绑定手机号
确认绑定









作者:少年弈
地址:
https://zhuanlan.zhihu.com/p/1983274112102205322
经授权发布,如需转载请联系原作者
01 序章
纸质日历上的数字已经变成2026了,站在这个新旧交界的时刻上回看一下2025,有许多变化。
回顾一下,我一年中的大多数时间都在工作,而我的工作重心最大的变化是在年中去搞Agent开发了。
大多数名为「感受」的东西如果不用一些文字记录下来,会再也找不到当时的心境。因此有了本文。
一开始标题想叫「2025 Agent开发小结」,但是既然重在记录「感受」,回忆起来这一年在生产环境落地Agent最多的感受是苦涩,于是改成了当下的这个标题。
2025年8月完成了第一个Agent项目初版的开发,带着些许迷茫写了一篇类似开发日志的东西:
Multi-Agent系统初次开发体验分享:https://zhuanlan.zhihu.com/p/1932358285731824266
那这篇文章可能可以算是上篇文章的续集。
这一年写了两个Agent Project,细节我会在本文的后续章节讲。
如果让我写一些概括性的想法,我想我会写下这些:
1. 确定性系统与不确定性系统:与不确定性系统(LLM)打交道是比与确定性系统(code)打交道更为令人苦恼的
2. 模型能力:基模代表你的Agent系统的上限,你的Agent Infra设计代表你的Agent系统的下限。
我司有一款名为TRAE的AI Code IDE, 在无法使用Claude模型以后大量用户反馈代码质量大幅下降,这就是我说的“上限”。如果没有好的Agent Infra,各种糟糕的边界case就是"下限"。
3. 如何调整PE与工具描述:把Agent当成你的用户,提供给它良好的人机交互,站在他的角度想为什么他要这么做。
4. 最好的Agent架构:站在2026年1月的视角,我依然认为Claude Code是当下最好的Agent架构。
5. 人脑与Agent:站在Agent的视角,上下文窗口是宝贵而有限的,内存与硬盘是近乎无限的。这个视角来看上下文窗口像短期记忆,内存与硬盘像长期记忆。
如果没有短期记忆,Agent会像金鱼一样持续做第一步做过的事(如果第一步的事情没有对外界环境产生影响,只是个读操作的话)。上下文管理也像从长期记忆中源源不断地load信息到短期记忆并行动。LLM是大脑,Tool是通过大脑影响外界的工具(手和脚)。
人类思考的过程可以用文本表示,而LLM的训练过程投喂了大量人类世界的文本。因此除了作为一个易用的文本处理工具以外,LLM本身具有决策和思考的能力。
但Agent的实现只能模拟记忆、思考,从工程角度来讲,这与人真正的记忆和思考有较大的差异。
从这个冷门的角度讲,这是导致当下的Agent无法真正实现AGI的原因之一。
02 简单介绍这一年的两个Agent Project
章节开头给个我自己瞎定义的概念:Agent = Context + Loop + Tool
DeepResearch Agent是这个项目立项之初的概念。从我的视角来看它实际上更像Data Analysis Agent,因为信息的来源是部门内,没有接WebSearch,只接了部门内的信息进行Search.
这个Agent的目标在于:如何通过用户的一句话(user query),为用户提供有价值的报告。此外生成报告的报告内容必须真实可信。(不要编造信息、改写原信息,信息来源可追溯、可参考)
写起来无非就是——收集信息 + 生成报告两步。
难点是:用户的诉求可能需要大量信息与数据(比如最近一个月部门内XX的趋势),由于数据量很大,上下文容易爆掉,或者说很难保证上下文窗口的信息都是有价值的。做这个项目的过程中,我的重点始终在于如何较好地往上下文组织信息。
相对容易的点是:不需要太考虑服务稳定性,这种项目生成的报告往往是个参考,所以挂了也没什么。对用户来说只是不能生产一个仅供参考的文档,没什么资损。
使用Agent处理客服工单,而客服的大多数工作流程都被SOP化了,if A ... else B.
比起DeepResearch Agent的自由发挥,你可以先做A再做B,你只是在从现实世界或者数据存储中读取信息,读了就读了,读操作其实不会影响现实世界(也许,毕竟存在观察者效应)。
但这个客服系统的Agent每一步都是会影响现实世界,这导致它不得不SOP化。并且由于会影响真实用户、甚至造成舆论与资损(涉及外呼、退款操作),产品与业务侧对Bad Case的容忍率极低。
这个角度来说它更像Workflow,但产品侧的共识是他们想要个Agent的灵活性,可能这类产品的未来也必将是Agent,于是我就做了个Agent.
它的流程并不复杂,也不需要查询大量信息再交给LLM分析和处理,因此上下文很短。
做它的时间,我大多数时候不是在跟Agent开发相关的打交道,而是在跟各种业务上的Bad Case以及业务场景、服务稳定性打交道。
本着把Agent当成你系统的用户的理念,我认为Project 1中,Agent是数分或者研究员。Project 2中,Agent是客服的角色。
03 关于DeepResearch Agent的回忆
这一章节用流水账写一下我能回忆起的实现细节。
上下文窗口有限,就算有200k的长上下文窗口,上下文窗口内的巨多token也会导致注意力稀释,Agent会变得不那么“听话”。
上下文窗口是很容易因为追加导致膨胀的。在一个Agent Loop中,如果每一轮Loop拼接本轮的tool call request + tool call response, 而不做其他操作,上下文窗口将很快被堆满。
(1)上下文窗口的Cut
Remove: 通常很久之前的行动轨迹是没什么用的(你已经行动完了,并且你知道你行动完了),可以直接Remove掉。
Compact: 利用一个LLM对上下文进行压缩,是有损的。之前做DeepResearch Agent产品坚决不要Compact,因为报告里需要数据原文,会导致原文失真。
Remove规则:在DeepResearch Agent中做了简单的Remove,把已完成的Todo list之前的上下文移除掉;此外,如果到达上下文窗口上限的75%,会强制驱逐最老的Message,直到符合窗口。(会给个“前面的上下文已经被驱逐”的标记)

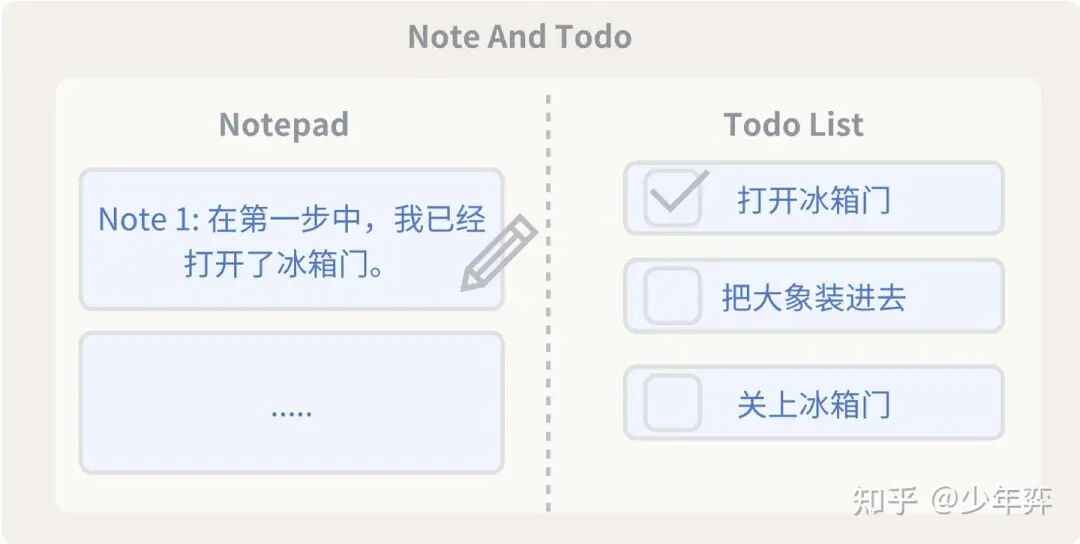
(2)Note & Todo
如上面所说,Remove时会干掉一部分的上下文,但是也不想让Agent以为之前的事情没有做。
Note比较短,相当于一个记忆,让Agent自己记录一下关键信息,以便Agent不会忘记自己做过什么事。
Todo如果不提前规划Todo,多步骤任务Agent会忘了自己要干嘛。有了Todo可以每次完成以后让Agent动态打勾。(此外,即使没有Note,已完成的Todo实际上也可以让Agent假设之前的步骤已经做完了)
其实人也是一样,复杂多步骤的事情边想边做容易忘,提前规划好然后打勾就比较正常。
(3)思考过程
让Agent输出思考过程很重要(并不是说要用think模型,给一个字段让他输出他怎么想的即可)
这样可以发现Agent为什么做了错误的事,然后去调整工具和PE。
当然,一个事实是Agent输出的思考过程不一定是它内部真实的决策路径,但是输出思考过程以后的next action会尽可能匹配它自己输出的思考过程,进行拟合。
在过去的认知里,我以为code执行一般是用来作为计算器帮助Agent统计Sum/Avg/Count,但是做这个Agent的过程中我发现code实际上也很适合处理结构化文本。此外,很多Agent的实现中,会让Agent编写代码来生成excel, ppt,pdf.
在DeepResearch Agent中,我们交付给用户的最终产物是一个报告文档。
文档的信息可能来源于我们Agent运行过程中从各种工具收集的信息。
针对需要copy原文的场景,这里的一个认知是不要让LLM去复读(我说的复读是指——上下文窗口内有一部分A,LLM需要自己输出相同内容的A')。因为复读容易改写内容。
此外,Agent需要自己不停地主动往上下文窗口Load不同的A,然后输出A'。本身会比较耗时。需要多步。
你个较好的实践是,让LLM写代码或者操作工具,把A文件第3-5行的内容,insert到最终报告的7-8行。这样就不会幻觉。
如果A文件是个json,需要在报告中转成结构化文本,那也更适合去写代码操作。
比如:
{
"before_value":"春天",
"after_value":"冬天"
}对于一些固定格式的文本,只需要生成把{before_value}变成{after_value}的代码就可以生成固定句式了
把春天变成冬天。理解了上面的结构化例子,我们很容易联想到HTML网页的生成——除了让LLM直接自己输出HTML文本以外,实际上也很适合通过格式化的代码生成内容,比如重复的一些HTML Tag + 内容。比如编写一段Python代码,开头先拼接header,然后通过字符串拼接各种HTML内容。这里给个例子
# 示例数据(假设来自其他地方的结果)
students=[
{"name":"Alice","score":92},
{"name":"Bob","score":85},
{"name":"Charlie","score":78},
{"name":"Diana","score":88},
]
# HTML 头部
html_parts=[]
html_parts.append("""
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>成绩报告</title>
<style>
body { font-family: Arial, sans-serif; }
table { border-collapse: collapse; width: 50%; }
th, td { border: 1px solid #999; padding: 8px; text-align: center; }
th { background-color: #f0f0f0; }
.high { color: green; }
.low { color: red; }
</style>
</head>
<body>
<h1>学生成绩报告</h1>
<table>
<tr>
<th>姓名</th>
<th>成绩</th>
</tr>
""")
# 使用 for 循环动态生成表格行
forstudentinstudents:
score_class="high"ifstudent["score"]>=85else"low"
html_parts.append(f"""
<tr>
<td>{student['name']}</td>
<td class="{score_class}">{student['score']}</td>
</tr>
""")
# HTML 尾部
html_parts.append("""
</table>
</body>
</html>
""")
# 合并并写入文件
html_content="".join(html_parts)
withopen("report.html","w",encoding="utf-8")asf:
f.write(html_content)
print("HTML 报告已生成:report.html")3. 处理长结构化文本当然,写代码操作文本这件事其实更适合处理结构化文本。通过工具或者code提取非结构化文本的信息只能通过行号+偏移量,结构化文本则很适合让LLM输出代码来处理。
如果你需要对Json和csv文本通过代码进行一些操作,那你需要预先知道Json的格式或者csv内部的格式。
如何知道呢?如果直接让LLM去感知整个大文本,上下文窗口可能会爆。这里一般需要preview一下前几行,就像人写代码处理json或者csv也需要扫一下前几行一样。大多数Agent实现里一般都会提供一个preview工具做这件事。
有时比较头疼的点是前几行和后面的行格式不一样,导致通过preview写出来的代码处理不了后面格式不一样的行。这个没什么太好的解法。人写代码也是大概扫一眼数据格式,然后开始处理,跑了代码发现报错了再修数据或者修代码。当然,人可能大概浏览一遍全文,而不是只看前几行(放到Agent开发里可能需要对整个文件进行抽检,随机看某些行的格式)
csv的预览一般需要你把header列表,行数、列数告诉Agent。另一个头疼的事情是,有时csv内部的cell甚至可能又是个json对象,这样preview实际上应该把cell的类型预览出来,如果是json object,应该把json object的结构也告诉Agent.
除了preview工具,有时确实有需要读取整个文件原文的场景,普遍的Agent实践中会提供个read工具或者view工具把原文load到上下文窗口。当然也不能全部load,上下文窗口很容易就爆了。需要给个允许读取的长度阈值,如果发现过长需要在返回时把结果截断,并且告诉Agent这里被截断了(否则Agent可能认为原文就这些),此外需要给Agent建议,如果发现截断了,通过preview或者通过code操作(就像友好的页面提示框)。
上面反复提到写代码处理结构化文本,那Agent实际必须具有编写代码和执行代码的能力。
具体实现是,这个DeepResearch Agent内部还挂载了一个简单Code Agent作为SubAgent。
Code Agent没什么好说,LLM通过文本生成能力生成code + run code(sandbox),额外提供一个Run Code的的能力即可。
也给了一些其他工具,基本就是照抄Claude Code的SWE bench那篇文章的思想(ls, view, str_replace)
这里实际上有两种实践范式,一个是把run code的能力直接挂给主agent,主agent自己write file的时候本身就可以写代码。另一种就是把run code能力给了subAgent,主agent只给需要子agent处理的任务描述,以及选择一些需要处理的文件发给子agent。
在一开始的设计中,对deepresearch agent来说写代码是次要能力。但是随着我发现代码能力很适合处理结构化文本,我觉得run code与生成code的能力还是应该给主agent,否则主agent可能很难想到要使用code subagent?(你需要在提示词中包含所有的case,但如果主agent自己可以run code,也许他自己可以发现一些场景去写代码并执行)
但是在意识到这一点的时候我已经被安排去做Project 2(那个客服Agent)了,因此它的现状依然是code agent作为子agent在使用。
此外,如果生成Python代码,Code Agent一定要有自己pip install的能力。因为很多时候生成的代码里的package是你基础镜像里没有的。
我之前的文章里翻译过Claude Code的很多博客,一个重要的概念就是给Agent一台计算机。
给程序员一个计算机可以完成工作,那给Agent一台计算机也可以完成大部分工作。
在基模更新迭代快的年代,与其反复去琢磨某个模型上某种特定的提示能起到最好的效果,不如花时间给Agent一套通用的Infra,赋予Agent灵活的自行决策能力。这样基模升级和迭代的时候,我们的Infra依然是通用的。
如Anthropic所说,File System实际上是对Agent自主加载上下文的一种抽象。(允许Agent自行探索)
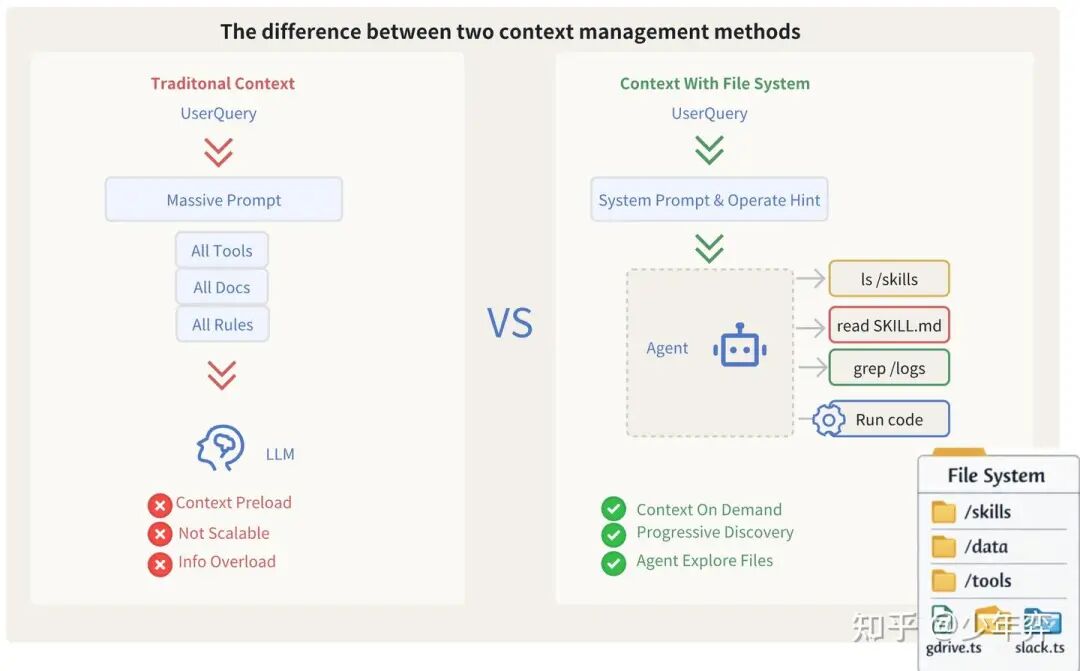
File System也是一个给Agent的Infra
最基础的文件系统提供Write和Read能力即可,Write可以是LLM主动Write,也可能是工具response被打包进一个文件里。
LLM一次通常无法生成太长的文本,如果长报告,需要多次生成,一般而言,这种文件系统还需要提供追加写的能力。
过长的Tool Response通常也需要优先写成一个文件,而不是直接添加进上下文,再由LLM选择部分读、或编写代码裁剪或处理。
LLM输出的结果总要通过一些硬编码rule验证,验证不通过就给个错误信息react回去。(就像给人一个错误提示告诉他表单里xx没填一样)
甚至可以用LLM as Judge模糊给个匹配标准,评判一下输出是否合适。
04 苦涩的客服系统Agent
如前文所说,实现客服系统Agent的过程中,我的大部分时间都花在与Agent无关的事情上,因此我使用了「苦涩」一词来描述这一项目历程。
在实现中我需要对接不少已有的老系统接口(工单、订单),他们本身不适合Agent直接生成参数并调用。
下游RPC接口需要复杂的参数,根本不适合LLM生成。(人也不能看一眼巨长的文本,然后准确地复述出来)
对于工程上我可以拿到的参数,我在代码里对不需要动态生成的参数进行了组装,减少需要LLM自由生成的参数。
有的参数可以从其他系统拿到,并且与下游接口参数的结构相同,我直接封装到一个文件里,让agent只生成文件名的引用。调用时把文件内容unmarshal过去。
为了把这件事合理化,我安慰自己就像人在电脑上拖拽文件从文件夹A到文件夹B一样。或者就像在Ctrl + C, Ctrl + V一样。
在实践过程中,我发现可能的确存在通用的Agent框架,上下文管理方式固定,文件系统固定,Code Run能力固定。剩下的不过是给予不同的知识和工具。
我想这也是Claude Code为什么在推SDK和Skills的原因——他们发现自己的Agent能力足够强大,足够扩展给更多场景。
在做这个客服工单Agent的过程中,让隔壁团队把某个工具参数的推理过程也封装成了SubAgent。
我认为实际上是不必要的,如同Antropic团队Blog里的观点,只有需要并行的长耗时的、或者会严重污染主Agent上下文的case适合抽成SubAgent.
这里我还想提一点,最好给SubAgent分配任务的所需的参数尽可能简单,比如主Agent一个任务描述就能让SubAgent开始框框跑。但是这个不合理的SubAgent让我甚至需要把主Agent的大部分上下文信息都给SubAgent(说明这件事本身就是主Agent做比较合理)
但是需要提的一点是,承担外呼、退款这种带有业务语义的东西的责任是很heavy的,司内的订单系统有多套,这导致这些工具适配代码实际上写起来很dirty,与业务的强耦合导致又需要做大量工程封装。这个角度下让隔壁团队去搞SubAgent实际上又能降低我大量的心智负担。
因此我也没有想清楚这种分工与实现是否是合理的,可能需要交给时间验证。
我的Agent项目在司内的K8s基建上跑,没有使用特化的基建能力。K8s天然适合无状态服务,这导致我需要处理K8s基建上的众多有状态服务问题。
比较常见的一个思路是每一轮循环在一些固定的检查点都进行checkpoint, 这样如果pod down掉,用其他pod重新拉起任务的时候,从checkpoint继续执行即可。
一个case是,发起写请求前checkpoint了一次,但是下游执行过程也是长耗时的,等待的过程中pod down掉了。
当任务重新拉起时,不希望重新进行写操作。显而易见的是是外呼操作、退款操作这样的写操作都是不希望二次重放执行的(虽然他们自己会做幂等)。
所以这里把外呼这种长耗时任务做成了callback。等待外呼执行时我的主Agent的状态被save到了KV存储中,等到结果回来再load and parse callback。
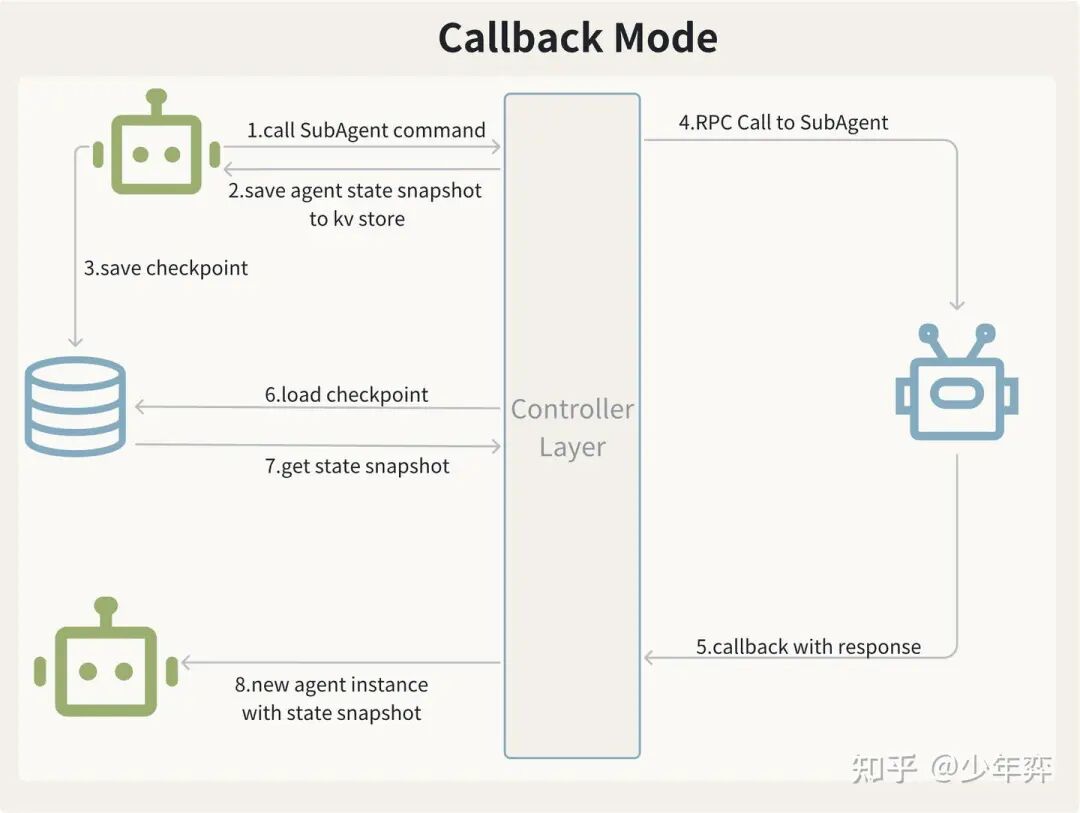
我认为这样有两个好处:
(1)pod中正在运行的任务会大幅减少(可能大多数任务都在等待callback回来或者等待客服继续点击某个交互)这样受pod迁移影响的少。需要通过定时任务巡检再拉起的也少。
(2)重新拉起任务时,发现已经发起了对下游的调用,优先扫描db里有没有已经回来的callback,如果没有,继续等待。
如果下游始终没有callback回来,到达超时时间后,我有一个定时扫描的任务会把对应的任务状态设置为失败。
在这个客服的Agent中,希望能对Agent的行为进行强干预。
一些操作外呼、解封、退款并不希望给打断(给用户的电话打了一半掐了其实很恶劣),但是客服在这些子任务执行过程中可能点击了暂停。那只能暂时标记一个逻辑暂停(pausing), 等子任务callback回来以后再真正地暂停任务(paused, 实际上是一种延迟的暂停),那么在子任务运行期间期间收到的指令都需要排队。
我觉得这个状态机的复杂度来源于这个「延迟与排队」,这让大多数指令不是立刻生效的,如果这些指令可以立刻生效的一定没有这么令人头大,它们是需要在某个时间点延迟感知的。
此外,某种状态下一些指令需要忽略,某种状态下一些指令需要比其他指令更优先感知,这导致我构造了一个苦涩的状态机。
构造这个状态机令我感到头痛,这时候我会经常与AI聊天缓解我的烦闷。(毕竟你的朋友可能并不想听你讲完这一大坨状态机和代码)
我读过一些开源的Agent实现,但他们似乎没有面临我遇到的问题。
AI总是建议我去参考市面上一些成熟的Workflow系统·,并且提醒我这可能和我面对的事件与状态语义更为相似。
Deepresearch Agent处理的信息是相对不变的,但是Agent处理的客服工单以及工单关联的信息是会一直变的。
比如订单,用户可能自己操作退款了。要么客服自己在Agent执行过程中做了一些事,手动退款了(你无法禁止它,因为订单属于外部的东西),或者Agent执行过程中,用户来辱骂了(离谱),或者客服自己主动去外呼用户了。
对于这些外部的信息变更,要么监听事件,要么去定时轮询新状态。
如果选择监听事件,订单、外呼这些系统属于其他部门,过于繁杂。相当于订单工单在我agent系统都存了一份最新的快照,第一可能有一致性问题,第二数据量也很大。此外,监听过多事件可能给我带来巨额的消费压力。
因此这里我在主Agent每轮Loop中,每次调用LLM思考前都会拉一下工单和订单的最新信息(QPS可控,我觉得跟人类客服刷页面的次数也差不多)
值得一提的是,工单的操作日志像外部世界的客观事实,如果客服自己已经打电话询问商家是否可以退款,我们的Agent就不会再去询问商家。
工单日志可能也是对Agent的一种兜底机制,即使Agent对于已经做过的事没有checkpoint,导致恢复时对这件事的记忆丢失了(就像没有存档游戏就闪退一样),工单日志里的客观事实也会导致Agent不会重复去做一件事。
这可能也符合现实里多个客服处理同一个工单时的情况,优先参考工单日志看看过去做过哪些事情。
实现过程中我也并非规避所有事件的监听。
这里有一些场景,比如用户一开始的诉求是退款,后来Agent执行过程中用户发起了留言,诉求变成了改期。
那我们的Agent实际上需要源源不断地接收外部事件,修正自身行为。收到该类事件会在安全的检查点重新思考,如果发现诉求变了,那对应上下文里的知识也要变(退款的业务场景知识和改期是不一样的)
如前面说的,这里也需要排队。长耗时的子任务无法打断,此时只能让外部事件先排队,等到子任务结束再去做检查。比如外呼完用户了再来通过消费事件判定要不要换一下知识。
在实现中,Agent的内部状态需要维护一下读到哪个事件offset了,如果pod迁移导致Agent重新拉起,需要从旧的未读事件开始读。
上面的用户留言事件例子中,这个事件的作用是改变Agent的上下文。还有一些外部事件会直接导致任务失败、暂停、结束。(是的,客服在页面点击暂停也被我当成了一个事件)
真实世界的一切都是瞬息万变的。
对于Deepresearch Agent你大多数时候不会想干预他,不论它规划出了多么不合理的路径,只要不影响最终结果,你等他自己跑完就好。
但是对于生产环境的工单、订单,如果执行路径错了,你需要强干预他。
除了上面说的暂停以外,在一个包含订单的业务场景中,产品强诉求,有个卡点可以卡住,让人工确认Agent规划出来的下一步,如果觉得不合理就去修改下一步。
这实际上会极大影响客服的处理效率,但业务对于Bad Case的容忍程度实在太低。
关于修改下一步,我只能硬写了一段PE拼接到上下文中:
resultText:="客服要求修改todo list,指定第"+stepIdVal.GetValue()+"步为: "+selectOptionVal.GetValue()+
"\n<system_hint>你可以尽可能地认为客服要求的修改执行计划是符合实际情况的,尽可能地按照指定步骤去修改要求修改的todo项,并且合理地修改next_action,"+
"除此之外,你还应该根据实际情况推断并更新后续的todo项。"+
"\n如果确实不符合实际情况,你可以选择使用quit工具(succeed=false)来终止任务。"+
"\n请不要修改next_action为xxx, 如果你认为确实有必要这么做,请使用quit工具(succeed=false)然后说明原因并退出。</system_hint>"指导Agent行动的知识有强业务语义,是从外部系统获取的,但是产品又希望Agent只在一部分情况下让知识指导行动,另一部分下随着我们自己的PE行动。
这个知识也不是我们能随便改的(其他外部系统还在用)。
外部系统的知识和我们的PE甚至是冲突的,这导致Agent执行过程中面对冲突的部分左右横跳。
不得已之下我只能写了这么一段PE
以下规则永久废止:以下规则永久废止:
1. xxxxx
2. yyyyy
替代规则
1. aaaaa
2. bbbbb有时SubAgent执行过程中也需要问客服一些问题,比如部分退款场景下,推理订单退款金额失败了,需要询问客服到退百分之多少。
我的主Agent不想感知这些东西(我感觉并没有必要),因此对于这些问题和交互,我有一个Proxy层,对于不需要让主Agent感知的事情,SubAgent自己通过Proxy直接转给了UI Layer,不经手我Runtime层的主agent。
只有需要主Agent感知的东西,才会通过proxy转给runtime层。
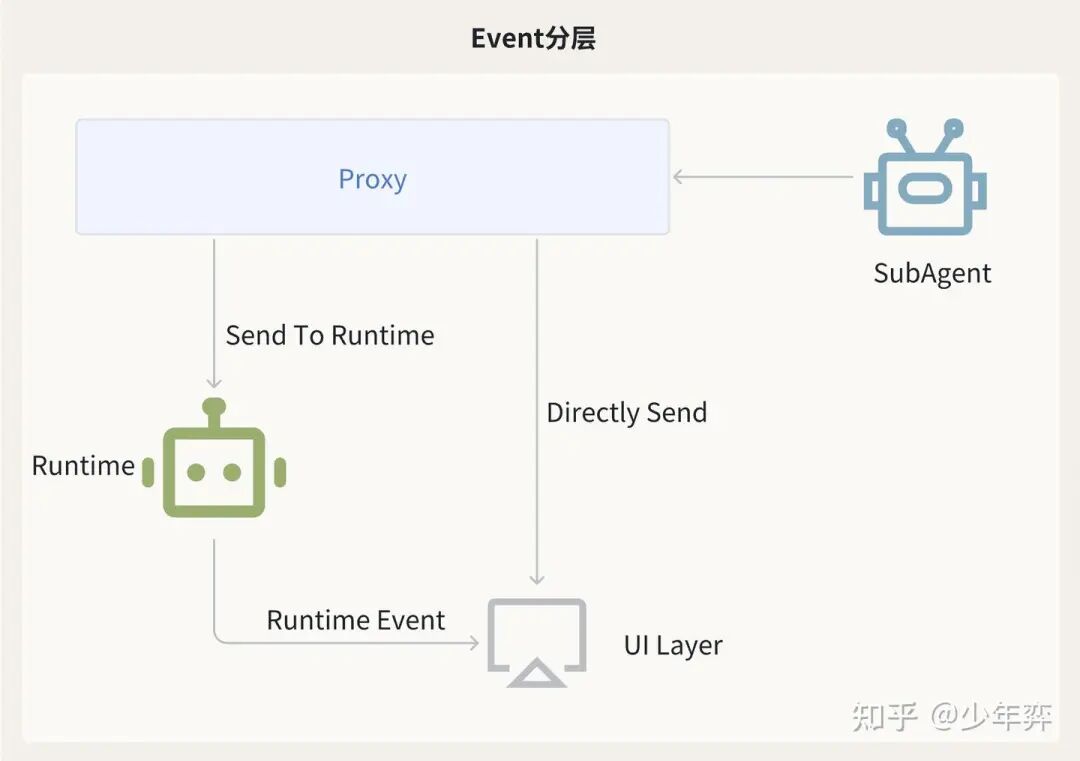
此外, SubAgent自己会推送一些酷炫的UI效果给前端(实际就是他的执行进度),让看页面的人不要焦虑。这部分我的主agent也不想感知,也是Proxy Layer直接转给UI Layer.
工具list过多时,会存在工具选择困难问题,以及工具描述上下文太长的问题。这个Claude Code给的实践是把知识和工具也让Agent自行去探索(Skills与Advance Tool那两篇文章)。
Dynamic Agent是另一种实践,在new一个Agent的时候根据任务种类动态不同召回不同的工具,只携带必要的工具操作。
我认为不论是Skills还是Dynamic Agent都适合用户的开放Query。
但客服工单Agent这个场景下,Query是封闭和可枚举的。每个工单都有不同的标签,标签对应不同的场景。第一场景是可枚举的,每个场景需要的tool都是固定的,这种情况直接让标签对应不同的工具list + prompt即可,这也是我前面提到的这个项目是个配置化Agent。
05 写在最后
至此,我讲完了我2025下半年经手的两个Agent项目。
回忆起来,DeepResearch Agent是我比较喜欢的一个项目,在构造它的过程中我学到了许多新知识,并且因为它不和业务指标挂钩,让我可以随意地去动它,去验证我的一些想法。它像个聪明的研究员,虽然有时候会搞砸事情,但是也会给你意想不到的结果。
而在第二个工单Agent项目中我遇到了生产环境的很多问题,业务对Bad Case的容忍程度极低也让我有点畏手畏脚,我没有在这个项目里探索新的东西,只是写着各种处理边界情况的代码,保证它稳定运行。(虽然LLM本身就是不确定的)
两个项目的苦涩并不是同一种味道的苦涩。
DeepResearch Agent的苦涩在于如何在复杂多变的用户Query下帮助用户解决问题(甚至有时候用户的Query只有很短的一句话,但是依然许愿通过一句话解决问题),有时用户会发起一个较为复杂的任务,此时需要处理长上下文问题,并在效果和灵活性之间做一些均衡。
客服场景Agent的苦涩可能在于生产环境的压力。
不过压力与困难并不都是坏事,总是做容易的事也令人感到兴致缺缺。困难与有挑战的事总是令人兴奋的。
不足是,这两个项目开发期间都是倒排,上线时间非常激进,追求快速落地。如今都没有补足完整的评测体系,很多时候依赖于人工抽检与打标,或者简单的LLM as Judge。希望2026我能花一点时间,补足一个完整而稳妥的Agent评测体系。










