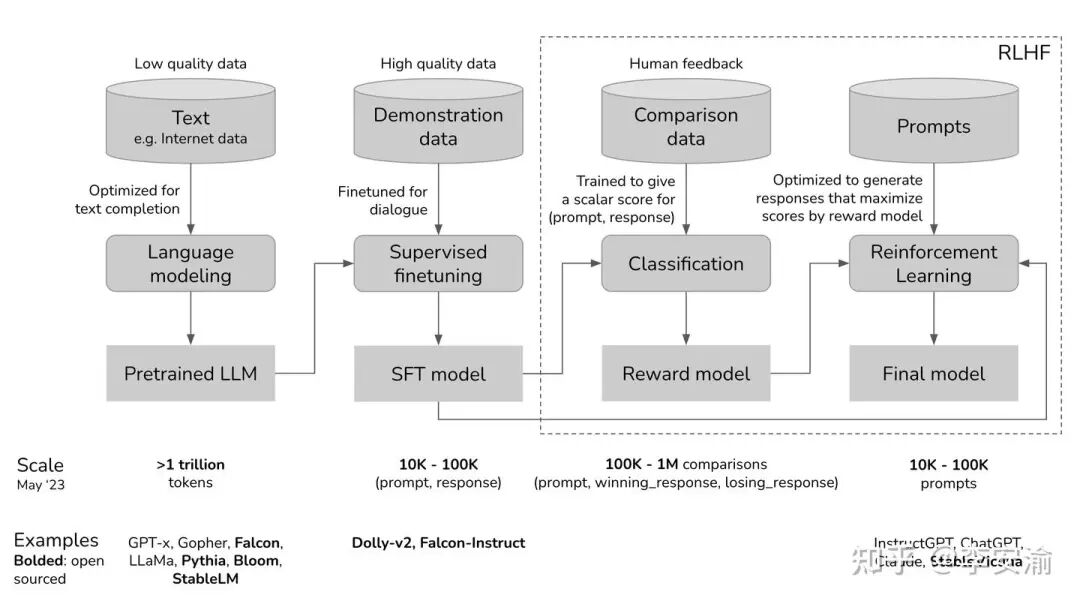
监督微调(Supervised Fine-Tuning, SFT):既然是“监督”,就意味着这一阶段需要带“标签”的数据。在大模型领域,这类数据通常叫指令跟随数据(Instruction-Following Data) 或 示范数据,常见格式是[x,y]:
x:Prompt / 指令(可能包含上下文、角色设定、工具状态等)
y: Response / 示范答案(可以是自然语言,也可以是代码、JSON、工具调用等结构化输出) 一句话概括,SFT 的目的就是把预训练阶段“会接龙”的模型,通过高质量示范收束成一个“会按指令办事”的模型。因为在预训练(Pre-training)阶段,LLM 学到的主要是对海量文本分布的拟合:给定一段文本,它能生成在语料分布上合理的后续内容,但它并不天然知道用户期待的回答形态和任务意图,比如是否需要分步骤、是否需要总结、是否要遵循特定输出格式、遇到不确定信息是否要明确说明等。以“如何制作一块披萨”为例,预训练模型可能接出“for 生日派对”“以及一份蛋糕”这类语言上能接得上的续写,也可能给出“第一步:你需要……”这种真正满足指令意图的回答;SFT 正是通过大量 [Prompt,Response]S示范持续强化后一类回答模式,让模型在同类指令下更倾向输出对人类来说“可用、可读、可执行”的结果。 从优化目标来看,SFT 本质上仍是条件语言建模的最大似然训练:最大化示范答案在模型下出现的概率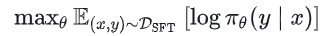 ,等价地也可以写成最小化负对数似然损失
,等价地也可以写成最小化负对数似然损失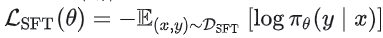 ,由于高质量指令数据往往难以直接从网络爬取,通常需要人类标注或人类审核(human-in-the-loop),因此单位成本显著高于第一阶段的海量无标注语料。完成这一阶段后得到的模型通常称为 SFT Model/指令模型,它不仅为后续强化学习提供一个“已经比较像样”的策略起点(Actor 初始化),还常被作为冻结的参考策略
,由于高质量指令数据往往难以直接从网络爬取,通常需要人类标注或人类审核(human-in-the-loop),因此单位成本显著高于第一阶段的海量无标注语料。完成这一阶段后得到的模型通常称为 SFT Model/指令模型,它不仅为后续强化学习提供一个“已经比较像样”的策略起点(Actor 初始化),还常被作为冻结的参考策略![]() 用于后续 RL 阶段的 KL 约束,帮助训练过程在追求更高奖励的同时保持输出分布稳定,避免策略更新跑偏。
用于后续 RL 阶段的 KL 约束,帮助训练过程在追求更高奖励的同时保持输出分布稳定,避免策略更新跑偏。
基于人类反馈的强化学习(RLHF): 一句话概括,RLHF 先用人类偏好训练一个“打分器”(Reward Model),再用强化学习让模型最大化这个打分,同时用 KL 约束把模型“拽住”。那已经有了一个监督阶段了为啥还需要基于人类反馈的阶段呢?这是因为SFT 给模型的是“示范答案”,但现实中“好答案”不只一个。对于很多开放式任务(写作、对话、解释、建议),存在大量同样合理的回答方式。SFT 往往只拟合了数据里那种“写法”,在复杂场景里可能不够灵活。 RLHF 的核心优势在于:
让模型先 采样 多个可能的回答(exploration)
再由偏好模型告诉它“哪个更好”(更细粒度的学习信号)
因此在实践中,经常看到 SFT + RLHF 的效果优于单纯 SFT。SFT 让模型“像样地回答”,RLHF 让模型“更符合人类偏好”。SFT 同时提供了后续 RL 的两个关键锚点:Actor 初始化与Reference policy。在 RLHF 中,Reward Model 负责把偏好信号转成可优化的标量 reward,而 KL 约束负责避免策略漂移和 reward hacking。
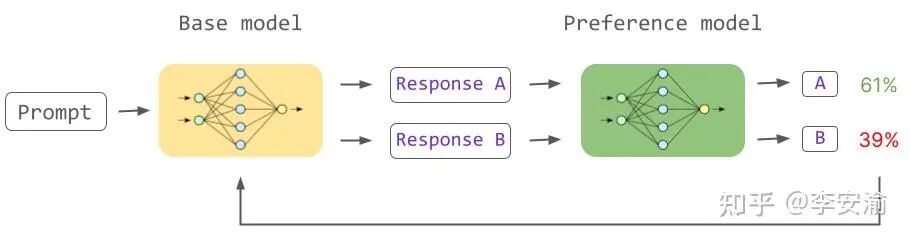
RLHF 的标准流程分为两步 :
(1)第一步是训练奖励模型(RM):RM 的输入是一段文本(prompt+response),输出是一个标量分数。偏好数据通常是三元(x,y+,y−),表示同一个prompt,大家更喜欢y+这个答案,对于另一个答案偏好程度没有那么大。 常见的 RM 训练目标: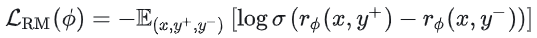 。直观理解:我们希望 RM 让“更受偏好”的回答得分更高,“不受偏好”的回答得分更低。 工程上,RM 往往用 SFT 模型拷贝一份初始化参数,因为 RM 至少需要具备与 Actor 相当的语言理解能力,否则打分会非常不稳定。
。直观理解:我们希望 RM 让“更受偏好”的回答得分更高,“不受偏好”的回答得分更低。 工程上,RM 往往用 SFT 模型拷贝一份初始化参数,因为 RM 至少需要具备与 Actor 相当的语言理解能力,否则打分会非常不稳定。
(2)第二步是更新Actor模型(常见算法后面会有提到) 给定 prompt,当前策略![]() 采样得到回答 ,RM 给出分数
采样得到回答 ,RM 给出分数![]() 。我们希望更新
。我们希望更新![]() ,让期望得分更高。
,让期望得分更高。
具有可验证奖励的强化学习(RL with Verifiable Rewards):可以理解为后训练流程里新增的一块“硬信号”:在数学、代码等可验证环境中,模型生成回答后可以用规则/标准答案/判题器/单元测试自动判定对错,从而得到更稳定的奖r(x,y)。相比 RLHF 依赖人类偏好训练出来的 Reward Model,RLVR 的奖励更“客观”、更容易规模化,因此可以把大量算力投入到更长时间的在线强化学习与更大规模的 rollout 上,让模型在持续试错中自发形成更可靠的推理策略(例如更愿意拆解步骤、进行中间验证)从而涌现出思维链(CoT)。从优化形式上看,RLVR 和 RLHF 类似,都是最大化奖励并用 KL 正则把策略“拽住”,只不过这里的 reward 来自可验证函数而非 RM: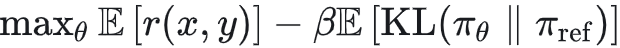 。同时,RLVR 还带来一个新的“调参旋钮”:通过生成更长的推理轨迹、投入更多“思考 token”(测试时算力),往往能进一步提升通过率——这也是推理模型与传统指令模型在体验上拉开差距的关键来源之一。
。同时,RLVR 还带来一个新的“调参旋钮”:通过生成更长的推理轨迹、投入更多“思考 token”(测试时算力),往往能进一步提升通过率——这也是推理模型与传统指令模型在体验上拉开差距的关键来源之一。
02 RL算法
前面讲到了RLHF里面会更新Actor模型 ,那具体怎么更新呢,这就涉及到各种更新算法,也就是如何用这些采样样本,做一个稳定、可重复、多轮迭代的策略更新。
,那具体怎么更新呢,这就涉及到各种更新算法,也就是如何用这些采样样本,做一个稳定、可重复、多轮迭代的策略更新。
一种具体的、基于策略梯度(Policy Gradient)的强化学习优化算法。On-Policy / Near On-Policy:通常采用“采样一批轨迹 → 对这批数据做多轮 mini-batch 更新”的交替流程。
Actor-Critic:需要同时训练策略网络(Actor)和价值网络(Critic/Value head),用 value 作为 baseline 来计算 advantage、降低梯度方差。 PPO 的核心思想是:我可以用旧策略![]() 采样出一批数据,然后对新策略
采样出一批数据,然后对新策略![]() 做多轮 mini-batch 更新,但每一步更新都不能离旧策略太远。PPO用一个重要性采样比值来衡量“新旧策略差多少”:
做多轮 mini-batch 更新,但每一步更新都不能离旧策略太远。PPO用一个重要性采样比值来衡量“新旧策略差多少”: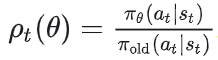 。 通过截断(Clip)限制每次参数更新的幅度,从而间接约束策略更新的激进程度、防止训练不稳定:
。 通过截断(Clip)限制每次参数更新的幅度,从而间接约束策略更新的激进程度、防止训练不稳定: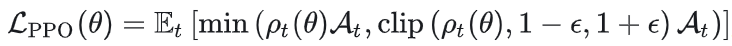 , 这里的
, 这里的![]() 是优势函数(advantage),衡量“这个动作相对 baseline 的好坏”(常见做法是
是优势函数(advantage),衡量“这个动作相对 baseline 的好坏”(常见做法是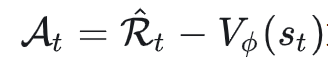 或用 GAE 来估计)。
或用 GAE 来估计)。
在instructGPT时代,RLHF=SFT+RM+PPO,但在推理/RLVR(verifiable rewards)这类序列级奖励更常见的设置里,训练一个能在每个 token 上都稳定工作的 value function(critic)既贵又难,因此一些工作(如 DeepSeekMath)提出用 GRPO 作为 PPO 的变体:保留 PPO-style 的近端更新,但用“组内相对优势”替代 critic 估计 advantage,从而显著降低训练侧负担。 GRPO 的出发点非常直接:对同一个 prompt采样一组答案![]() ,得到对应的
,得到对应的 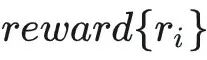 ,然后把每个样本的 advantage 设为组内归一化的相对收益:
,然后把每个样本的 advantage 设为组内归一化的相对收益:
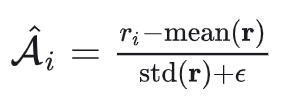
接下来更新策略时,仍然用 PPO-style 的 clipped objective(本质上还是“近端更新”),只是 advantage 不再来自 critic,而来自组内相对比较。这就是 GRPO 能显著降低训练侧负担的根因:省掉了 value/critic 的训练与通信成本,把压力更多推给 rollout(需要更大 group、更高并发采样)。这一点在 DeepSeekMath 等工作中被明确提出:GRPO 是 PPO 的变体,核心是“组相对优势”替代 value function。
所以结合上两节的内容, 模型后训练时候的数据大致如下图所示:
03 Infra 的核心挑战:精神分裂的“混合负载”
如果说预训练是一台稳定运转的“重型压路机”,那 RL 训练更像一条随时变速的生产线:同一个模型在一个循环里要反复扮演两种角色——Rollout 时像线上服务一样疯狂吐 token,Train 时像预训练一样做重反传、重通信。这就是所谓的混合负载(Hybrid Workload),也是 RL Infra 真正的难点来源:你不是在优化一个系统,而是在优化两个系统之间的切换成本和流水线效率。
先看 Rollout 阶段。它本质上是推理(inference)工作负载,目标是把吞吐榨干:你要尽可能高并发地生成样本,通常还要做带温度的采样、生成更长的推理轨迹(CoT)、甚至对同一个 prompt 采样一组候选(比如 GRPO 的 group sampling)。
任务:模型扮演“考生”,疯狂做题。
关键技术:KV Cache、Continuous / Dynamic Batching、Tensor Parallel(TP)(以及更细的 prefill/decode 调度)。
引擎选择:vLLM、SGLang 等。
在这一侧,显存里最“值钱”的东西不是优化器状态,而是 KV Cache:它会随着并发数和生成长度增长,直接决定你能不能把 token/s 拉起来。因此推理引擎更倾向于用 serving 体系,把动态批处理、KV 管理、以及推理并行(如 TP)做到极致——追求的是“像线上服务一样稳定、高吞吐、还能顶住长尾请求”。
但 Train 阶段完全是另一个世界。它是训练(training)工作负载,显存里更“沉”的是 参数 / 梯度 / 优化器状态(再加上长序列下的 activation)。尤其 Adam 类优化器会引入额外的状态张量,使训练态的显存占用与通信开销显著上升。于是训练引擎会倾向于用 ZeRO-3 / FSDP 这类切片策略,把参数、梯度和优化器状态分散到多卡上,靠重通信换取可训练的模型规模。更麻烦的是:为了训练稳定,你往往还要更大的 batch、更长的序列、更频繁的梯度同步——这和 Rollout 侧“把 KV 留住、把吞吐榨干”的目标天然冲突。
Train 阶段(学习)
任务:模型扮演“学生”,根据错题本更新脑子。
关键技术:Backpropagation、Optimizer States、ZeRO-3 / FSDP(以及 activation checkpointing 等)。
引擎选择:PyTorch 生态(Megatron / DeepSpeed / FSDP 等)。
同一个模型,在这两种阶段的“权重布局/并行形态”往往不一致。训练侧常以 ZeRO/FSDP 为核心做切片,推理侧常以 TP/PP 为核心追求算子效率与稳定吞吐。于是每次从 Train 切到 Rollout,你都面临一个本质问题:模型权重到底以什么布局存在?如果训练态与推理态布局不一致,就不可避免要经历一次重分片(resharding)/参数同步/权重广播;反过来从 Rollout 回到 Train,你还要把生成出来的轨迹、logprob、reward 等信号组织成训练可用的 batch,并处理长度不一、长尾请求带来的 padding/packing,以及 token-level 的 mask/logprob 对齐问题。很多“跑不满卡”的 RL 训练,瓶颈并不是算力,而是这些阶段切换与数据重排的隐性开销。
此外,混合负载还会带来一个典型的调度难题:Rollout 存在长尾(long tail)。同一批 prompt 里,有的样本很快结束,有的样本因为长推理链路、工具调用或采样策略拖很久。如果你采用同步(synchronous on-policy)训练,训练端经常会因为等最慢的那几个 rollout 而空转;如果你改成异步(async / disaggregated)让 rollout 和 training 流水线并行,又会引入新的系统复杂度:参数同步频率、策略陈旧(staleness)对收敛的影响、队列拥塞与背压、失败重试、指标对齐与可复现性都会变得更难控。也就是说,同步会浪费吞吐,异步会增加复杂度。
RL infra 的本质不是训练,而是把推理系统和训练系统拼成一条不漏水的流水线。
04 verl——把“推理系统 + 训练系统”粘成一条流水线
前面说过:RL infra 的本质不是“把训练写得更快”,而是把推理系统和训练系统拼成一条不漏水的流水线。字节跳动开源的 verl 就是在做这件事——它不强行把训练和推理揉成同一种并行形态,而是承认二者天然不同:训练侧擅长重反传+重通信(FSDP/Megatron),推理侧擅长高吞吐+长尾调度(vLLM/SGLang)。verl的价值在于:在两套系统之间搭“桥”,把最痛的数据流和参数流接起来,同时把长尾 rollout 的吞吐问题纳入系统设计。 从架构上看,verl分两层:底座是 verl-core(四大组件),上层是 verl-trainer(把组件拼成 on-policy / one-step-off-policy / fully async 等 pipeline)。你可以把它理解成“HybridFlow / Hybrid-Controller”:上层像调度员一样编排流程,下层各引擎在各自最擅长的模式里跑满算力。一个很典型的趋势是:rollout 正从 SPMD 形态迁移到更像线上 serving 的 server mode——这对多轮对话、tool calling、长尾请求更友好,也更贴近真实推理负载。
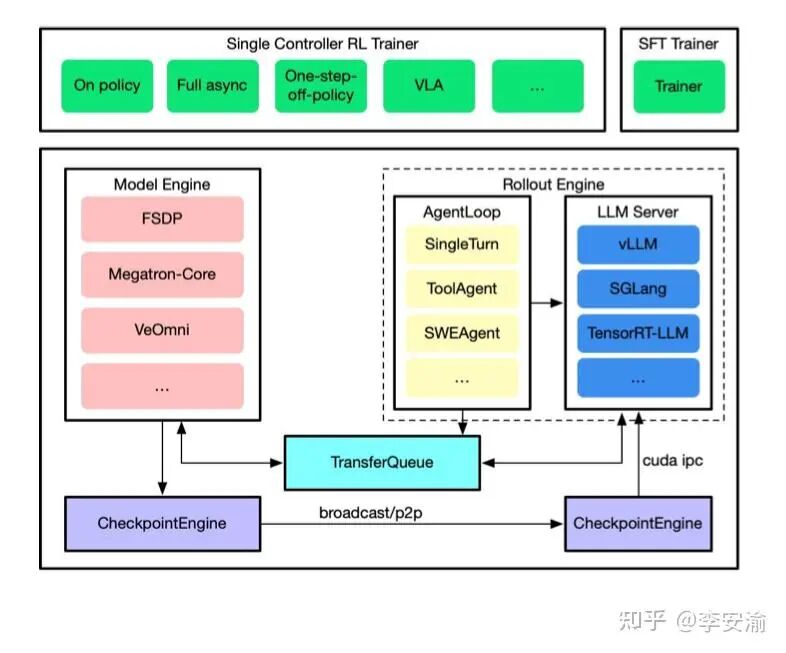
落到实现,verl-core 的“四大金刚”可以这样记:
Model Engine(炼丹炉):把训练侧后端封装成统一接口,屏蔽 FSDP/并行切片/通信细节,让上层 trainer 关注“RL 控制逻辑”而不是“训练工程细节”。
Rollout Engine(加特林):把推理侧做成更接近 server 的形态(动态 batching、KV 管理、并行推理),并通过 AgentLoop把“单轮生成/多轮推理/工具调用”这些 rollout 控制逻辑收敛成可复用的循环。
TransferQueue(物流枢纽):这是“工业味”的关键。它重点解决的是数据流:把 rollout 产生的轨迹、logprob、reward 等训练数据稳定、高吞吐地送到训练侧,同时避免“所有数据都绕过单点控制器”导致的瓶颈。你可以把它当成 RL 流水线里的“传送带 + 缓冲仓”,负责削峰填谷、解耦长尾。
Checkpoint Engine(参数流阀门):在训练与 rollout 物理分离(disagggated)之后,最难的是参数流:训练侧更新得很快,但 rollout 侧必须持续拿到足够新的策略参数。verl把这件事抽象成可控的同步/传输机制(例如基于 NCCL 的同步),让“参数更新”变成持续流动,而不是每轮都停下来“写盘—读盘—重启”。 当这四个组件齐了,verl-trainer 才能拼出不同运行形态:
同步 on-policy:简单但容易被 rollout 长尾拖慢;
one-step-off-policy:用“一步陈旧”换吞吐;
fully async:把 rollouter 与 trainer 彻底解耦,数据流走 TransferQueue 不间断,参数流走 CheckpointEngine 持续更新,把混合负载真正改造成可并行的生产线。 最后提醒一个常见误区:很多人用 “SPMD vs MPMD” 来讲“同卡/分离”,其实更清晰的轴是 Colocate(同位切换) vs Disaggregated(资源池分离)。前者省带宽但切换成本高(清 KV/清优化器状态);后者能流水并行、吞吐更高,但需要更强的参数同步与队列治理。verl 的核心贡献,就是把这条权衡做成工程化的可选项——你不再手搓“训推粘合层”,而是在一套组件上切换不同 pipeline。
05 性能优化:对抗“长尾效应”的黑科技
随着 GRPO / RLVR 对 Rollout 吞吐的要求越来越高(尤其是 group sampling:同一个 prompt 需要采样多条候选来做相对优势),Rollout 正在成为端到端迭代里的最大瓶颈。更麻烦的是长思维链(CoT)训练会放大典型的 长尾轨迹(Long-tail Trajectories):同一批请求里,有的样本只生成几十/几百 token,有的样本动辄几千 token,最终把集群拖进大量 Bubbles(GPU 空转气泡)。
在 RhymeRL 报告的生产级 RL workload 里,Rollout(generation)可以占到单步迭代时间的 84%–91%(不同任务略有差异)。Seer 也在其表格中给出类似量级:不同 workload 下 rollout 约 63%–87%。 这一节我们聚焦两类系统级解法:它们共同利用一个被长期忽视的事实——训练相邻 step/epoch 的输出“会押韵”:对同一 prompt,新旧策略生成的响应在 token 序列上高度相似,RhymeRL 统计可复用 token 比例可达 75%–95% 两条路线:
1. 投机式 Rollout(Speculative Rollouts):复用历史 token,减少“重复生成”。
2. 切分 + 调度(Divided Rollout / Length-aware Scheduling):把长尾拆开、把负载抹平,减少“等待气泡”。
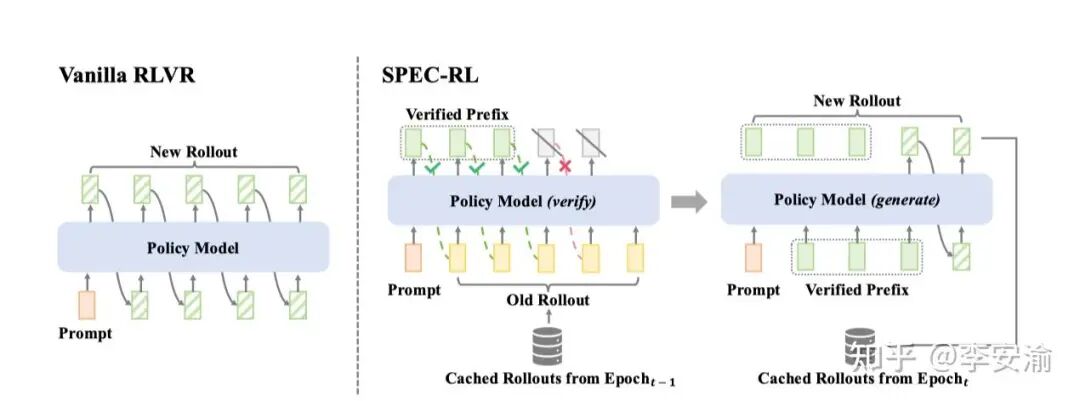
投机采样在 serving 场景叫 speculative decoding;放进 RL 里,本质是:不要每一轮都从 0 生成整条轨迹,而是把历史轨迹当“草稿”,当前策略只做验证+少量续写。 SPEC-RL(Speculative Rollouts)把 speculative decoding 的 draft-and-verify 引入 RL 的 rollout 阶段:它观察到相邻 epoch 的 rollouts 存在大量重叠段,于是复用上一轮轨迹片段作为speculative prefix,再由当前策略并行 verify;一旦遇到第一个不一致的 token,就保留已验证前缀,从该位置开始续写,从而避免大量重复生成,同时保证与当前策略的一致性。 核心机制:草稿与验证(Draft & Verify)
草稿(Draft):上一轮(旧策略)产生的轨迹片段(prefix)。
验证(Verify):当前策略对草稿做并行概率计算,确定可接受的前缀;从第一个 rejection 处继续生成。 SPEC-RL 报告在多个推理/泛化基准上 Rollout time 可降低 2–3×,且不牺牲策略质量;并且它作为“纯 rollout 阶段增强”,可以无缝接入 PPO/GRPO/DAPO 等主流算法。
这里已经在A40上复现了Spec-RL,但是实验结果并没有论文中的好,后面进一步搞清楚了会带来更详细的拆解。并且Spec-RL是基于verl框架进行的开发,所以后面也会进一步学习verl框架。带来更详细的组件解读和代码分析。










