绑定手机号
获取验证码
确认绑定
提问
0/255
提问
订阅开课提醒需关注服务号
×
首页
直播
合辑
专场
智东西
回答成功
知道了
扫码关注智猩猩服务号登录
请使用微信扫描二维码
扫描二维码分享给微信好友
您已订阅成功,有新课程,我们将第一时间提醒您。
知道了
发送提问成功
回答可在
“我的——我的提问”中查看
知道了
失败
欢迎来智东西
登录
免费注册
关注我们
智东西
车东西
芯东西
智猩猩
智东西
车东西
芯东西
智猩猩
智猩猩
智猩猩官网
智猩猩小程序
线下大会
预告
公开课
讲座
专场
AI技术
全部干货
等价去除残差连接!图解RMNet重参数化模型剪枝新方法
华为轻量级神经网络架构GhostNet再升级,G-GhostNet在GPU上大显身手!
华科Ð提出首个用于伪装实例分割的一阶段Transformer的框架OSFormer!代码已开源!
ECCV 2022 Oral | 涨点神器!AutoMix:自反馈学习的Mixup训练框架
Poseur:你以为我是姿态估计,其实是目标检测哒
汇集YOLO系列所有算法,YOLOU算法实现库来啦
只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
BEVDet:多摄像头在BEV视图的3-D目标检测方法
更深和更宽的Transformer,哪个更好?NUS团队:我站Wider!
BossNAS: 基于CNN-Transformer混合搜索空间的自监督NAS算法
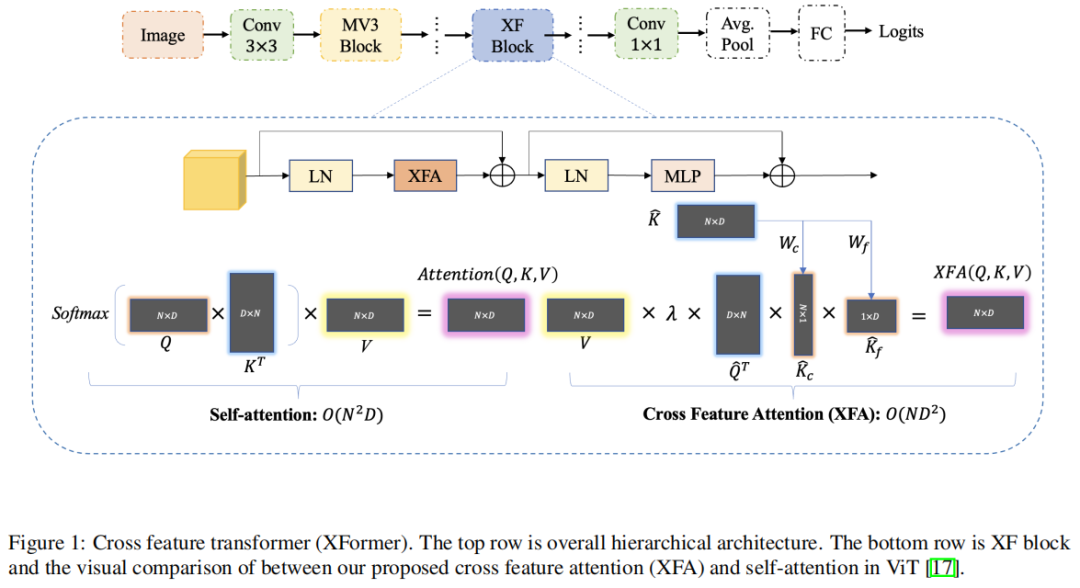
三星提出CNN-ViT混合模型XFormer,超越MobileViT、DeiT、MobileNet
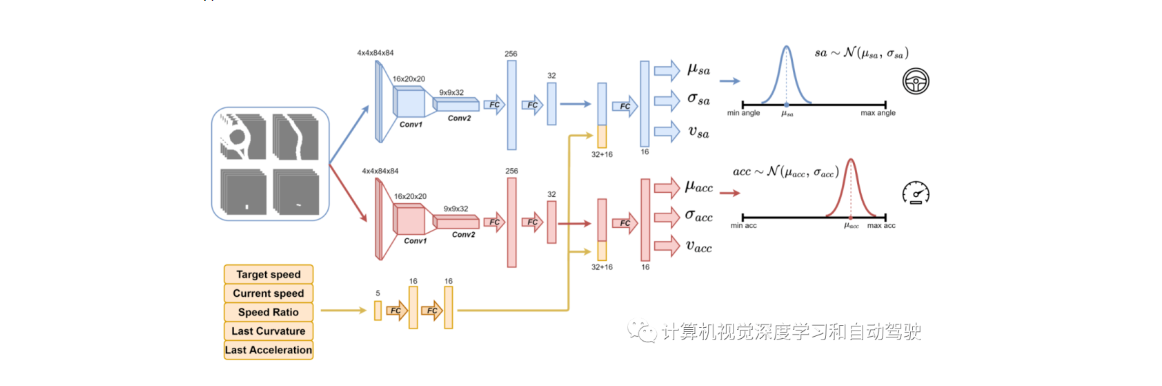
深度强化学习处理真实世界的自动驾驶
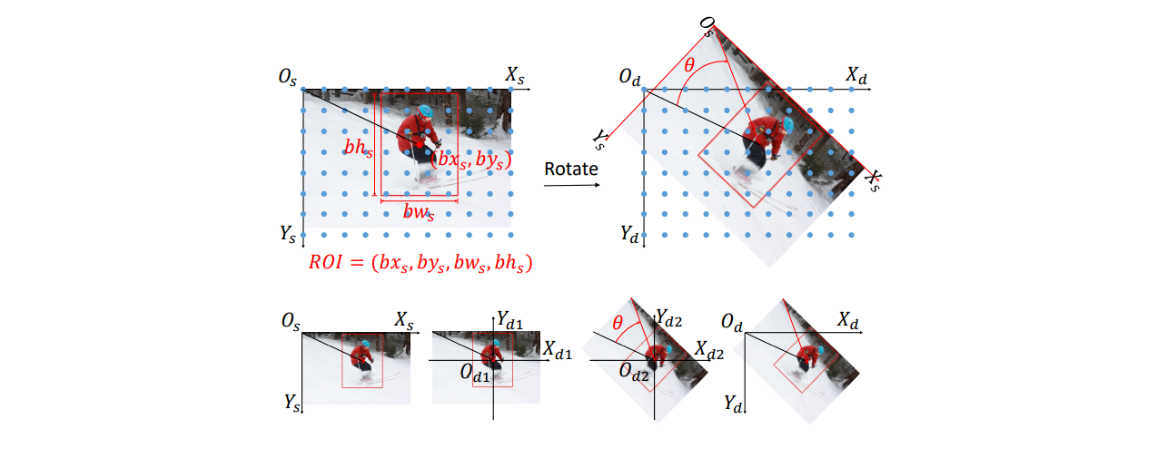
姿态估计经典论文 | 魔鬼藏在细节里,使用无偏数据处理UDP
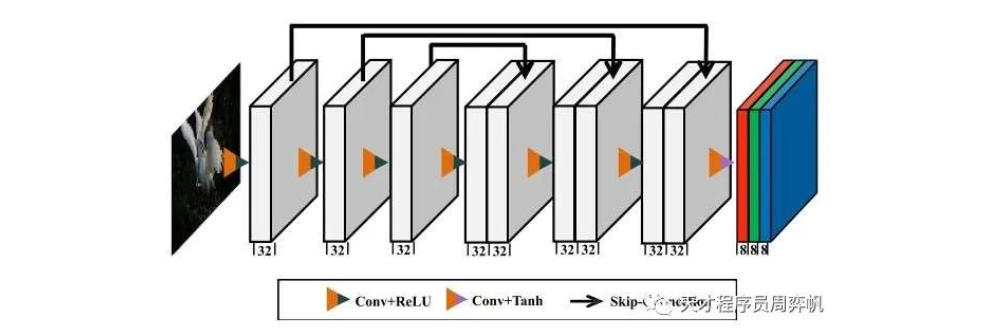
Zero-DCE : 0.002秒点亮一张照片
小姐姐终于开口了!AI杀疯了!
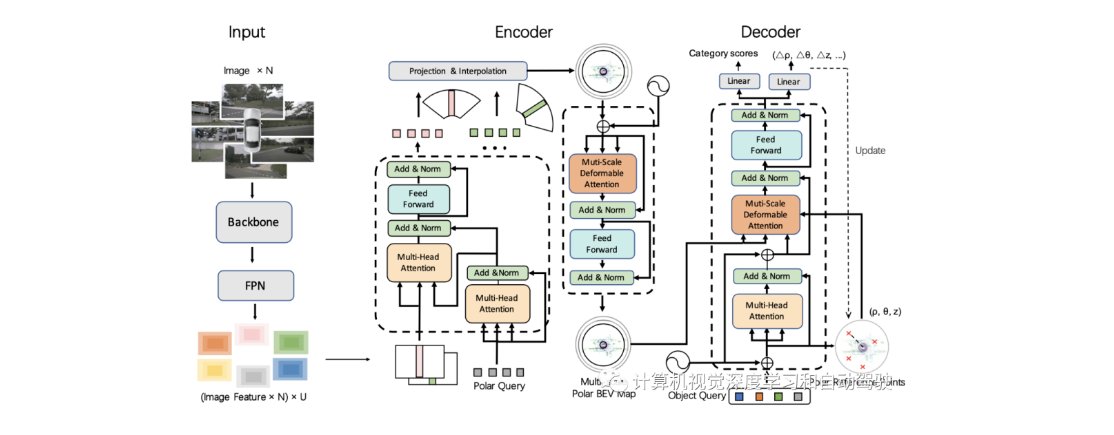
复旦提出PolarFormer,用极transformer实现多摄像头3D目标检测!
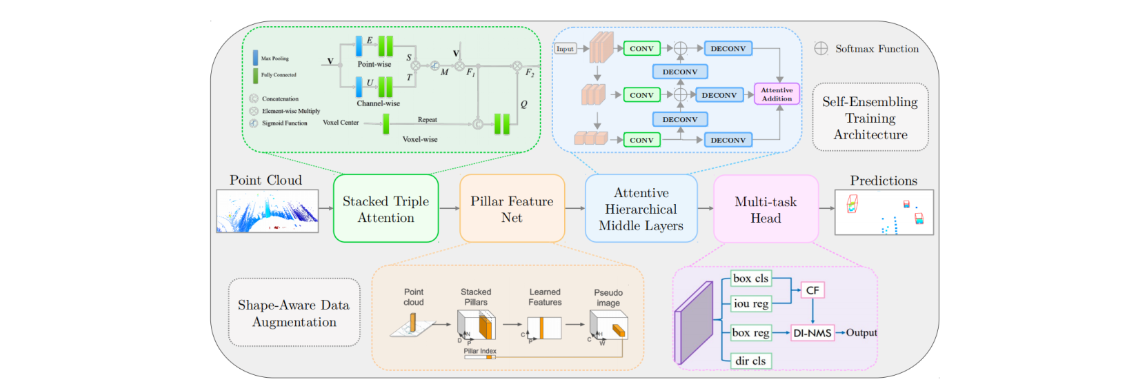
SE-ProPillars | 一个具备鲁棒性的实时3D目标检测方法
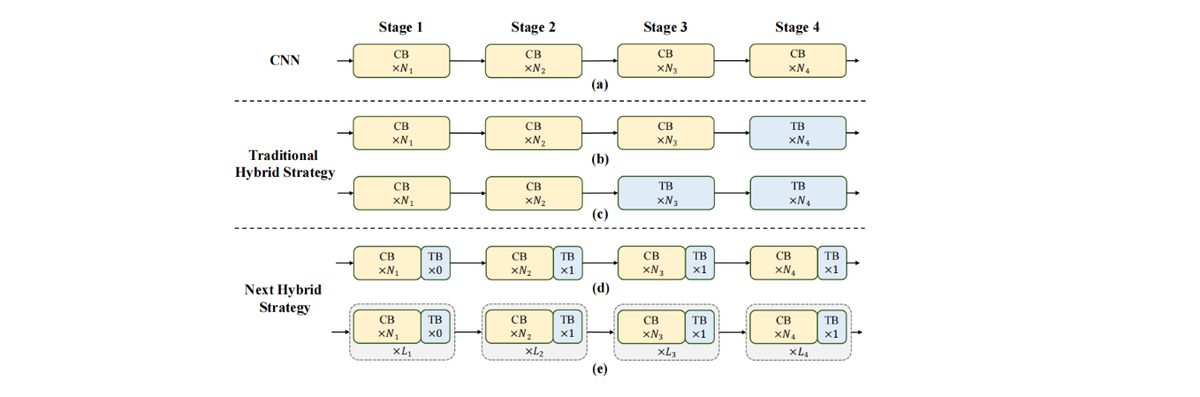
Transformer 落地出现 | Next-ViT实现工业TensorRT实时落地,超越ResNet、CSWin
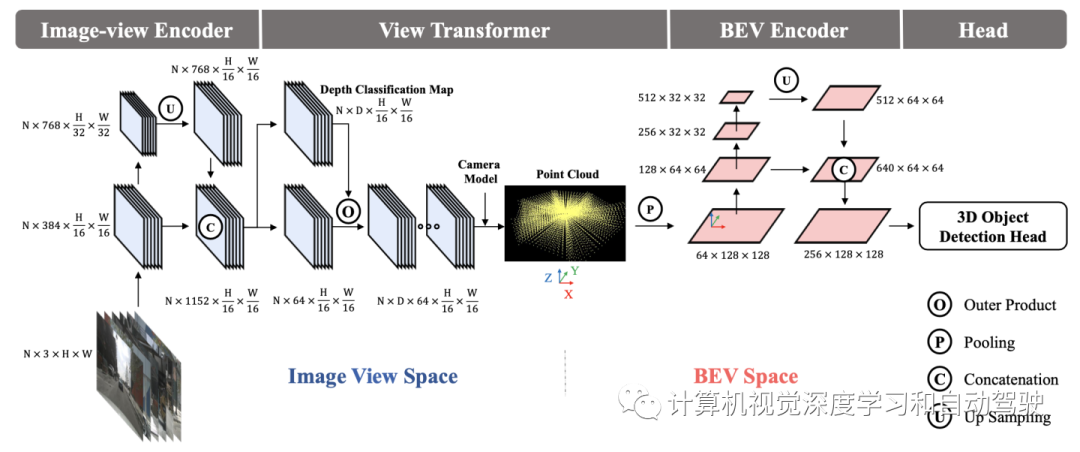
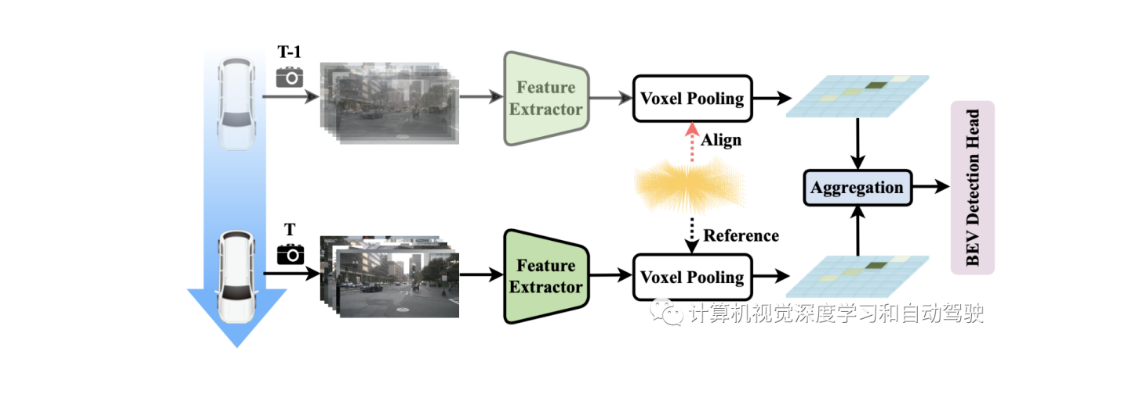
用于摄像头的BEV 3D目标检测!旷视提出BEVDepth获取可靠深度值
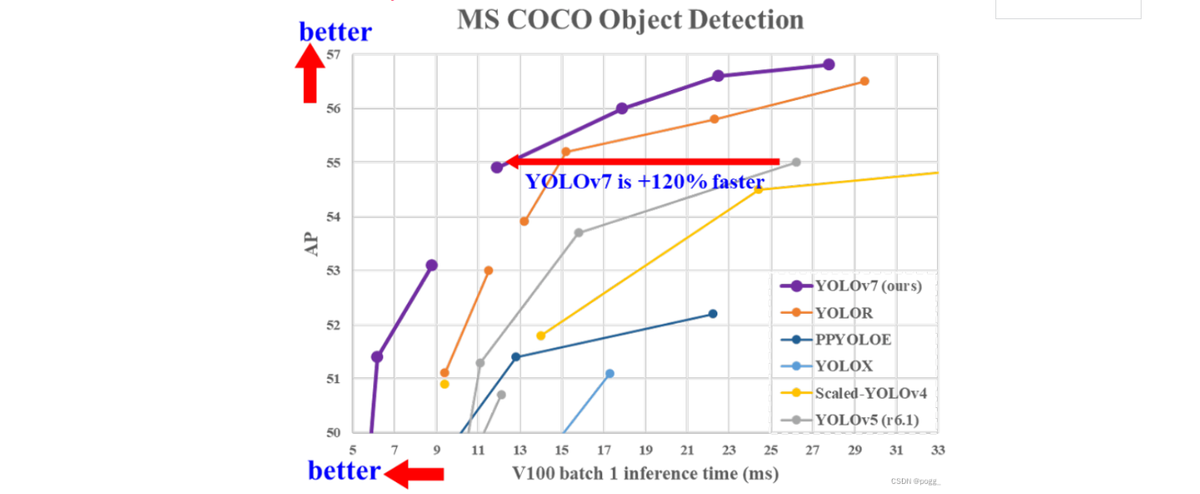
YOLOv7官方开源 ,精度速度超越所有YOLO
上一页
1
2
3
4
5
6
7
下一页





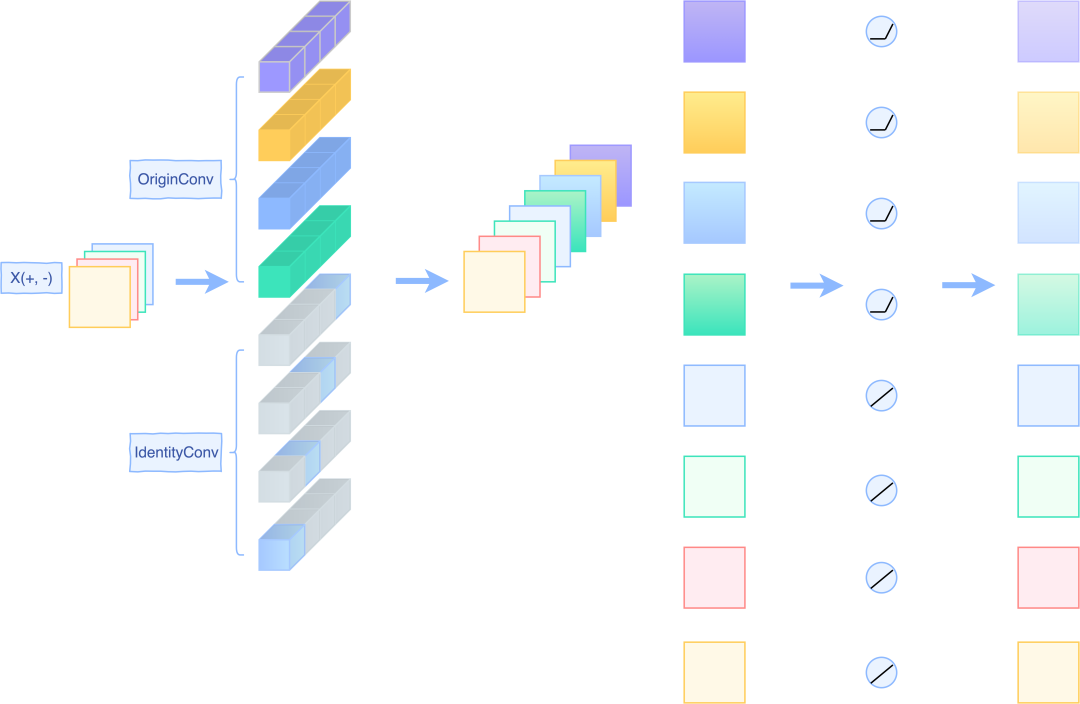
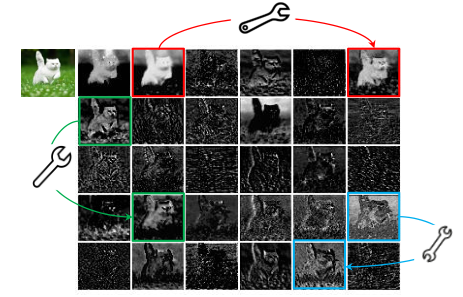
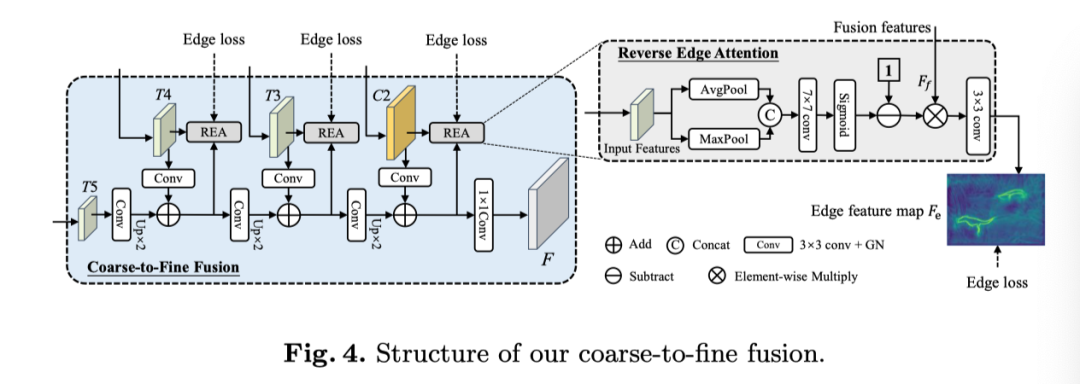

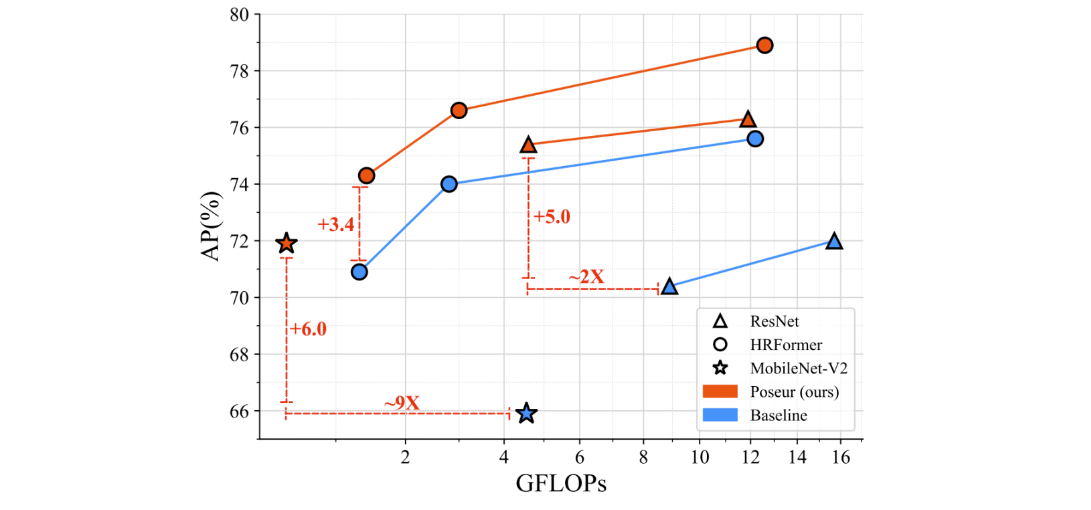









 上一页
上一页
