绑定手机号
确认绑定









作者:Alex不在成都
地址:
https://zhuanlan.zhihu.com/p/1991887101671777945
经授权发布,如需转载请联系原作者
关于 pretrain、post train scaling law 的讨论已经持续很久了,一些观点认为 pretrain scaling law 已基本结束,但 gemini 3 又显示出了 pretrain scaling 继续有效。
但不管怎么样,关于下一个范式是什么、怎么做,尚无定论,一些观点说是 online learning,也有说 RL for pretrain。这篇文章下面串联一下最近这些相关の paper。
01 RL 和 pretrain 结合:提升数据利用效率
近期一些文章把 RL 用进 pretrain / midtrain,思路上差不太多,结果上都是显著提升数据效率(小规模验证)。更近一步,对 pretrain 的 NTP 范式下做一些改变,不仅是提升数据利用效率,更可能是突破压缩极限,从而突破 data wall。
https://arxiv.org/pdf/2506.08007
思想是把 NTP 视为可用 RL 训练的推理任务,实验是基于已经训练好的 thinking model,尚未验证 train from scratch。
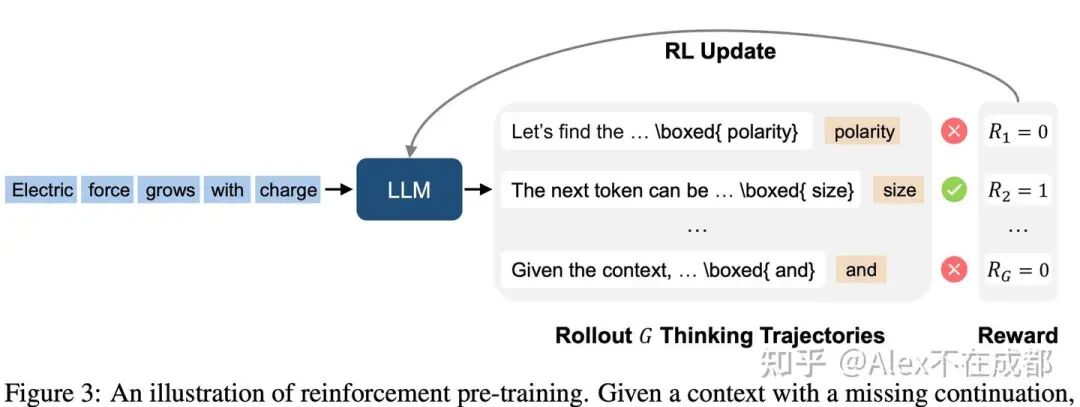
https://arxiv.org/pdf/2509.20186
把一些生成的 thinking model 的 CoT 加到 pretrain 里面,提升数据的利用效率。
实验是 train from scratch,但放在 mid train 也 work。
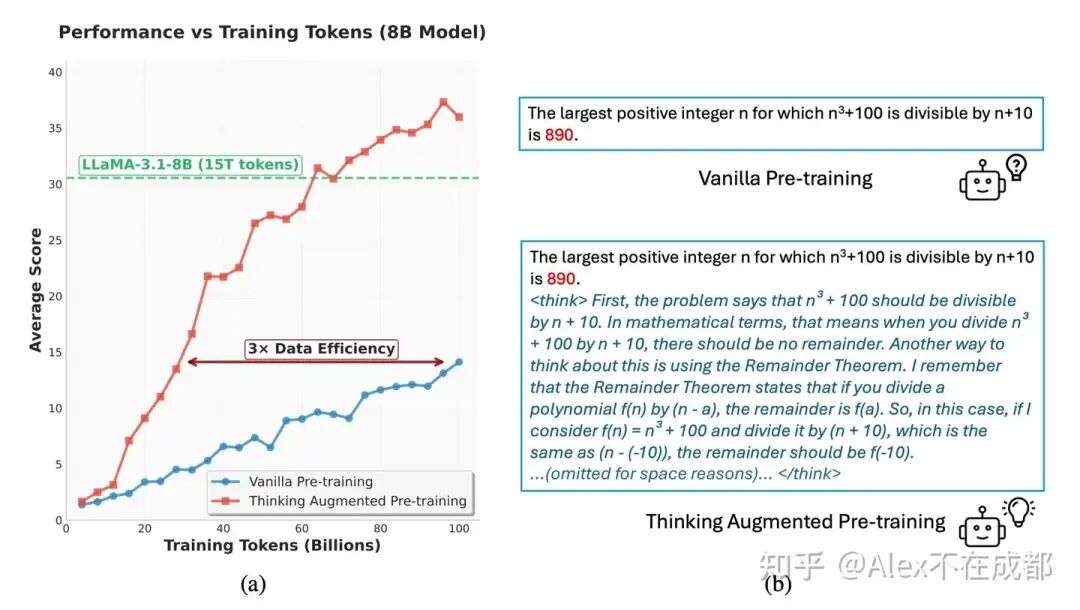
https://arxiv.org/pdf/2510.01265
同上一篇,整体比较类似,也做了放在 mid train 阶段的实验;但并且不依赖外部模型(verifier-free),thinking 轨迹靠 policy model 自力更生。
02 TTT(test time training)
TTT 相比 transformer + NTP,有几个重要的改变:fast weight、learning with inference、O(1) memory,也回答了怎么从 context(短期记忆)变成 fast weight(中期记忆),但 fast weight 如何变 slow weight 不清楚(现在每个 session 的 fast weight 需要 reset)。
TTT 和 linear attn 关系:Dellta Net 是第三代 Linear attn(前两代分别是 context-independent、context-dependent),但 DeltaNet 算是 TTT-v1 的单层特例 。
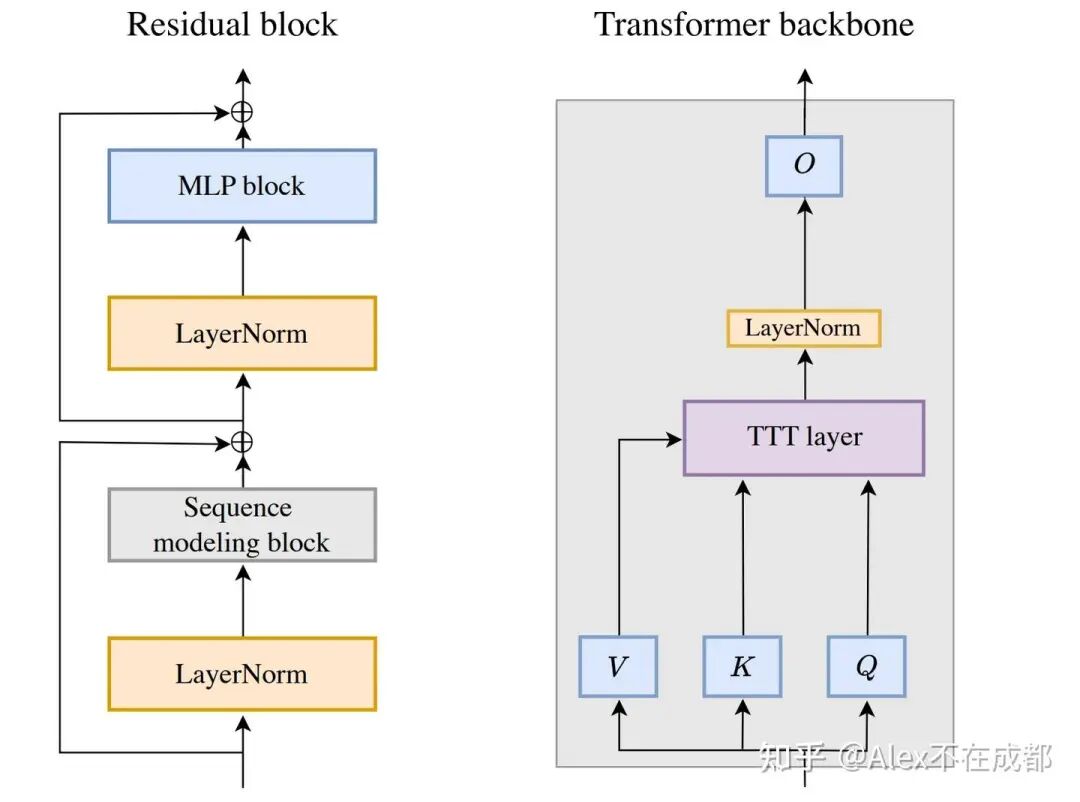
Sun Yu 在 2403 的论文(TTT-v1)https://arxiv.org/abs/2407.04620
相比 naive transformer 的架构,把 self-attention 替换成了一个 MLP。
但多了 inner loop 的训练:在序列维度上,每 mini-bs 个 token 就调用一次 state.train(),会用 去更新 self.model(f 就是 self.model)。

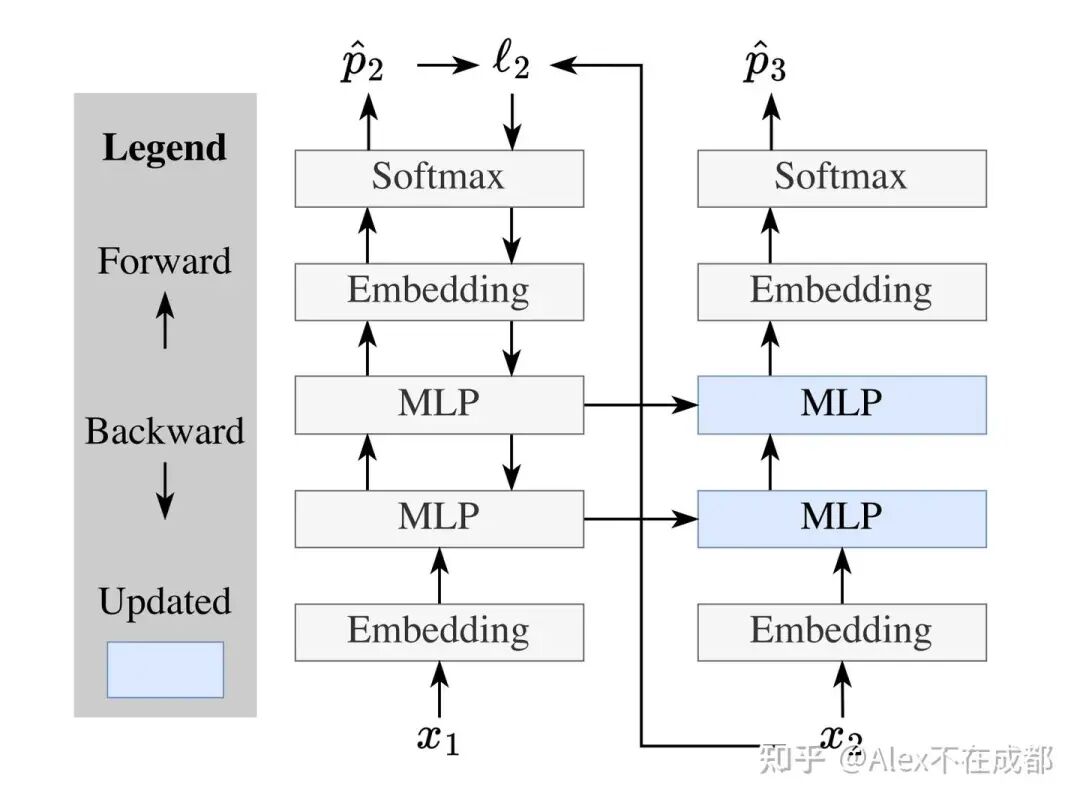
Sun Yu 在2512的论文(TTT-E2E) https://arxiv.org/abs/2512.23675
把 TTT-v1 中的 reconstruction MSE loss 变成 TTT-E2E 中的 NTP loss 了,让 inner 和 outer loop 的训练目标一致。
在这个基础上,未来有希望从 pretrained transformer 继承权重,然后 adapt 到 TTT。
03 LoRA相关
LoRA 作为一个轻量化的微调的优化,能够嫁接在其他技术上降低成本,实现一定程度的 continue learning
Thinking machine 的 tinker,把 LoRA 用于之前的 SFT、RL 范式。
TTTT-v1 把 LoRA 用在 TTT layer 的 MLP 更新上(TTT-v1 在https://arxiv.org/pdf/2512.23675中被归为 TTT-KVB),KVB 的意思是Key-value-binding 。
The Surprising Effectiveness of Test-Time Training for Few-Shot Learning https: //arxiv.org /pdf /2411.07279 这篇名字虽然有 test-time training,但实际用的 LoRA。方法是做题前,先data augmentation 造一些例题,造好后用 LoRA 微调一下模型。
04 Google 的 online learning 相关的论文,整体延续了 TTT 方向
- Titan 和后面的 Miras、Nest learning 都是 GDM 里面 Vahab Mirrokni 团队发表的。
- Vahab Mirrokni 是 gemini 里面一个负责数据和 research 的 VP,也参与 deep think 之类工作(with Quoc V) link。
- GDM 能发的 paper 都是认为 12 个月内很难转化为竞争力的,发出来让社区帮忙加速。
1.Titan
https://research.google/blog/titans-miras-helping-ai-have-long-term-memory/
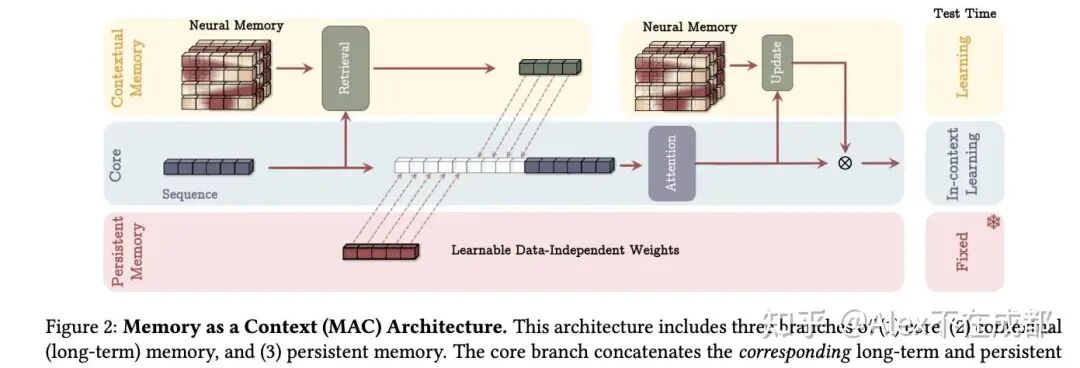
技术原理
核心是上图,三类 memory,最上面一类会在 test time 更新 neural memory 网络的权重,中间 core 表示的和普通 transformer 一样的上下文(用了 sliding window),最下面是在预训练中学到的 硬编码好的一组向量,功能上类似一个隐形的 “System Prompt”。
contextual memory 一行(或叫 neural memory),两个黄色区域,分别是读取和更新记忆。
读的部分:会先通过检索记忆网络输出 。
然后更新记忆:
计算惊奇度: ;k 和 v 同 transformer。
;其中 𝜂 和 𝜃 也是可以学出来的。
,更新 M 中的权重。
core 一行:三种记忆首先在进 attention 前融合一下;然后通过 attention 将前两种记忆中和下(和 TTT-v1 不同之处是保留了 Attention 操作)。
训练方式上同 TTT-v1,相比原始 transformer,多了一个在序列维度的更新内循环。
在序列维度上会 chunk wise 切,chunk 内并行,chunk 间串行更新 memory network(fast weight)。
一个 batch 的数据进来,在序列维度遍历完后、更新好 fast weight 之后,才更新全局权重(slow weight)。
效果上
上图的 MAC 方案,能实现 2M 上下文,且推理内存 O(1),检索能力不受限。
在上图的 MAC 急促上也可以做一些简化,比如拿掉 contextual memory 的读取,只保留更新,效果会稍微差点。
和 DeltaNet 的区别
DeltaNet 是手动写好的纠错公式, 误差⊗kt ;但Titans是通用的反向传播 推理的每一步都运行一个 mini 反传。
memory network 可以用多层 MLP,而不只是一层 Linear。
2. Miras
https://arxiv.org/pdf/2504.13173
尝试用一个统一的数学框架来描述所有的序列架构,包括几个部分:
Memory Architecture(用什么存 fast weight):Vector、Matrix、MLP。
Memory Algorithm:大部分是 gradient descend。
memory write operation:各有各的公式,比如最简单的 。
Attention Bias:更新 fast weight 的 loss 函数,比如 L2。
retention gate:不让参数变动过大,本质是一种正则化,比如 L2。
3. Nested Learning
https://research.google/blog/introducing-nested-learning-a-new-ml-paradigm-for-continual-learning/
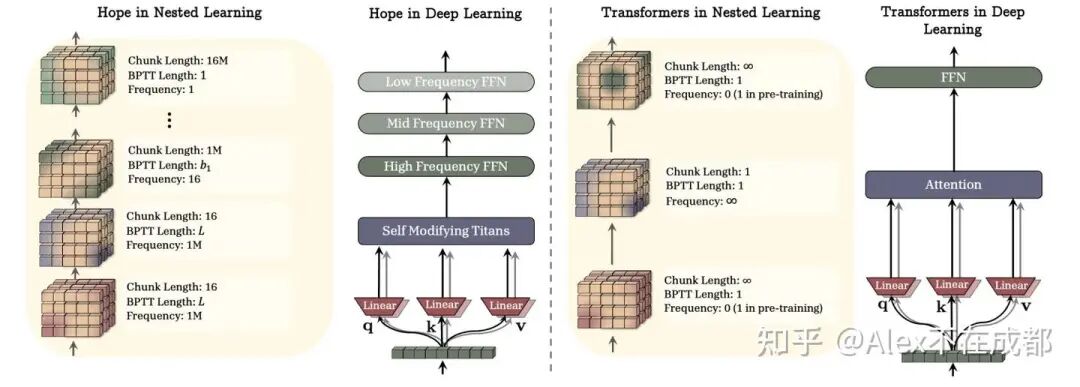
出发点:网络每一层前向等同于一个更新步(i.e. 神经网络残差的公式和梯度下降很像),所以 in-context learning 某种程度上在做梯度下降。
传统 transformer,更新 frequency 和 chunk length 在 attn 和 FFN 之间很割裂,i.e. attn 的激活更新频率很高但是 FFN 权重在训练之后就完全不更新。
Hope 架构下,下面的层更新快 / chunk length 小(短期记忆),然后渐进变化到上面的层更新慢 / chunk length 长(长期记忆)。
Nested Learning 的 HOPE:在 Titan 基础上加了 deep self-referential。
Titan:其中 L 可以人设计好 e.g., L2,但 W_{q,k,v,η,α} 一般 fronzen 的。
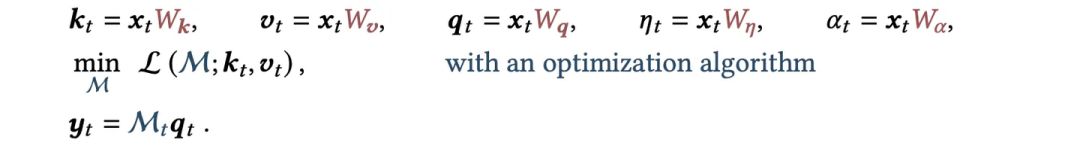
deep self-referential:让「如何记忆」这件事本身,也由一个神经网络算出来的,而不是人工写死的公式,i.e. 进一步让 W_{q,k,v,η,α} 都变成可学习的,被称作 learned optimizer。

05 其他paper
Evo memory
https://arxiv.org/pdf/2511.20857
挂了一帮 GDM 的 senior,Ed H. Chi、Fernando Pereira 都是 VP。
在 ICL 层面,做 action、thinking、self-reflection 来增长经验;可类比 AlphaEvolve,但其是在 ICL 层面利用进化算法。
Retro
https://arxiv.org/pdf/2112.04426
ChatGPT 前的工作,用 小模型+检索 逼近大模型。
最近又被 Gemini pretrain 的负责人 Sebastian Borgeaud 提起,说把检索加到 pretrain 里面端到端可微分训练可能有搞头,但还比较远。
towards a science of scaling agent systems
https://arxiv.org/abs/2512.08296budget-aware tool-use enables effevtive agent scaling
https://arxiv.org/abs/2511.17006










